Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
SageMaker Report interattivo del debugger
Ricevi report di profilazione generati automaticamente da Debugger. Il report di Debugger fornisce informazioni dettagliate sui processi di addestramento e fornisce consigli per migliorare le prestazioni del modello. La seguente schermata mostra un collage del report di profilazione di Debugger. Per ulteriori informazioni, consulta SageMaker Report di profilazione del debugger.
Nota
Puoi scaricare i report di Debugger mentre il processo di addestramento è in corso o al termine del processo. Durante l’addestramento, Debugger aggiorna contemporaneamente il report in base allo stato di valutazione delle regole correnti. Puoi scaricare un report di Debugger completo solo dopo il completamento del processo di addestramento.
Importante
Nei report, i grafici e le raccomandazioni sono forniti a scopo informativo e non sono definitivi. Sei responsabile della tua valutazione indipendente delle informazioni.
SageMaker Report di profilazione del debugger
Per qualsiasi processo di SageMaker formazione, la ProfilerReport regola SageMaker Debugger richiama tutte le regole di monitoraggio e profilazione e aggrega l'analisi delle regole in un rapporto completo. Seguendo questa guida, scarica il report utilizzando l'SDK Amazon SageMaker Python
Importante
Nel report, i grafici e le raccomandazioni sono forniti a scopo informativo e non sono definitivi. Sei responsabile della tua valutazione indipendente delle informazioni.
Scarica il report di profilazione del Debugger SageMaker
Scarica il report di profilazione del SageMaker Debugger mentre il processo di formazione è in esecuzione o al termine del processo utilizzando Amazon SageMaker Python SDK
Nota
Per ottenere il report di profilazione generato da SageMaker Debugger, devi utilizzare la regola integrata offerta da Debugger. ProfilerReport SageMaker Per attivare la regola con il tuo processo di addestramento, consulta Configurazione delle regole integrate del profiler.
Suggerimento
Puoi anche scaricare il rapporto con un solo clic nella dashboard di Studio Debugger Insights. SageMaker Per scaricare il report non è richiesto alcuno script aggiuntivo. Per scoprire come scaricare il report da Studio, consulta Apri il pannello di controllo di Amazon SageMaker Debugger Insights.

Nota
Se hai iniziato il processo di addestramento senza configurare i parametri specifici di Debugger, Debugger genera il report solo in base alle regole di monitoraggio del sistema, poiché i parametri di Debugger non sono configurati per salvare i parametri del framework. Per abilitare la profilazione delle metriche del framework e ricevere un rapporto esteso sulla profilazione del Debugger, configura il parametro durante la creazione o l'aggiornamento degli estimatori. profiler_config SageMaker
Per informazioni su come configurare il parametro profiler_config prima di iniziare un processo di addestramento, consulta Configurazione per la profilazione del framework.
Per aggiornare il processo di addestramento corrente e abilitare la profilazione dei parametri del framework, consulta Aggiornamento della configurazione di profilazione del framework di Debugger.
Procedura dettagliata del report di profilazione di Debugger
In questa sezione viene illustrato il report di profilazione di Debugger sezione per sezione. Il report di profilazione viene generato in base alle regole integrate per il monitoraggio e la profilazione. Il report mostra i grafici dei risultati solo per le regole che hanno riscontrato problemi.
Importante
Nel report, i grafici e le raccomandazioni sono forniti a scopo informativo e non sono definitivi. Sei responsabile della tua valutazione indipendente delle informazioni.
Argomenti
- Riepilogo del processo di addestramento
- Statistiche di utilizzo del sistema
- Riepilogo dei parametri del framework
- Riepilogo delle regole
- Analisi del ciclo di addestramento: durata delle fasi
- Analisi dell'utilizzo della GPU
- Dimensione batch
- Colli di bottiglia della CPU
- Colli di bottiglia di I/O
- Sistema di bilanciamento del carico nell'addestramento con più GPU
- Analisi della memoria GPU
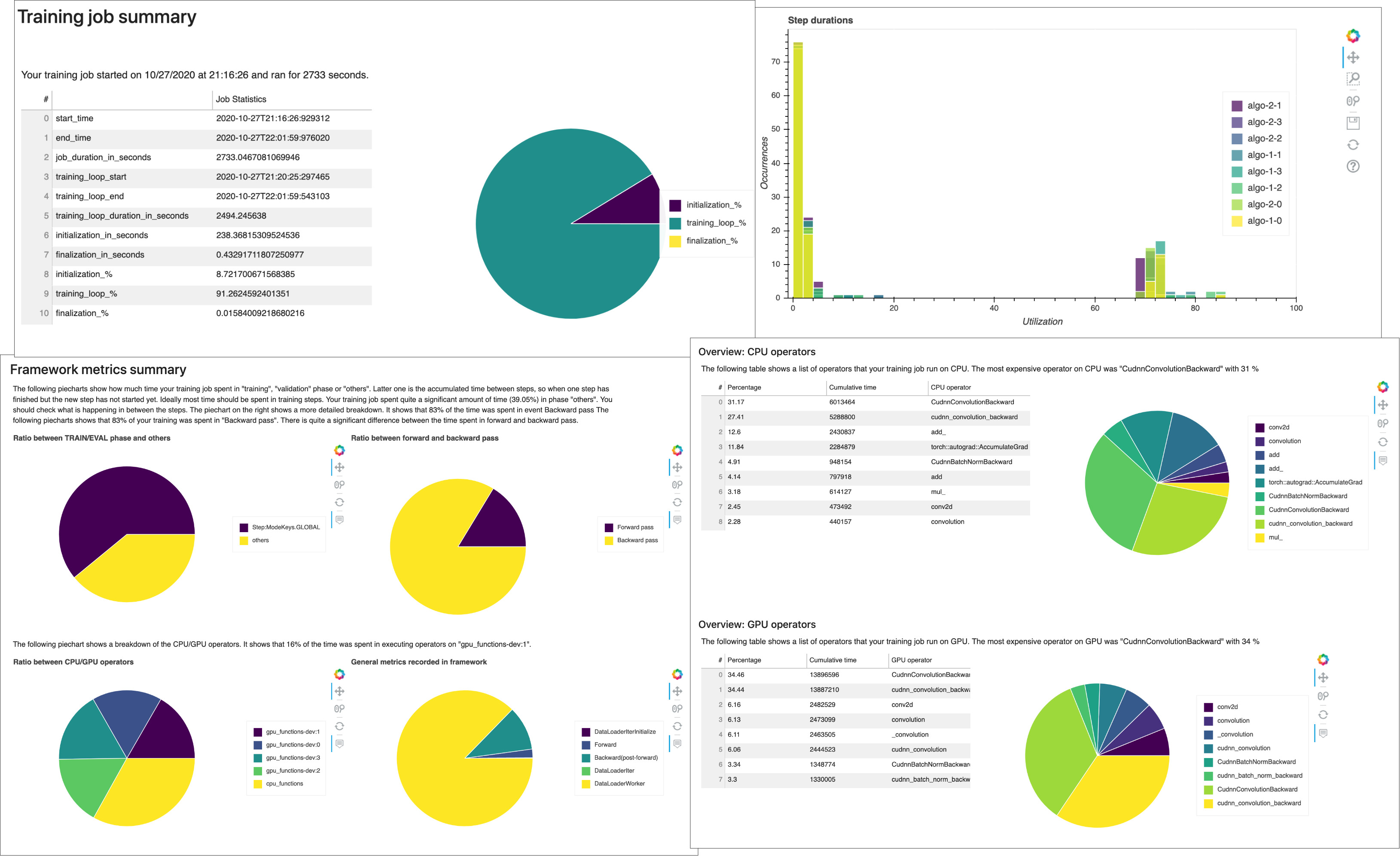
Riepilogo del processo di addestramento
All'inizio del report, Debugger fornisce un riepilogo del processo di addestramento eseguito. In questa sezione, puoi visualizzare una panoramica delle durate e degli orari nelle diverse fasi dell'addestramento.
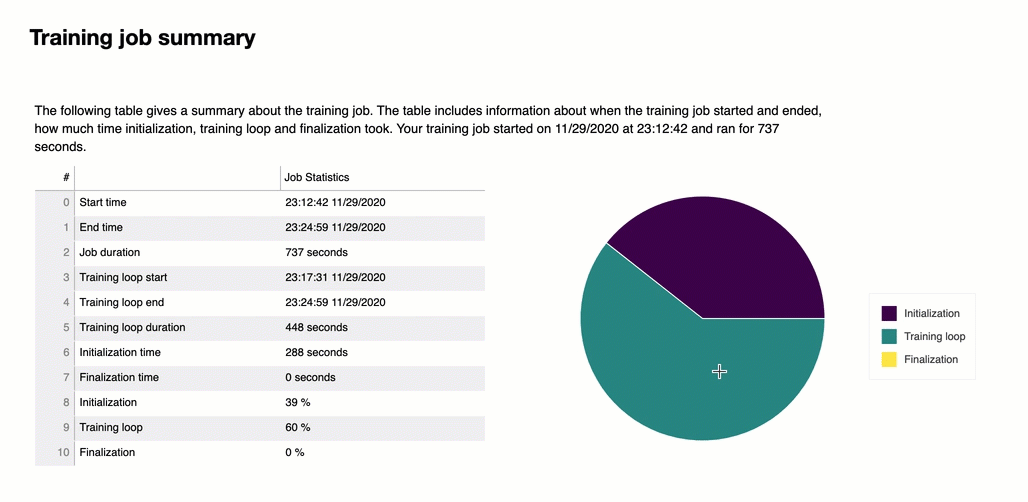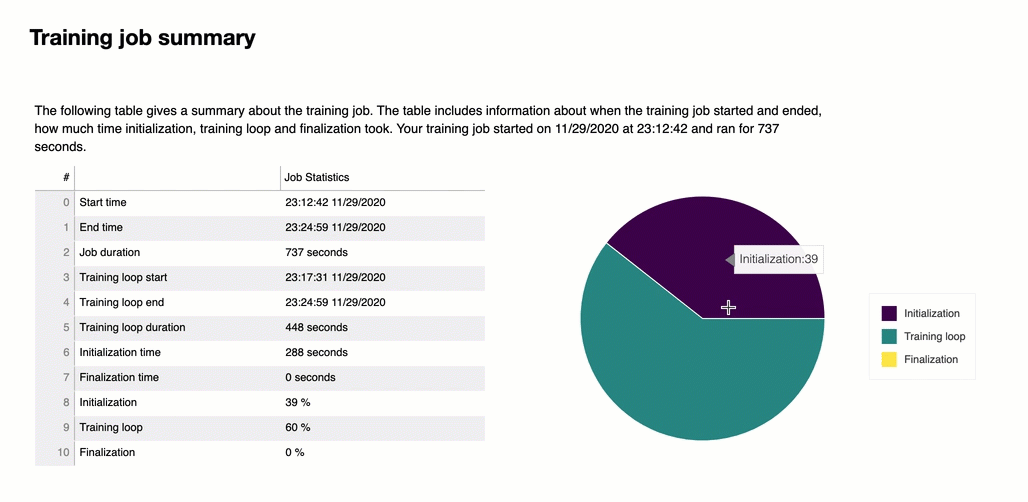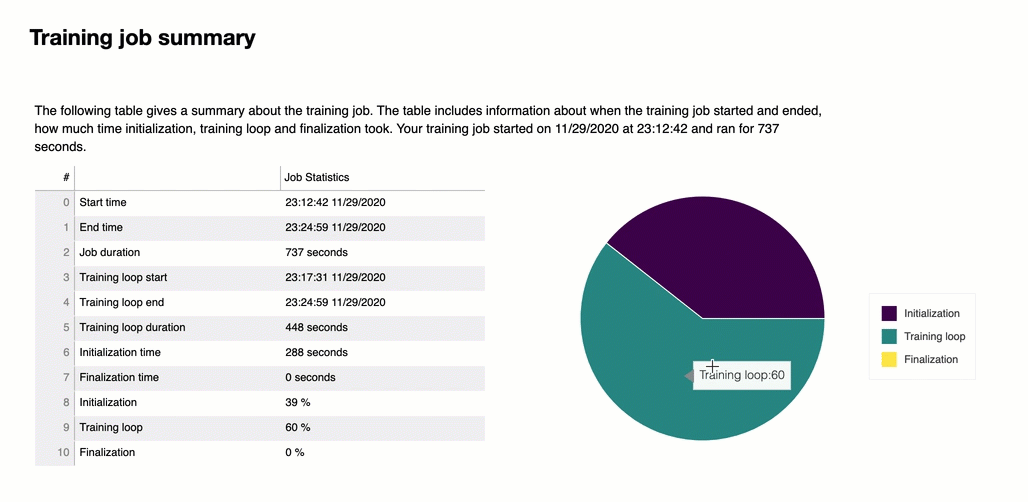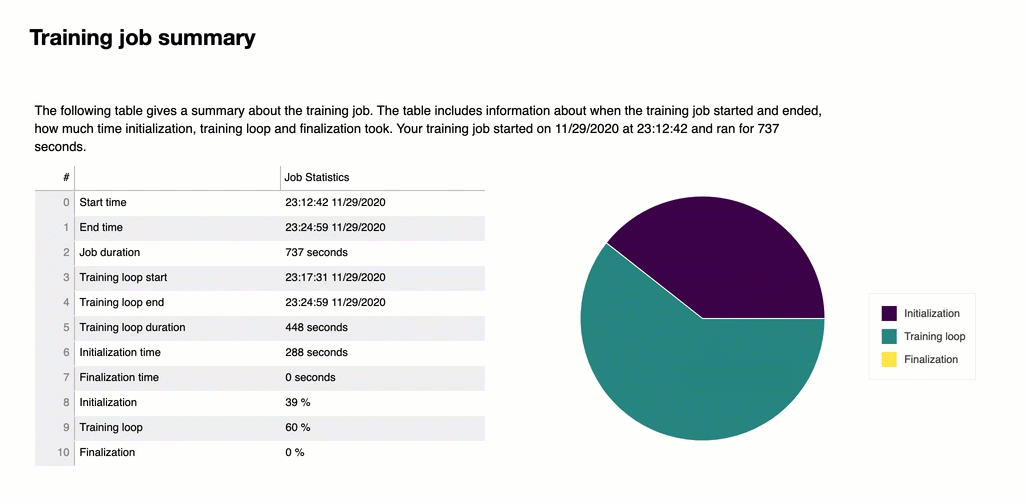
La tabella di riepilogo contiene le informazioni seguenti:
-
ora_inizio: l'ora esatta in cui è iniziato il processo di addestramento.
-
ora_fine: l'ora esatta in cui il processo di addestramento è terminato.
-
durata_processo_in_secondi: il tempo totale di addestramento da ora_inizio a ora_fine.
-
avvio_ciclo_addestramento: l'ora esatta in cui è iniziata la prima fase della prima epoca.
-
fine_ciclo_addestramento: l'ora esatta in cui è terminata l’ultima fase dell’ultima epoca.
-
durata_ciclo_addestramento_in_secondi: il tempo totale tra l'ora di inizio del ciclo di addestramento e l'ora di fine del ciclo di addestramento.
-
inizializzazione_in_secondi: tempo impiegato per inizializzare il processo di addestramento. La fase di inizializzazione copre il periodo compreso tra ora_inizio e l’ora di inizio_ciclo_addestramento. Il tempo di inizializzazione viene dedicato alla compilazione dello script di addestramento, all'avvio dello script di addestramento, alla creazione e inizializzazione del modello, all'avvio delle istanze EC2 e al download dei dati di addestramento.
-
finalizzazione_in_secondi – Tempo impiegato per finalizzare il processo di addestramento, ad esempio per completare l'addestramento del modello, aggiornare gli artefatti del modello e chiudere le istanze EC2. La fase di inizializzazione copre il periodo compreso tra l’ora di dine_ciclo_addestramento e ora_fine.
-
inizializzazione (%) – La percentuale di tempo impiegato per l’inizializzazione rispetto al totale della durata_processo_in_secondi.
-
ciclo di addestramento (%) – La percentuale di tempo impiegato per il ’ciclo di addestramento rispetto al totale della durata_processo_in_secondi.
-
finalizzazione (%) – La percentuale di tempo impiegato per la finalizzazione rispetto al totale della durata_processo_in_secondi.
Statistiche di utilizzo del sistema
In questa sezione è possibile visualizzare una panoramica delle statistiche di utilizzo del sistema.
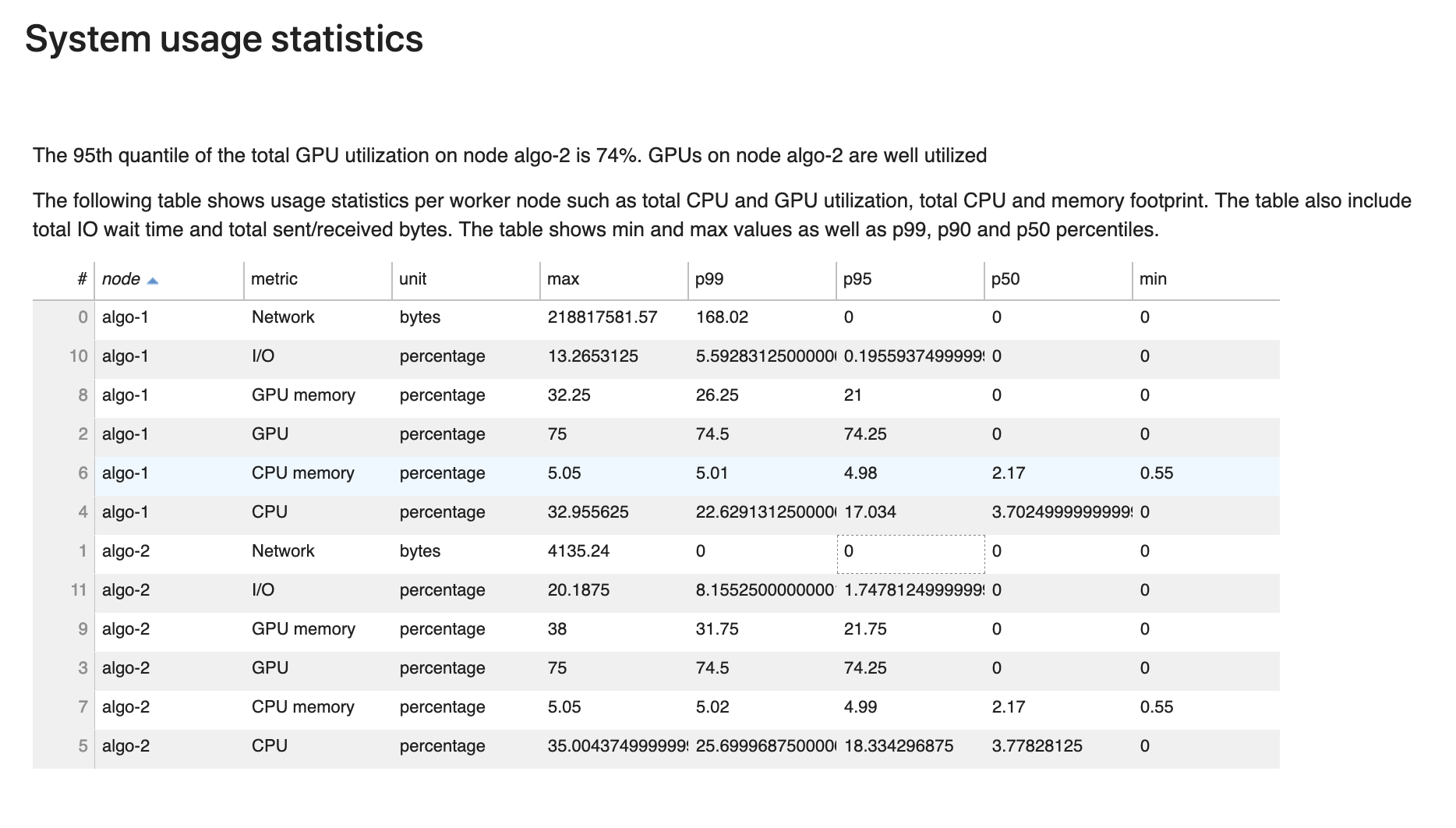
Il report di profilazione di Debugger include le seguenti informazioni:
-
nodo: elenca il nome dei nodi. Se si utilizza l'addestramento distribuito su più nodi (più istanze EC2), i nomi dei nodi hanno il formato
algo-n. -
parametro: i parametri di sistema raccolti da Debugger: CPU, GPU, memoria CPU, memoria GPU, I/O e parametri di rete.
-
unità: l’unità dei parametri di sistema.
-
max: il valore massimo di ogni parametro di sistema.
-
p99: il 99° percentile di utilizzo di ogni sistema.
-
p95: il 95° percentile di utilizzo di ogni sistema.
-
p50: il 50° percentile (mediana) di ogni utilizzo del sistema.
-
min: il valore minimo di ogni parametro di sistema.
Riepilogo dei parametri del framework
In questa sezione, i seguenti grafici a torta mostrano la suddivisione delle operazioni del framework su CPU e GPU.
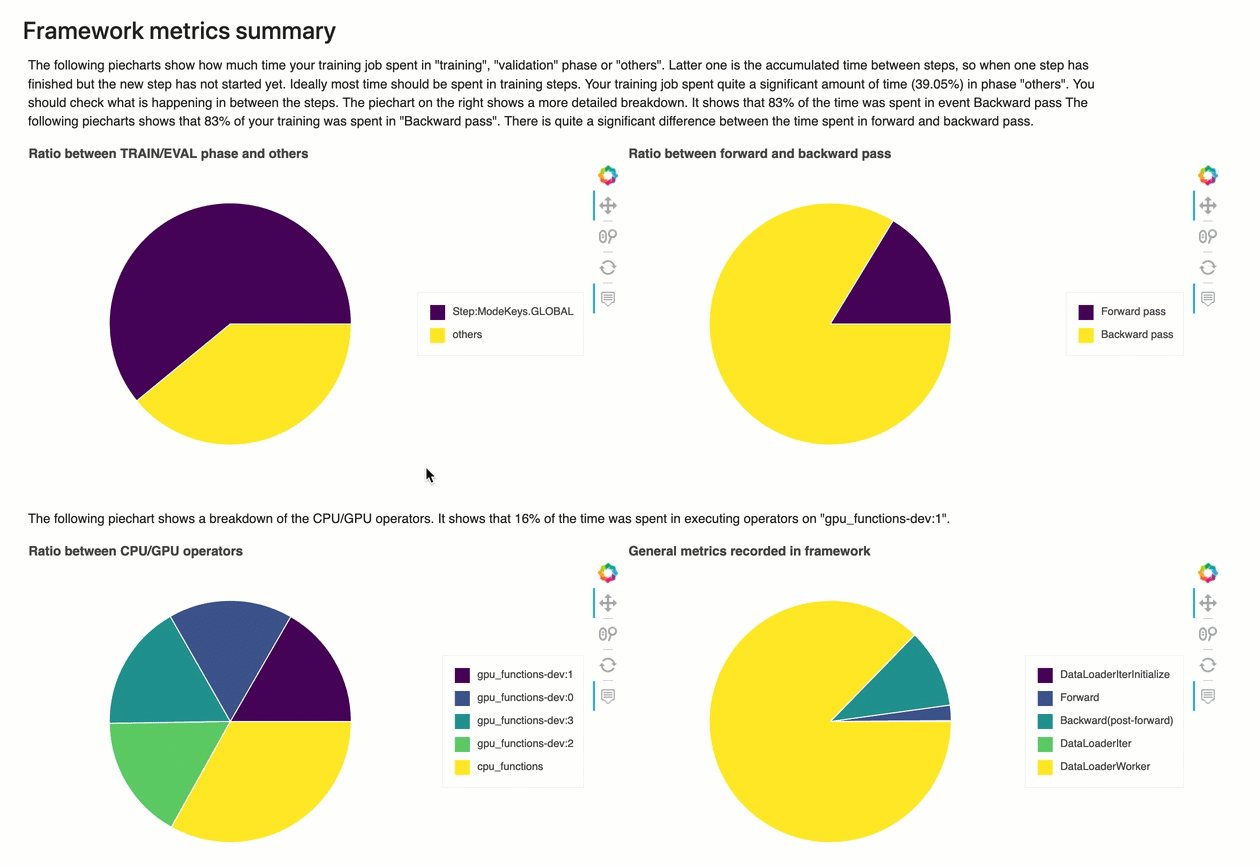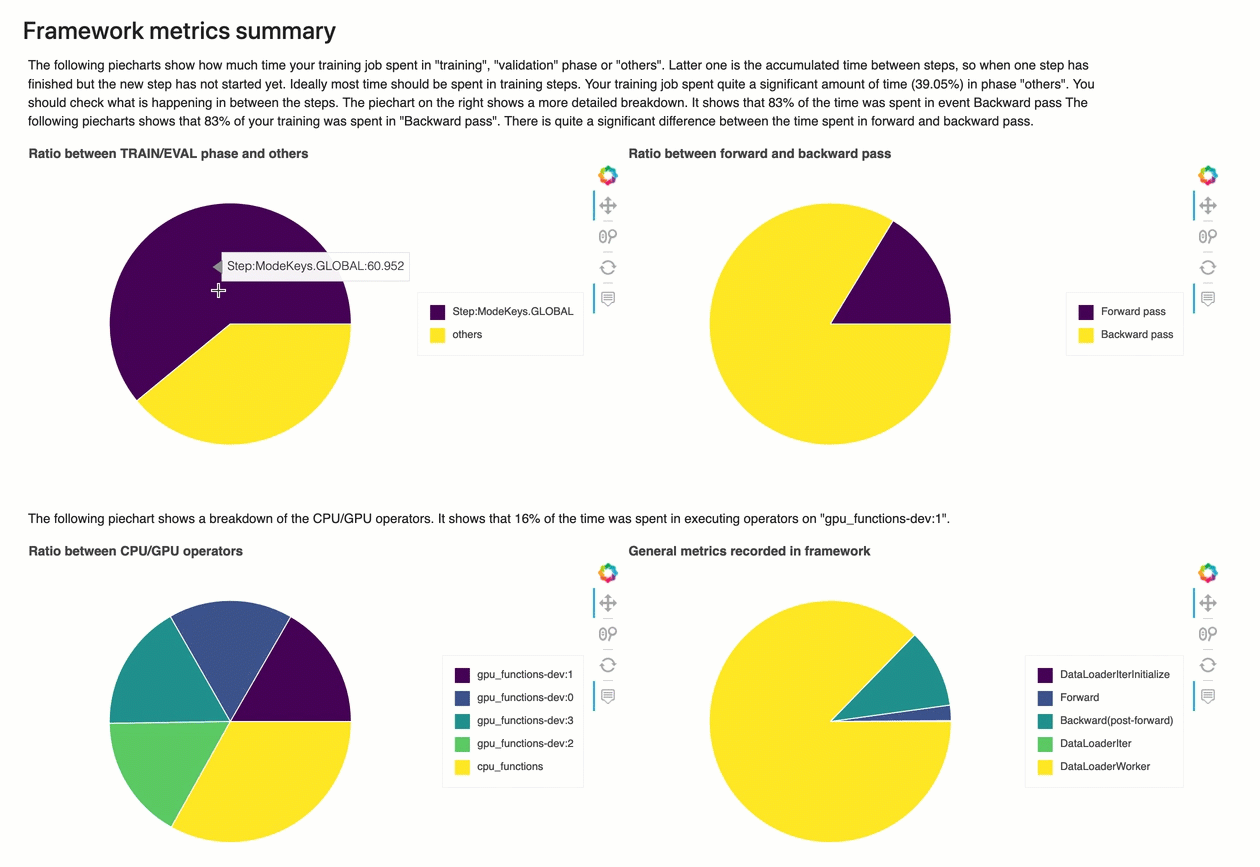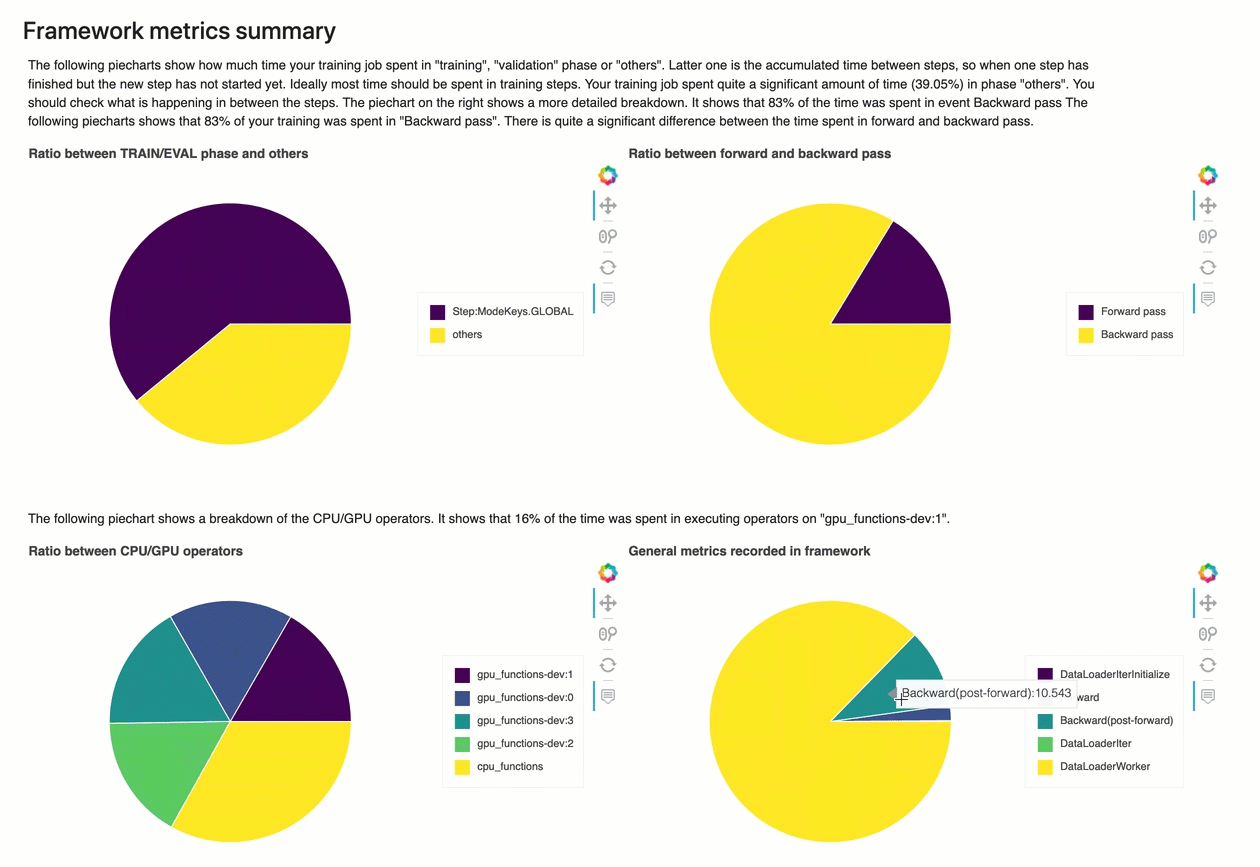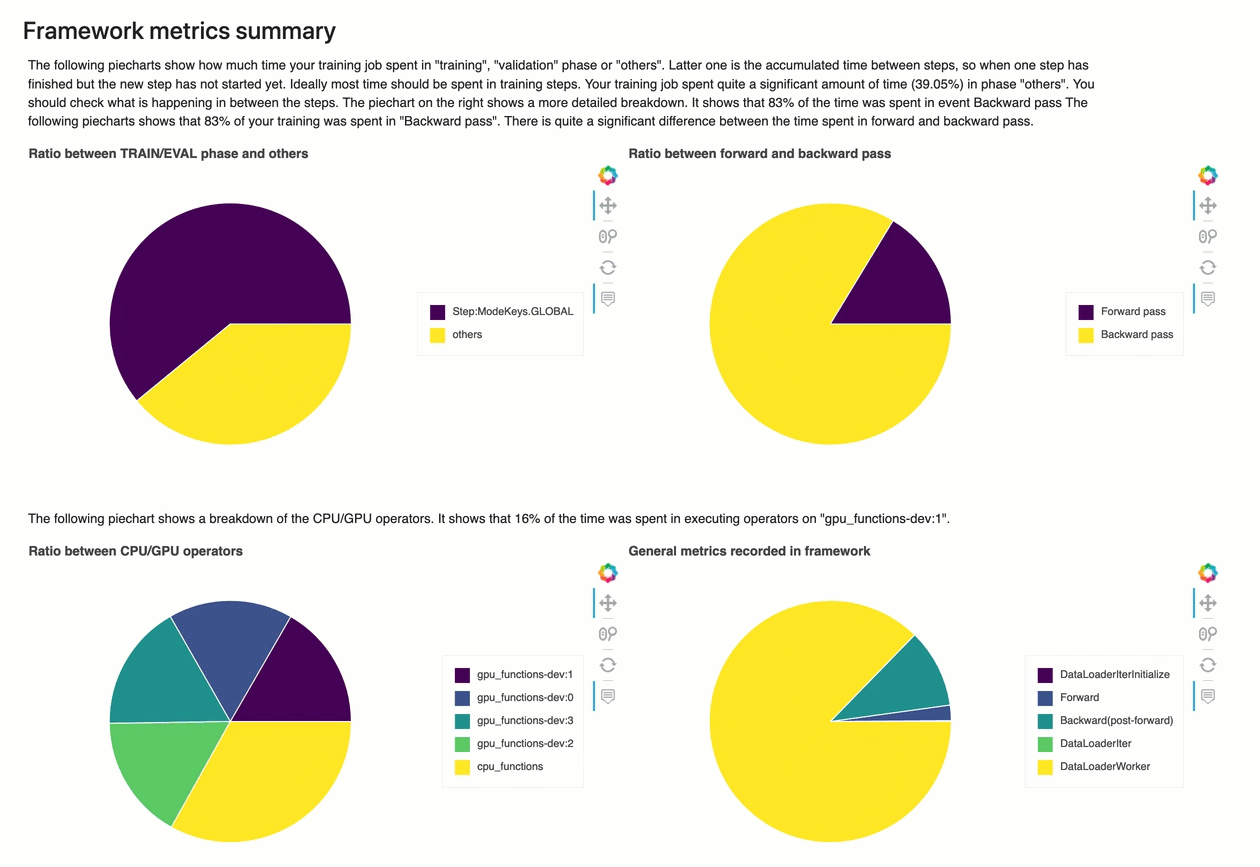
Ciascuno dei grafici a torta analizza i parametri del framework raccolti in vari aspetti come segue:
-
Rapporto tra la fase TRAIN/EVAL e le altre – Mostra il rapporto tra le durate di tempo impiegate nelle diverse fasi di addestramento.
-
Rapporto tra passaggio in avanti e indietro – Mostra il rapporto tra il tempo impiegato per il passaggio in avanti e quello all'indietro nel ciclo di addestramento.
-
Rapporto tra operatori CPU/GPU – Mostra il rapporto tra il tempo impiegato dagli operatori che utilizzano CPU o GPU, ad esempio gli operatori convoluzionali.
-
Parametri generali registrati nel framework – Mostra il rapporto tra il tempo impiegato per i principali parametri del framework, come il caricamento dei dati, il passaggio in avanti e all'indietro.
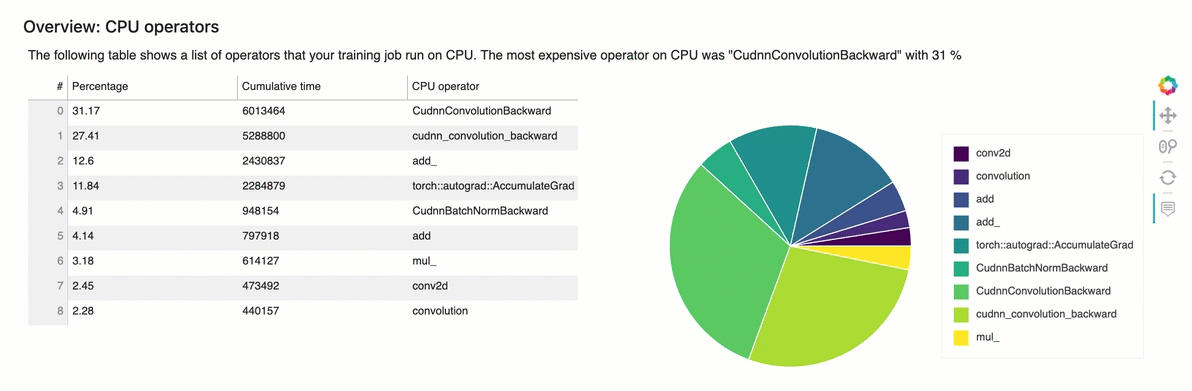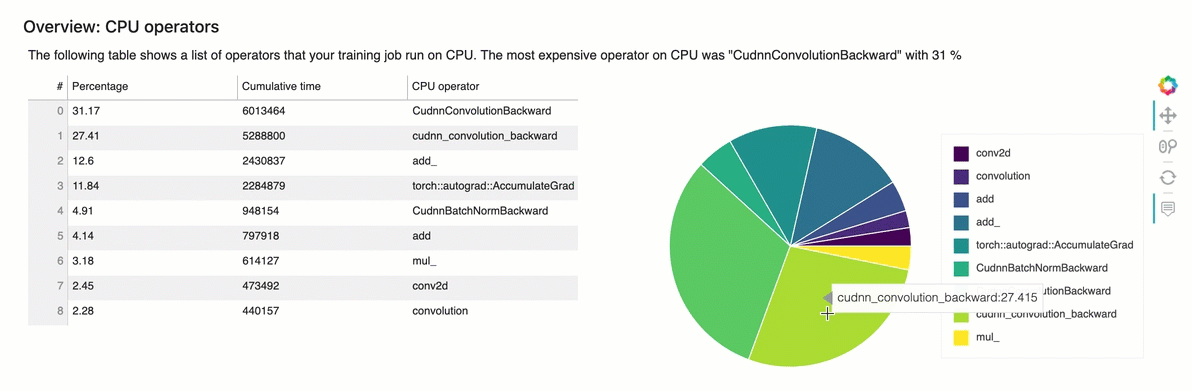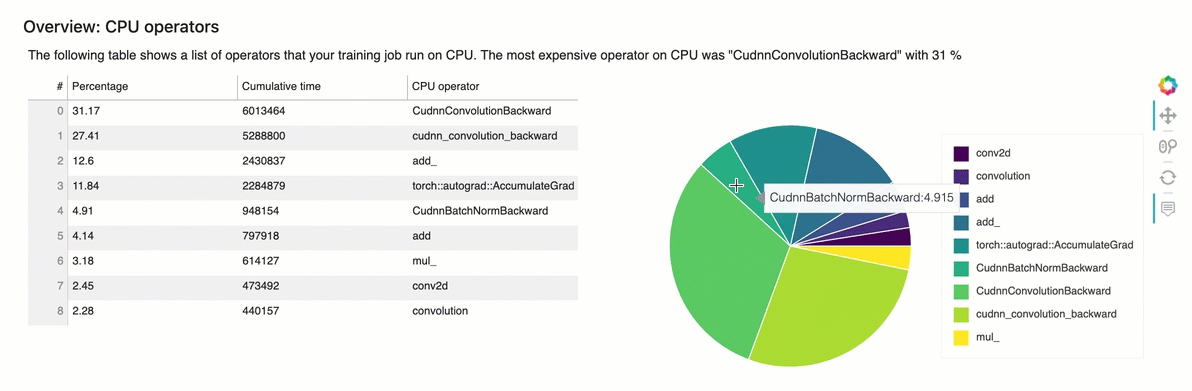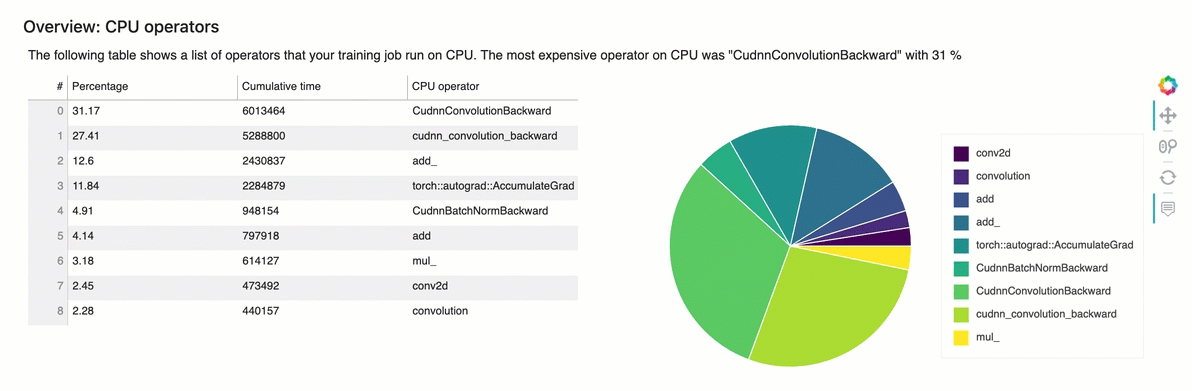
Panoramica: operatori della CPU
Questa sezione fornisce informazioni dettagliate sugli operatori della CPU. La tabella mostra la percentuale di tempo e il tempo cumulativo assoluto impiegato dagli operatori CPU più frequentemente chiamati.
Panoramica: operatori della GPU
Questa sezione fornisce informazioni dettagliate sugli operatori della GPU. La tabella mostra la percentuale di tempo e il tempo cumulativo assoluto impiegato dagli operatori GPU più frequentemente chiamati.
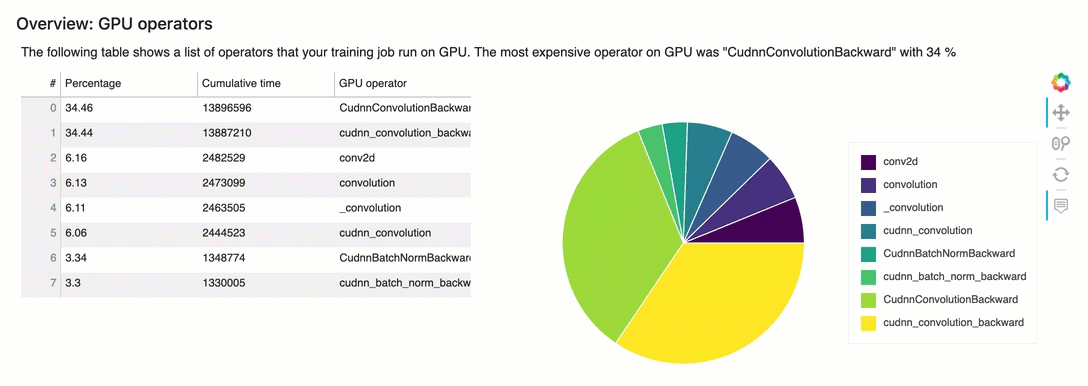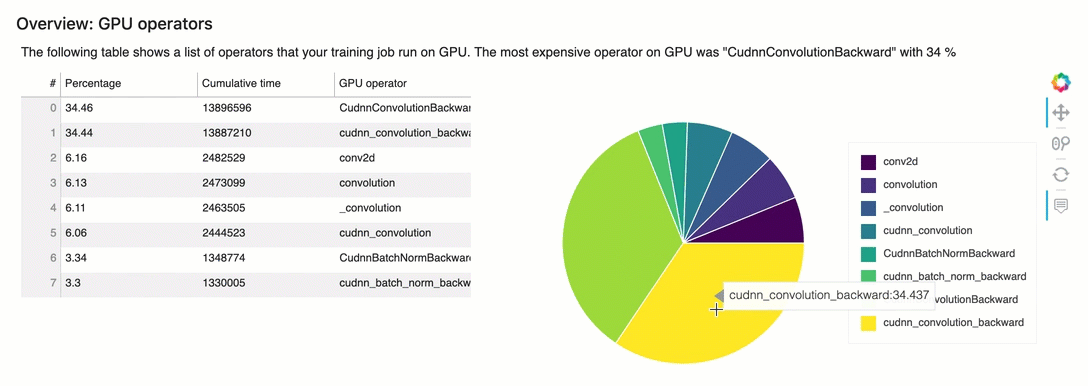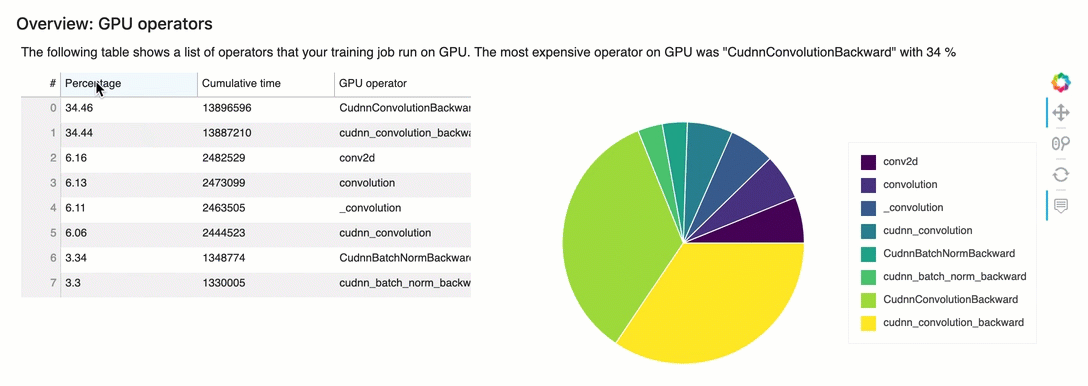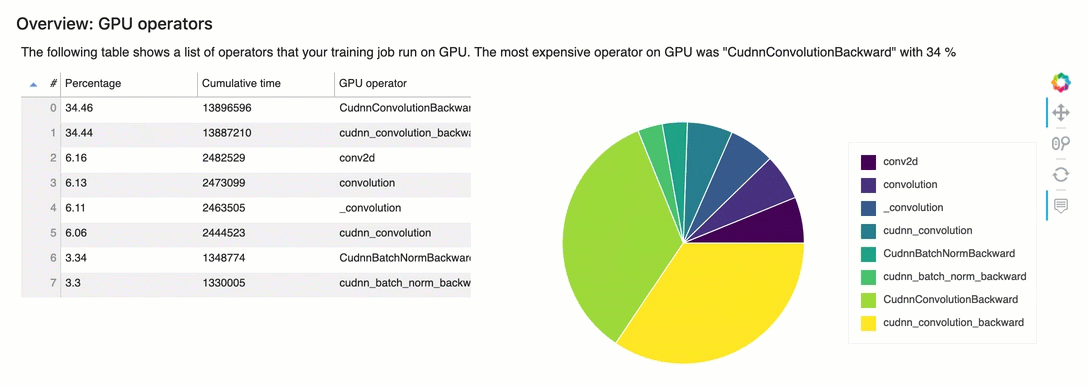
Riepilogo delle regole
In questa sezione, Debugger aggrega tutti i risultati della valutazione delle regole, le analisi, le descrizioni delle regole e i suggerimenti.
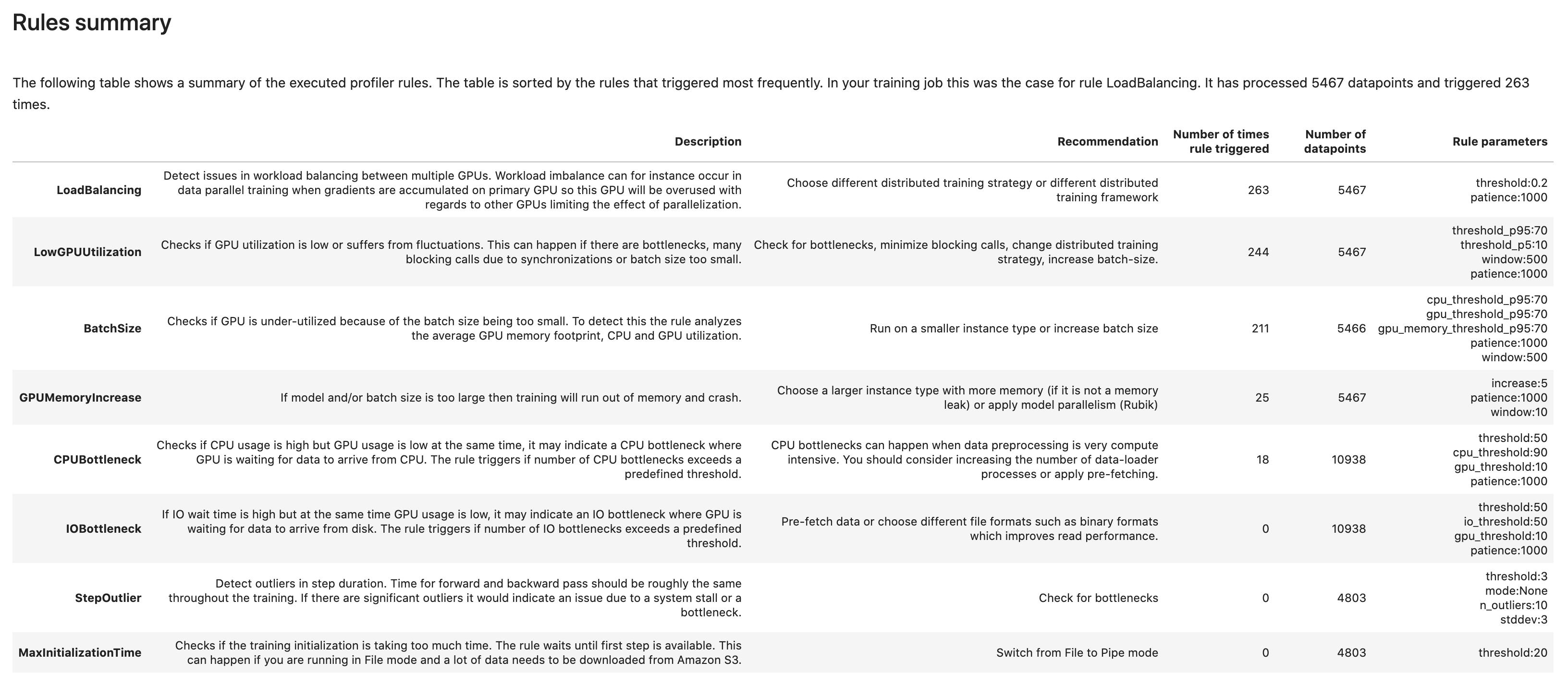
Analisi del ciclo di addestramento: durata delle fasi
In questa sezione, puoi trovare statistiche dettagliate sulla durata delle fasi su ciascun core della GPU di ciascun nodo. Debugger valuta i valori medi, massimi, p99, p95, p50 e minimi delle durate delle fasi e valuta i valori anomali delle fasi. L'istogramma seguente mostra le durate delle fasi acquisite su diversi nodi worker e GPU. È possibile abilitare o disabilitare l'istogramma di ogni worker scegliendo le legende sul lato destro. È possibile verificare se c'è una particolare GPU che causa valori anomali nella durata delle fasi.
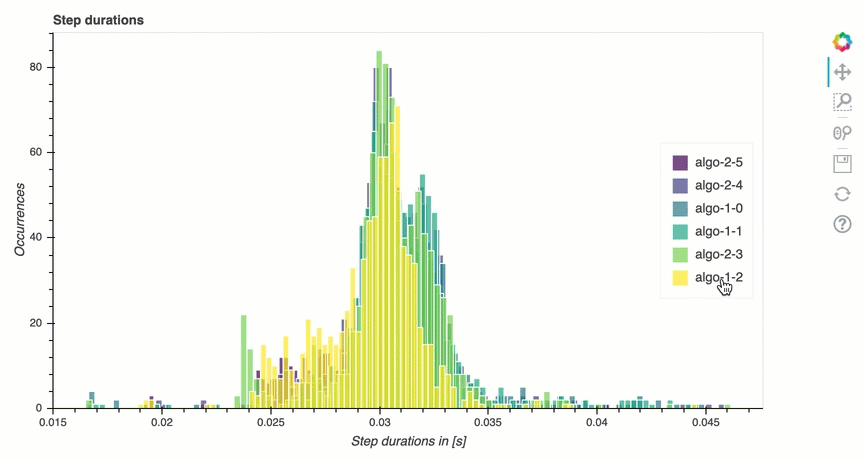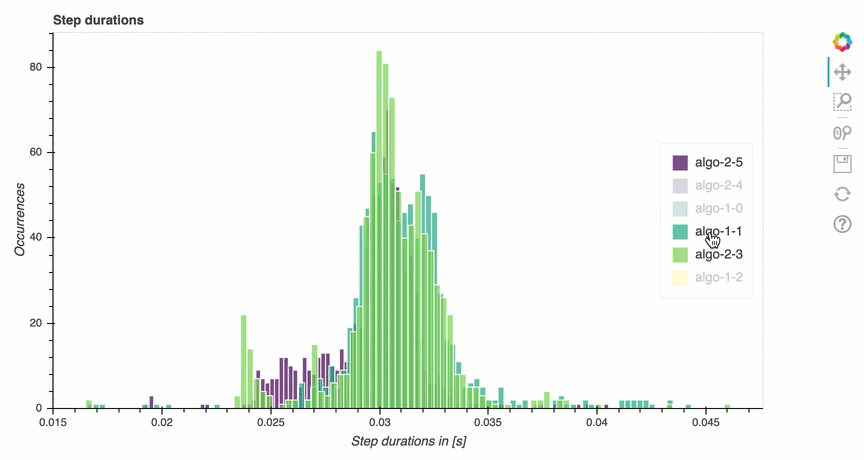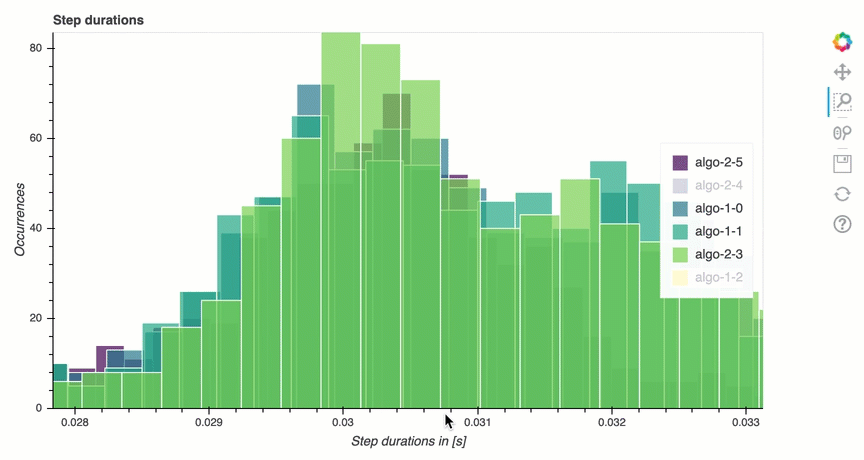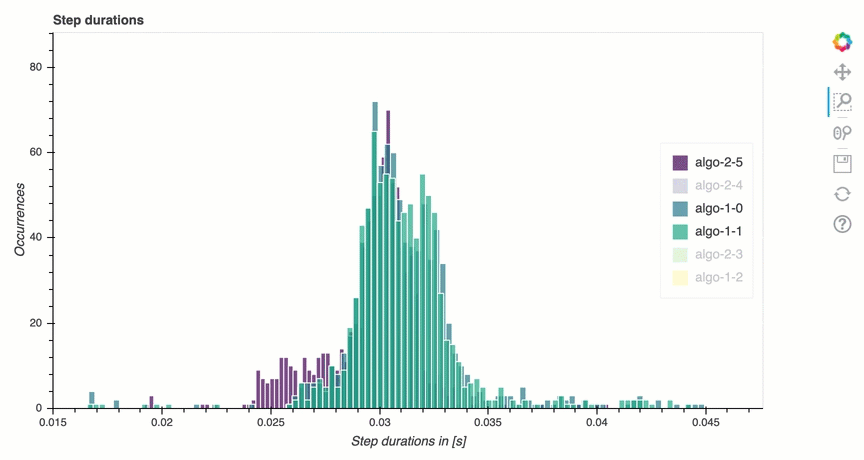
Analisi dell'utilizzo della GPU
Questa sezione mostra le statistiche dettagliate sull'utilizzo del core della GPU in base alla regola LowGPUUtilization. Inoltre riassume le statistiche sull'utilizzo della GPU, media, p95 e p5 per determinare se il processo di addestramento sta sottoutilizzando le GPU.
Dimensione batch
Questa sezione mostra le statistiche dettagliate sull'utilizzo totale della CPU, sull'utilizzo delle singole GPU e sull'impronta della memoria della GPU. La BatchSize regola determina se è necessario modificare la dimensione del batch per utilizzare meglio le GPU. È possibile verificare se la dimensione del batch è troppo piccola, con conseguente sottoutilizzo o troppo grande, con conseguente sovrautilizzo e problemi di esaurimento della memoria. Nel grafico, le caselle mostrano gli intervalli percentili p25 e p75 (riempiti rispettivamente di viola scuro e giallo brillante) rispetto alla mediana (p50), mentre le barre di errore mostrano il 5° percentile per il limite inferiore e il 95° percentile per il limite superiore.

Colli di bottiglia della CPU
In questa sezione, puoi approfondire i colli di bottiglia della CPU rilevati dalla regola CPUBottleNeck durante il processo di addestramento. La regola verifica se l'utilizzo della CPU è superiore a cpu_threshold (90% per impostazione predefinita) e anche se l'utilizzo della GPU è inferiore (10% per impostazione predefinita). gpu_threshold
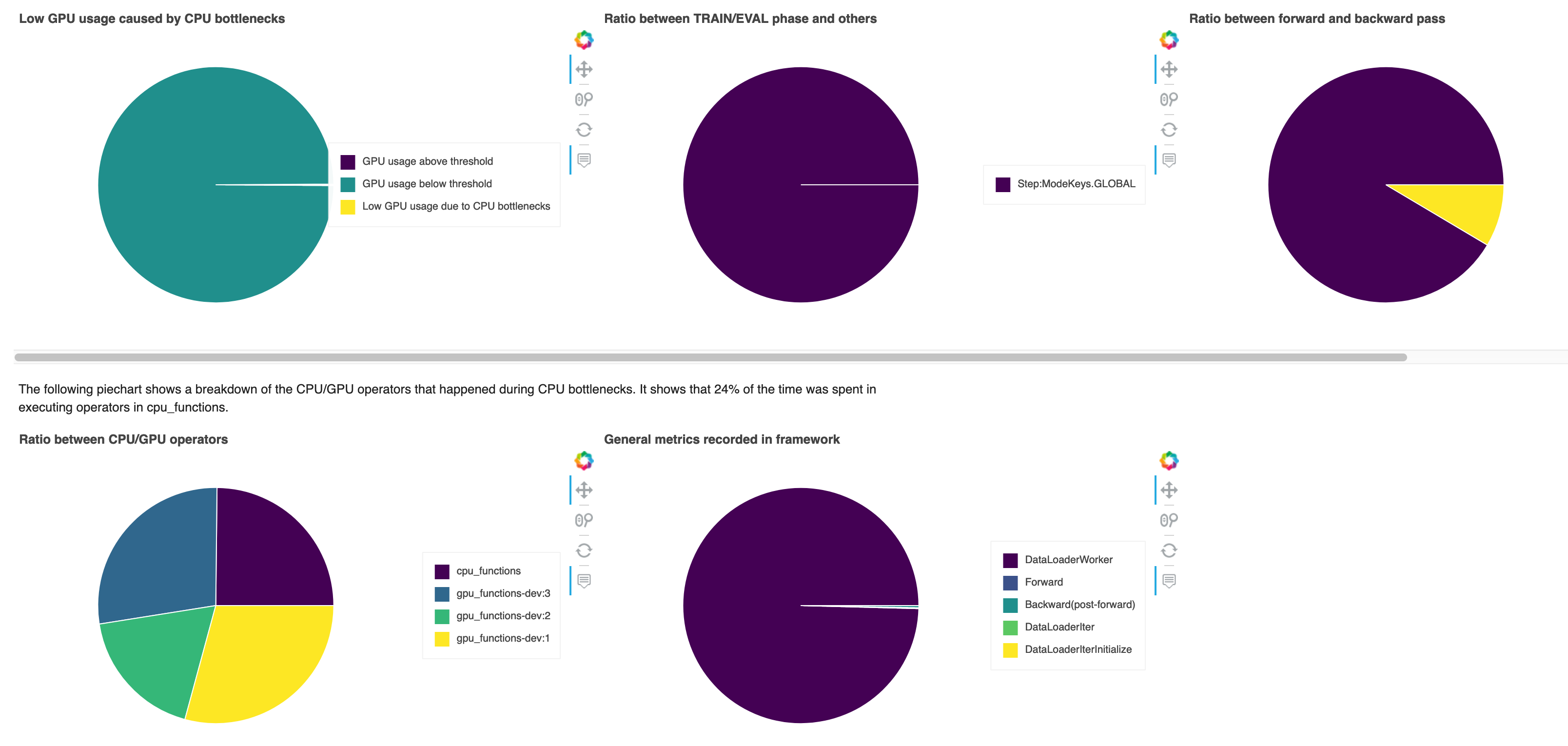
I grafici a torta mostrano le seguenti informazioni:
-
Scarso utilizzo della GPU causato da colli di bottiglia della CPU – Mostra il rapporto tra i punti dati tra quelli con un utilizzo della GPU superiore e inferiore alla soglia e quelli che corrispondono ai criteri di collo di bottiglia della CPU.
-
Rapporto tra la fase TRAIN/EVAL e le altre – Mostra il rapporto tra le durate di tempo impiegate nelle diverse fasi di addestramento.
-
Rapporto tra passaggio in avanti e indietro – Mostra il rapporto tra il tempo impiegato per il passaggio in avanti e quello all'indietro nel ciclo di addestramento.
-
Rapporto tra operatori CPU/GPU – Mostra il rapporto tra le durate di tempo trascorse su GPU e CPU dagli operatori Python, come i processi di caricamento dati e gli operatori di passaggio avanti e indietro.
-
Parametri generali registrati nel framework – Mostra i principali parametri del framework e il rapporto tra il tempo impiegato per i parametri.
Colli di bottiglia di I/O
In questa sezione è possibile trovare un riepilogo dei colli di bottiglia di I/O. La regola valuta il tempo di attesa I/O e i tassi di utilizzo della GPU e monitora se il tempo impiegato per le richieste di I/O supera una soglia percentuale del tempo di addestramento totale. Potrebbe indicare problemi di I/O laddove le GPU attendono l'arrivo dei dati dalla memoria.
Sistema di bilanciamento del carico nell'addestramento con più GPU
In questa sezione puoi identificare i problemi di bilanciamento del carico di lavoro tra le GPU.
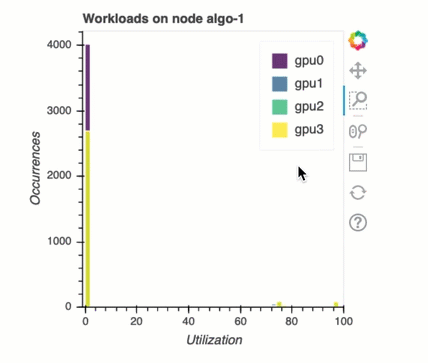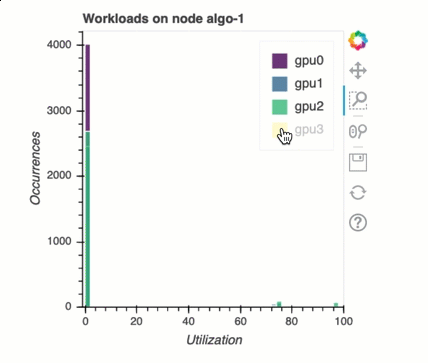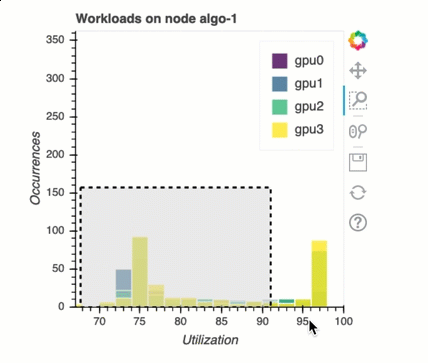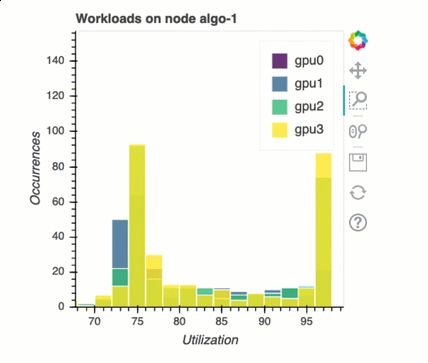
Analisi della memoria GPU
In questa sezione, è possibile analizzare l'utilizzo della memoria della GPU raccolto dalla regola GPU. MemoryIncrease Nel grafico, le caselle mostrano gli intervalli percentili p25 e p75 (riempiti rispettivamente di viola scuro e giallo brillante) rispetto alla mediana (p50), mentre le barre di errore mostrano il 5° percentile per il limite inferiore e il 95° percentile per il limite superiore.

