Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Architettura Amazon SageMaker Debugger
Questo argomento illustra una panoramica di alto livello del flusso di lavoro di Amazon SageMaker Debugger.
Debugger supporta la funzionalità di profilazione per l'ottimizzazione delle prestazioni per identificare problemi di calcolo, come colli di bottiglia e sottoutilizzo del sistema, e per contribuire a ottimizzare l'utilizzo delle risorse hardware su larga scala.
La funzionalità di debug di Debugger per l'ottimizzazione dei modelli consiste nell'analisi dei problemi di addestramento non convergenti che possono insorgere riducendo al minimo le funzioni di perdita utilizzando algoritmi di ottimizzazione, come la discesa del gradiente e le sue variazioni.
Il diagramma seguente mostra l'architettura di Debugger. SageMaker I blocchi con linee di limite in grassetto sono ciò che Debugger riesce ad analizzare durante il processo di addestramento.
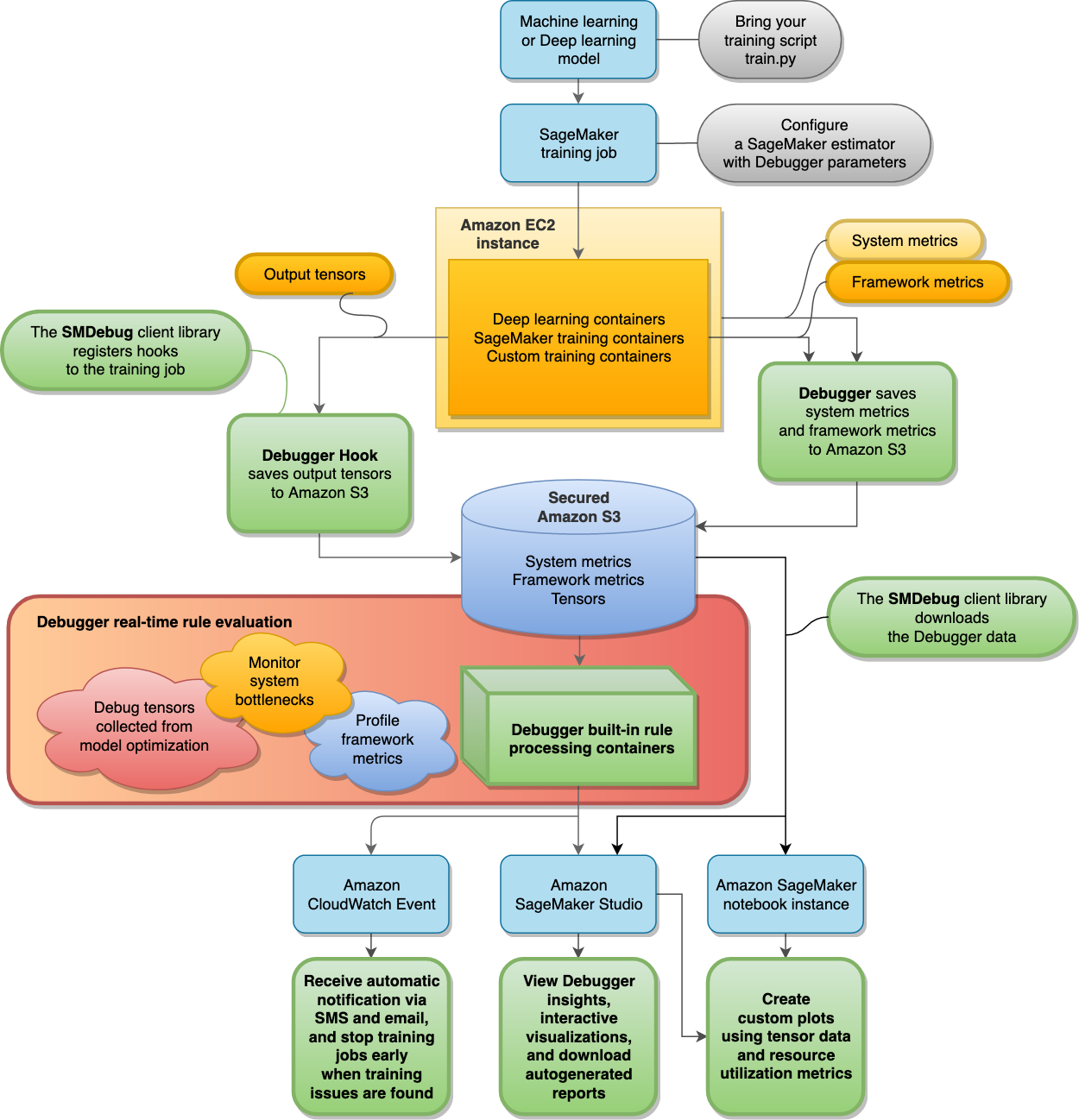
Debugger archivia i seguenti dati dei tuoi processi di addestramento nel tuo bucket Amazon S3 sicuro:
-
Tensori di output: raccolte di scalari e parametri del modello che vengono continuamente aggiornati durante i passaggi avanti e indietro durante l'addestramento dei modelli ML. I tensori di output includono valori scalari (precisione e perdita) e matrici (pesi, gradienti, livelli di input e livelli di output).
Nota
Per impostazione predefinita, Debugger monitora ed esegue il debug dei lavori di SageMaker formazione senza alcun parametro configurato negli estimatori AI. Debugger-specific SageMaker Debugger raccoglie i parametri di sistema ogni 500 millisecondi e i tensori di output di base (output scalari come perdita e precisione) ogni 500 fasi. Inoltre, esegue la regola
ProfilerReportper analizzare i parametri di sistema e aggregare i pannelli di controllo delle informazioni approfondite di Studio Debugger e un report di profilazione. Debugger salva i dati di output nel bucket Amazon S3 sicuro.
Le regole di Debugger integrate vengono eseguite sui container di elaborazione, progettati per valutare i modelli di machine learning elaborando i dati di addestramento raccolti nel bucket S3 (consulta Dati di processo e modelli di valutazione). Le regole integrate sono completamente gestite da Debugger. Puoi inoltre creare le tue regole personalizzate in base al tuo modello per controllare eventuali problemi che desideri monitorare.
