Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Demo e visualizzazione avanzate di Debugger
Le seguenti demo illustrano i casi d'uso avanzati e gli script di visualizzazione con Debugger.
Argomenti
Modelli di addestramento e potatura con Amazon SageMaker Experiments and Debugger
Dr. Nathalie Rauschmayr, scienziata applicata | Durata: 49 minuti 26 secondi AWS
Scopri come Amazon SageMaker Experiments and Debugger possono semplificare la gestione dei tuoi lavori di formazione. Amazon SageMaker Debugger offre una visibilità trasparente sui lavori di formazione e salva i parametri di formazione nel tuo bucket Amazon S3. SageMaker Experiments ti consente di chiamare le informazioni sulla formazione come versioni di prova tramite SageMaker Studio e supporta la visualizzazione del processo di formazione. Ciò consente di mantenere alta la qualità del modello riducendo i parametri meno importanti in base al grado di importanza.
Questo video illustra una tecnica di potatura dei modelli che rende i modelli pre-addestrati ResNet 50 e 50 più leggeri e convenienti, mantenendo al contempo elevati standard di precisione dei AlexNet modelli.
SageMaker AI Estimator addestra gli algoritmi forniti dallo zoo del PyTorch modello in un AWS Deep Learning Containers con PyTorch framework e Debugger estrae le metriche di allenamento dal processo di addestramento.
Il video mostra anche come configurare una regola personalizzata Debugger per controllare l'accuratezza di un modello eliminato, attivare un CloudWatch evento Amazon e una AWS Lambda funzione quando la precisione raggiunge una soglia e interrompere automaticamente il processo di pruning per evitare iterazioni ridondanti.
Gli obiettivi di apprendimento sono i seguenti:
-
Scopri come utilizzare l' SageMaker intelligenza artificiale per accelerare l'addestramento dei modelli di machine learning e migliorare la qualità dei modelli.
-
Scopri come gestire le iterazioni di formazione con SageMaker Experiments acquisendo automaticamente i parametri di input, le configurazioni e i risultati.
-
Scopri come Debugger rende trasparente il processo di addestramento acquisendo automaticamente i dati del tensore in tempo reale da parametri quali pesi, gradienti e output di attivazione delle reti neurali convoluzionali.
-
Da utilizzare CloudWatch per attivare Lambda quando Debugger rileva problemi.
-
Padroneggia il processo di SageMaker formazione utilizzando Experiments e Debugger. SageMaker
L'immagine seguente mostra come il processo iterativo di potatura del modello riduca le dimensioni di eliminando i 100 filtri meno significativi in base al AlexNet grado di importanza valutato dagli output di attivazione e dai gradienti.
Il processo di eliminazione ha ridotto i 50 milioni di parametri iniziali a 18 milioni. Ha inoltre ridotto la dimensione stimata del modello da 201 MB a 73 MB.
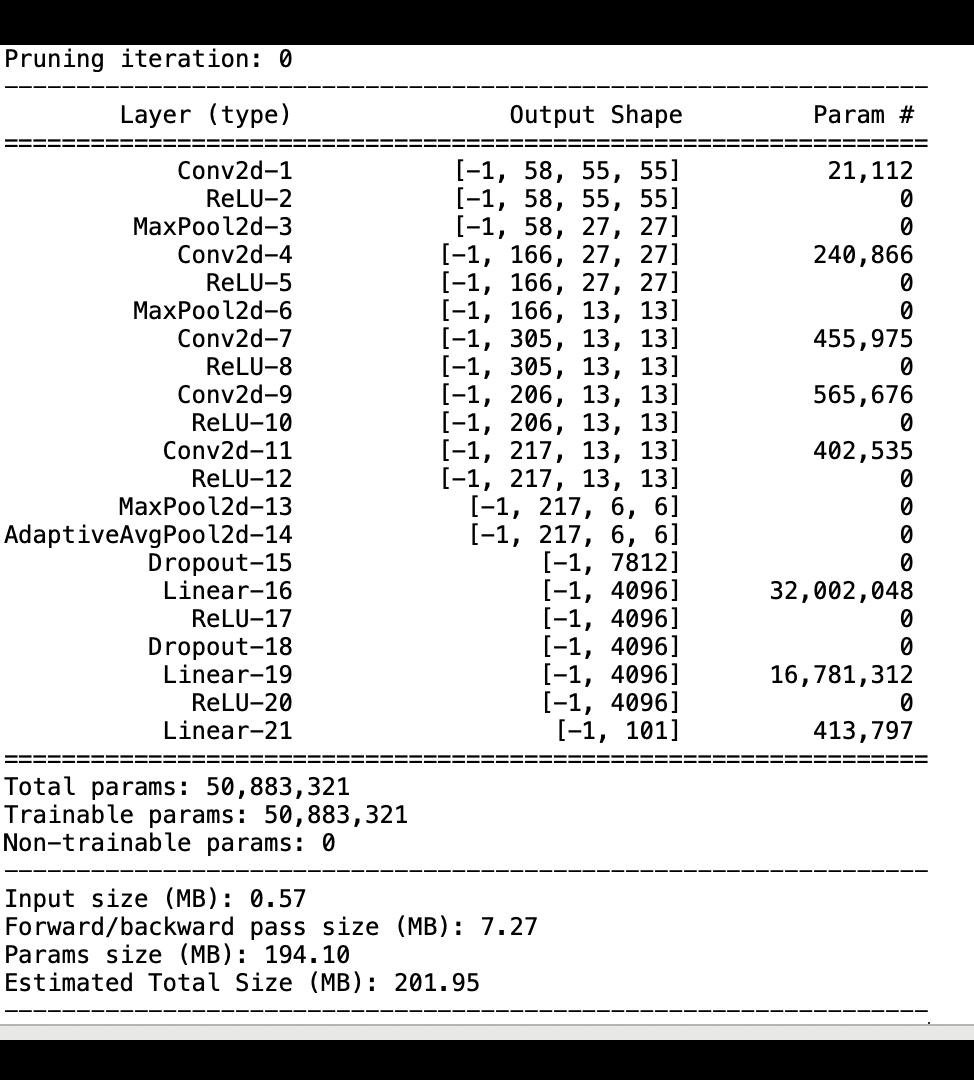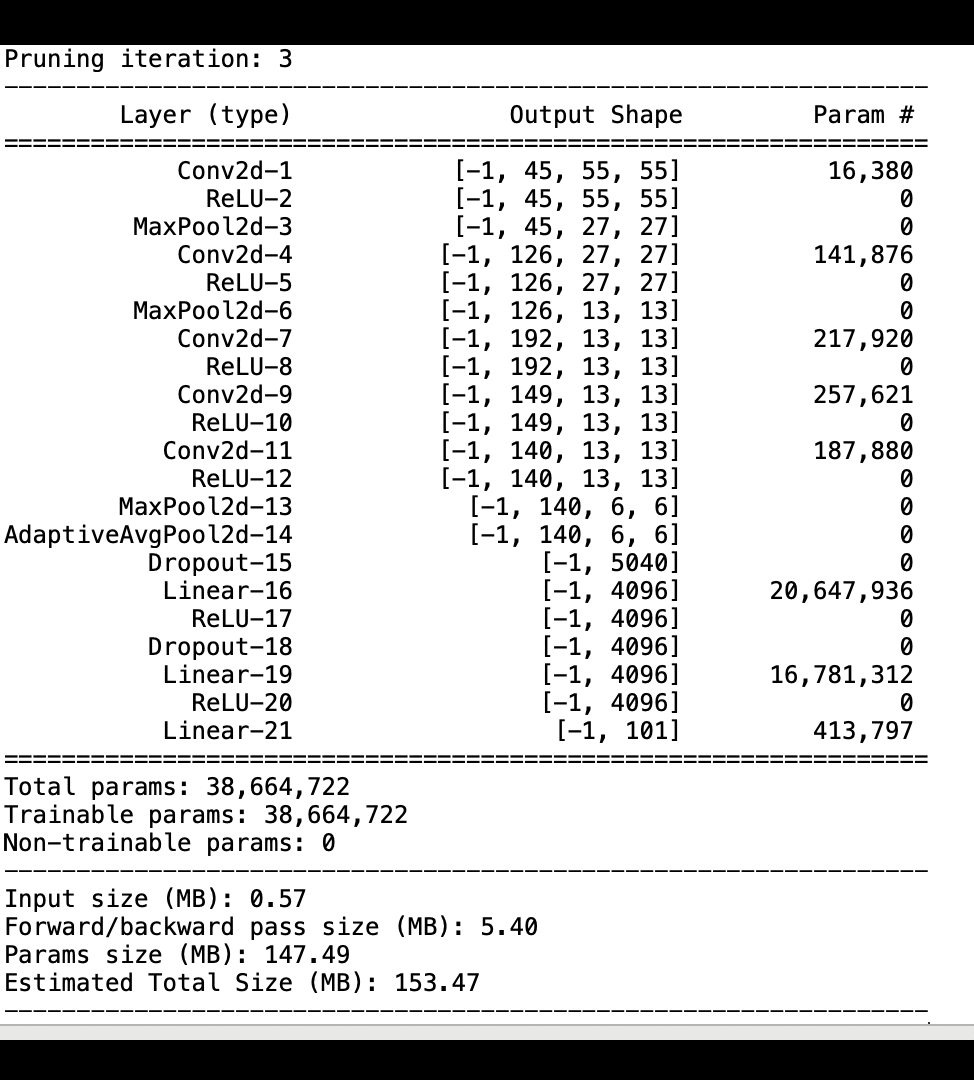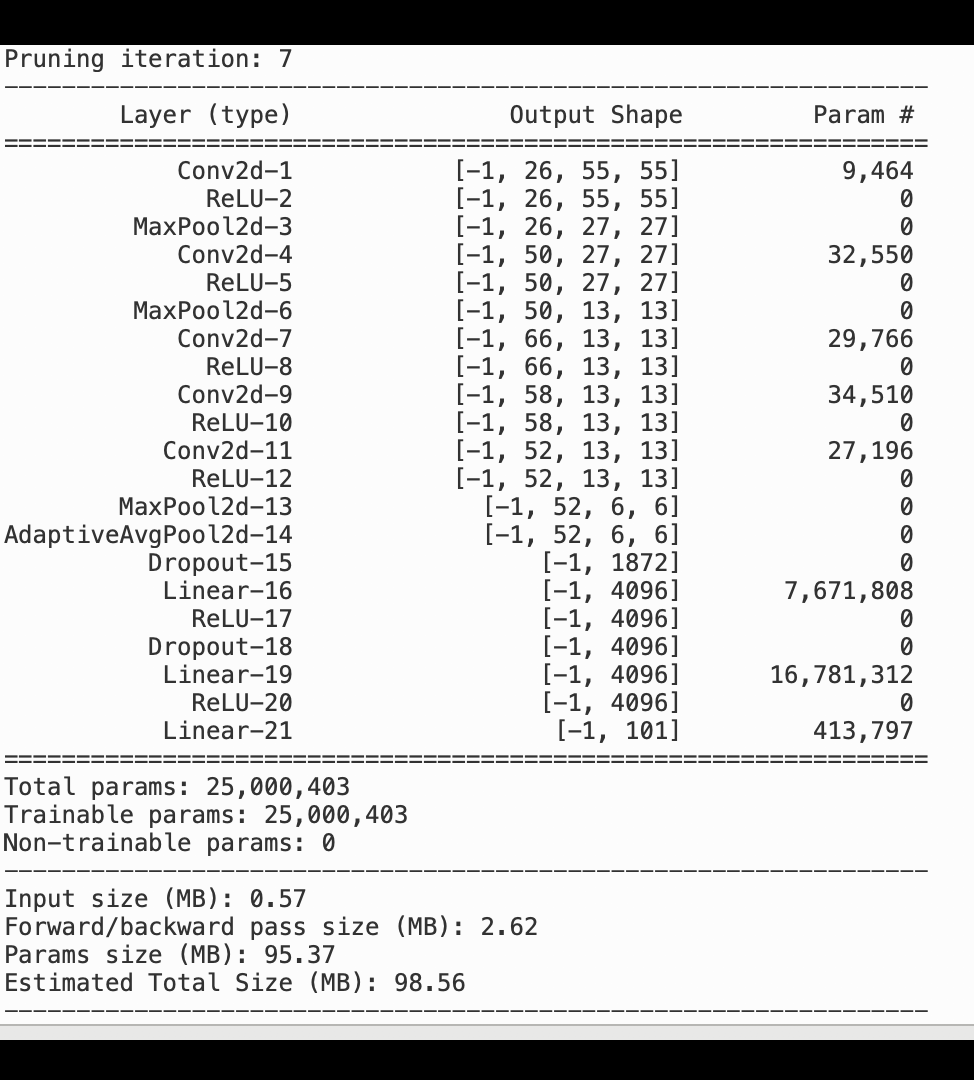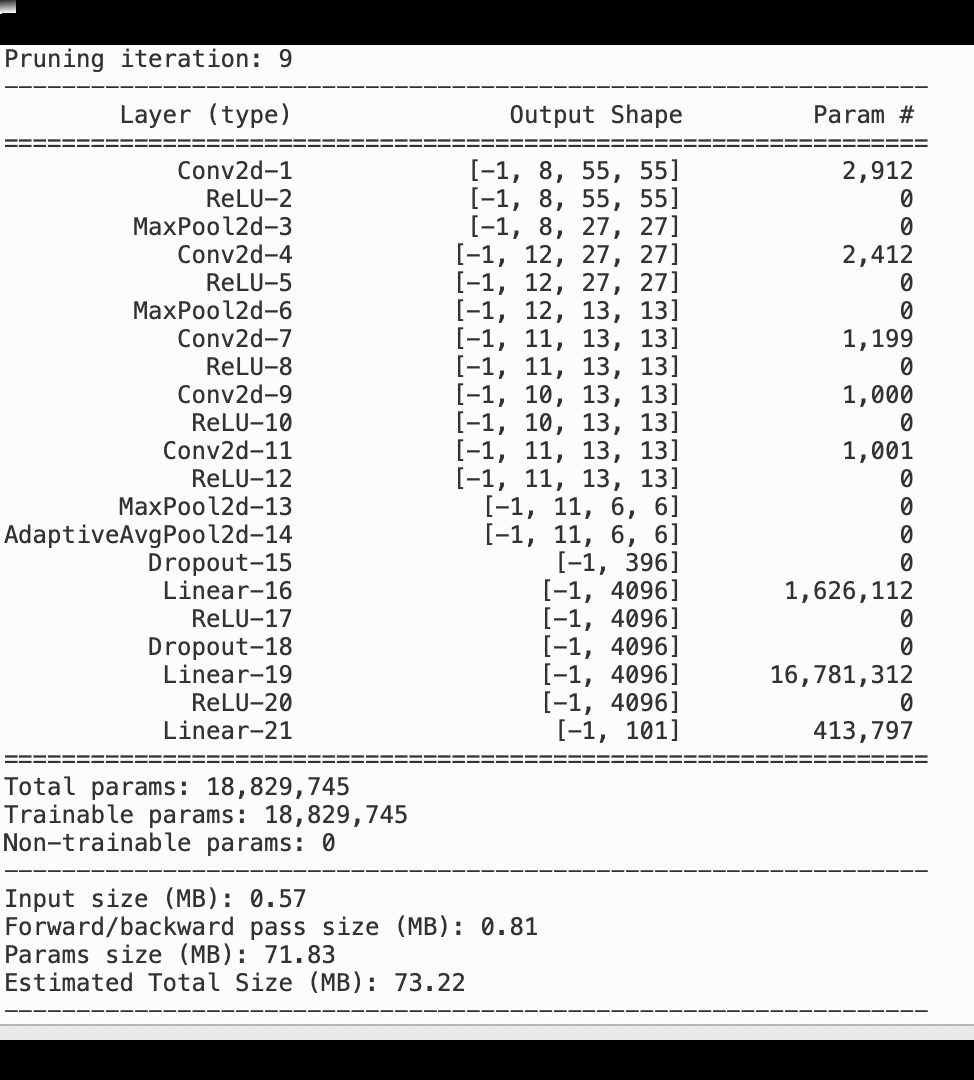
È inoltre necessario tenere traccia della precisione del modello e l'immagine seguente mostra come tracciare il processo di potatura del modello per visualizzare le modifiche nella precisione del modello in base al numero di parametri in Studio. SageMaker
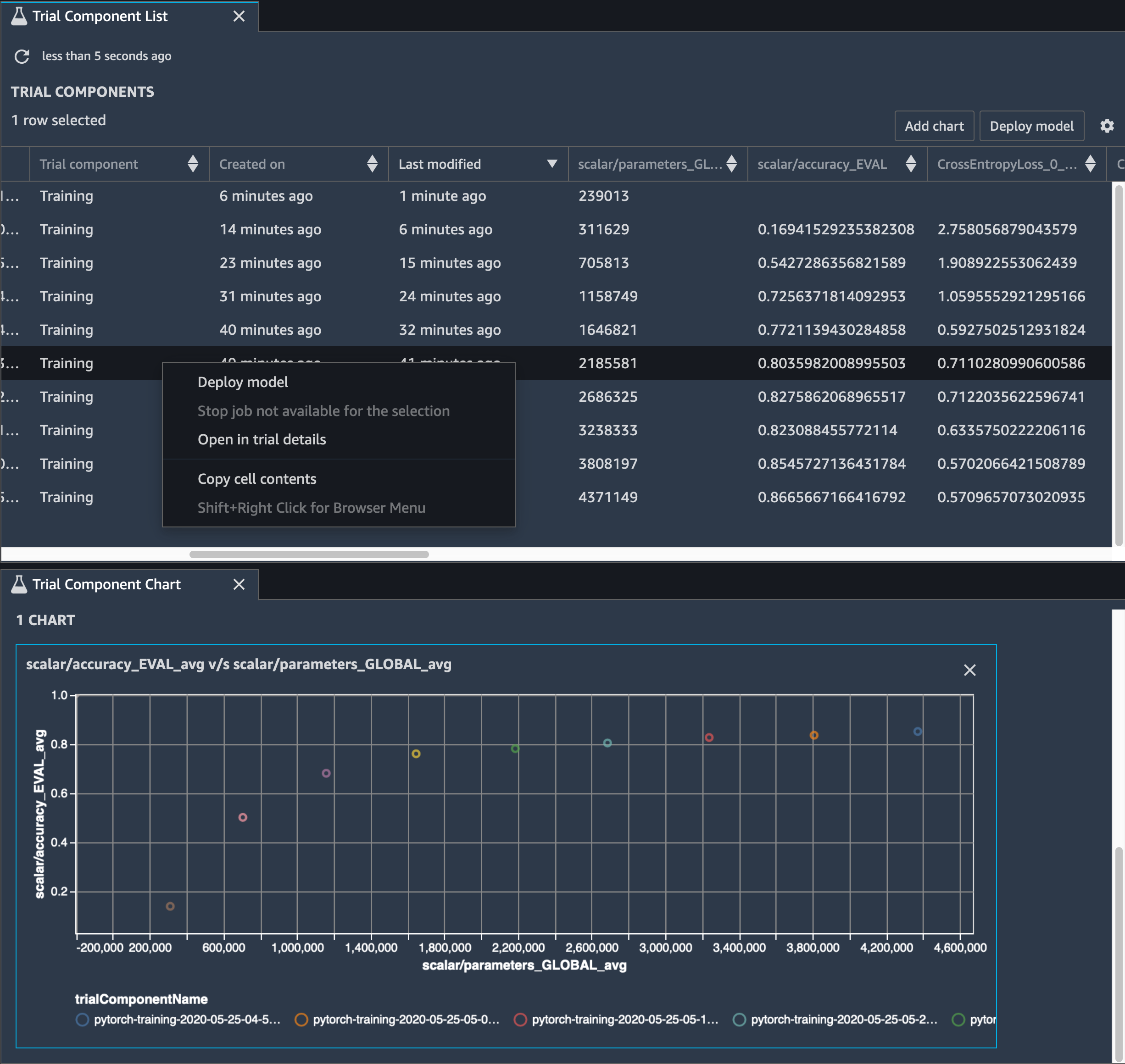
In SageMaker Studio, scegli la scheda Esperimenti, seleziona un elenco di tensori salvati da Debugger dal processo di potatura, quindi componi un pannello Trial Component List. Seleziona tutte e dieci le iterazioni e scegli Aggiungi grafico per creare un grafico componente di prova. Dopo aver deciso il modello da implementare, scegli il componente di prova e scegli un menu per eseguire un'azione oppure scegli Implementa modello.
Nota
Per distribuire un modello tramite SageMaker Studio utilizzando il seguente esempio di notebook, aggiungete una riga alla fine della funzione nello script. train train.py
# In the train.py script, look for the train function in line 58. def train(epochs, batch_size, learning_rate): ... print('acc:{:.4f}'.format(correct/total)) hook.save_scalar("accuracy", correct/total, sm_metric=True) # Add the following code to line 128 of the train.py script to save the pruned models # under the current SageMaker Studio model directorytorch.save(model.state_dict(), os.environ['SM_MODEL_DIR'] + '/model.pt')
Utilizzo di SageMaker Debugger per monitorare l'addestramento di un modello di autoencoder convoluzionale
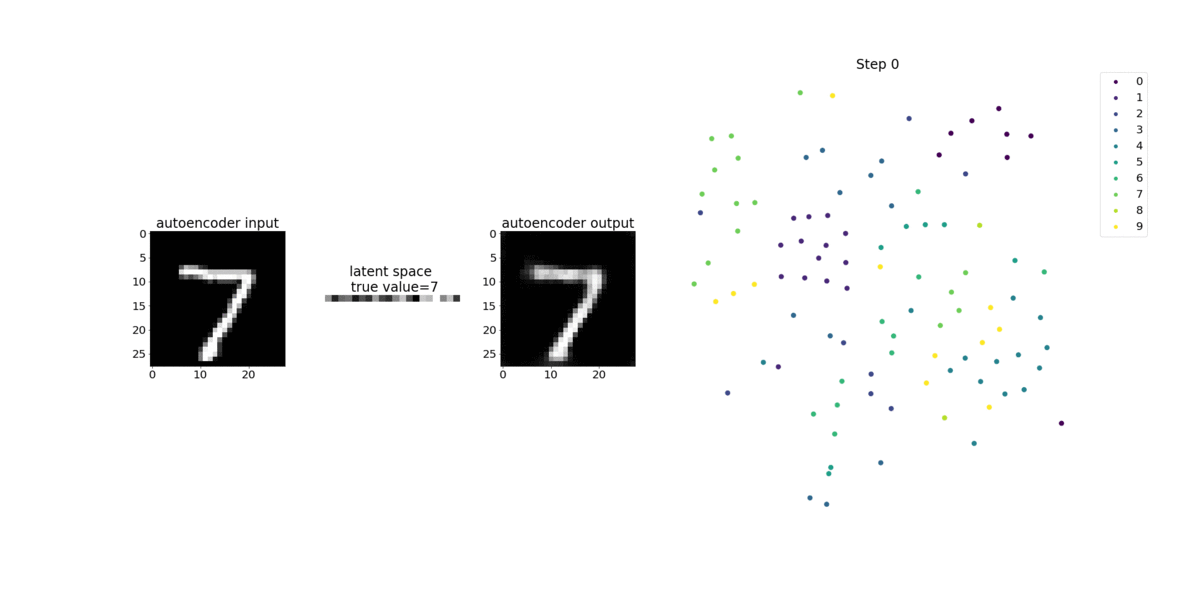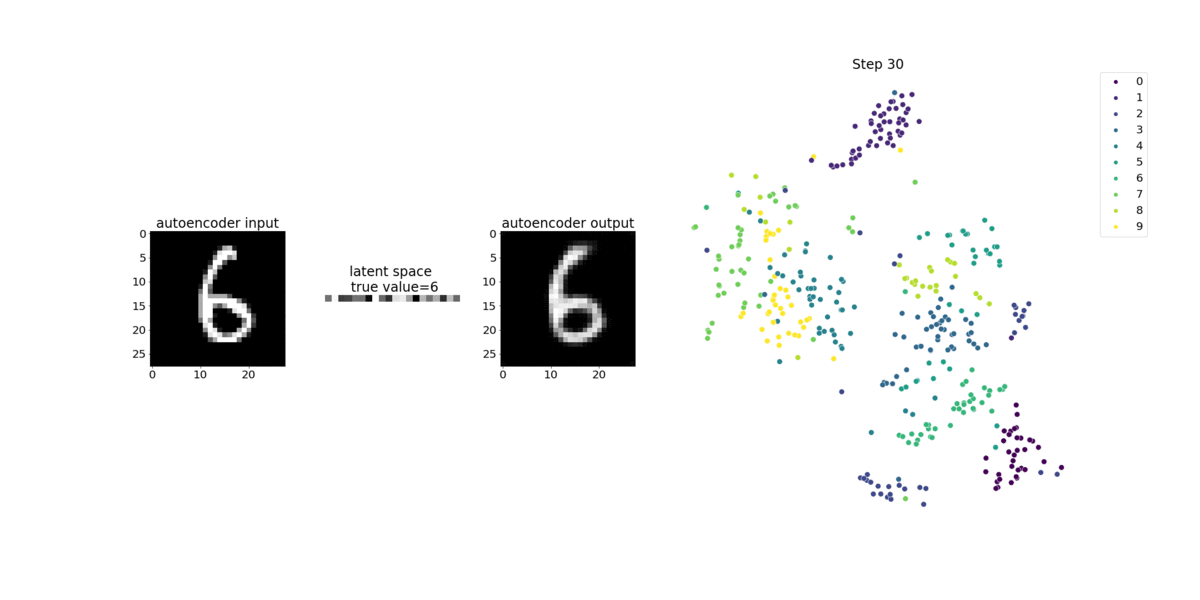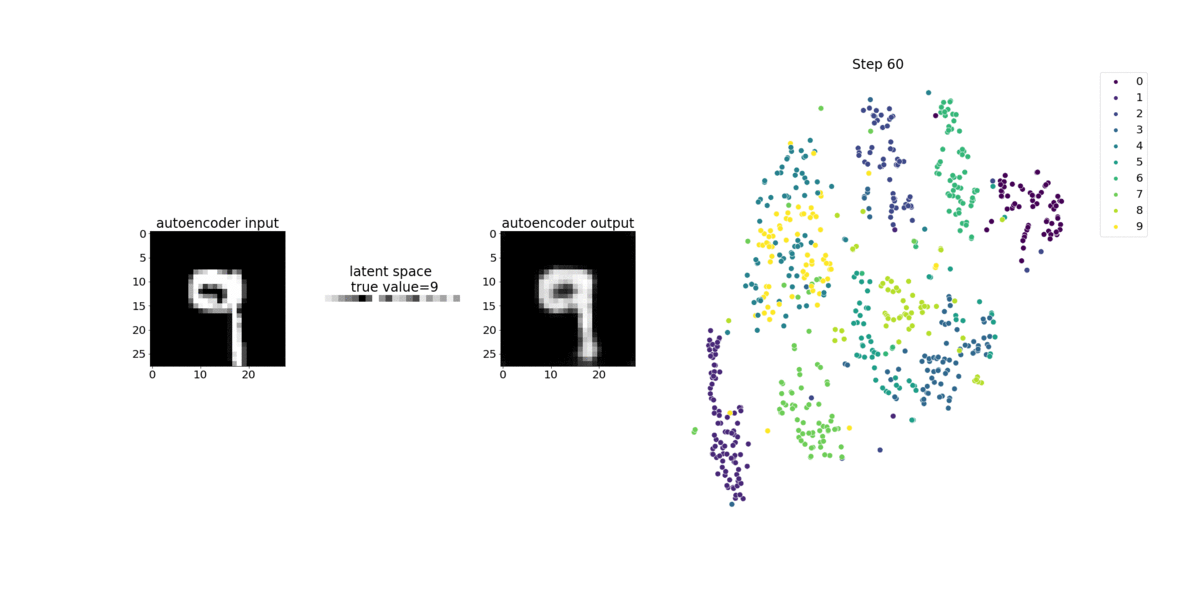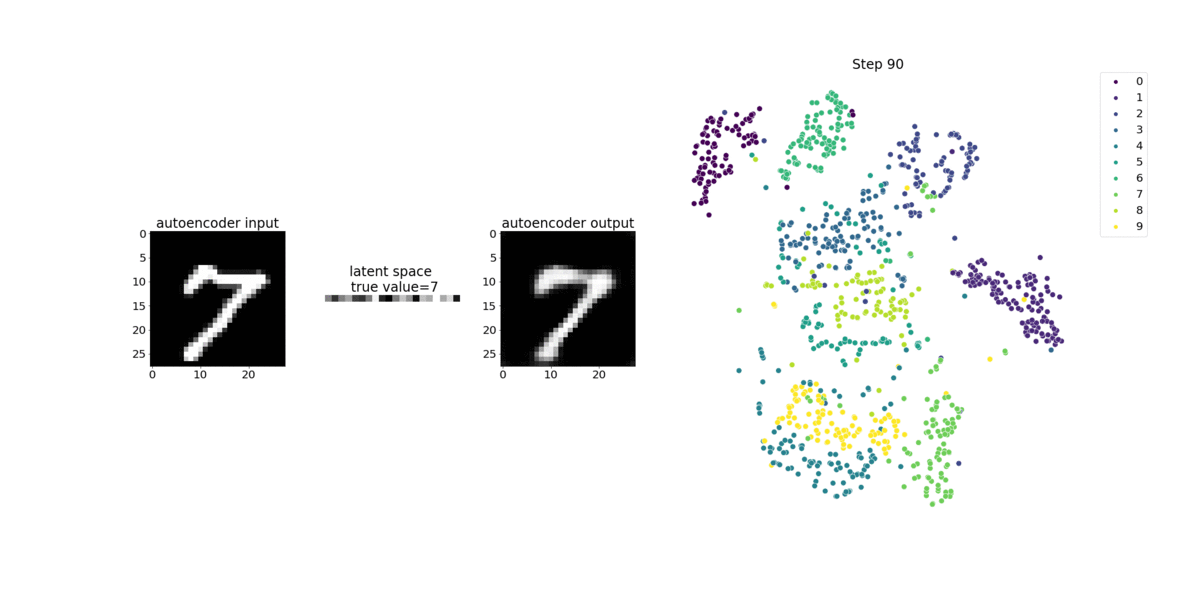
Questo notebook dimostra come SageMaker Debugger visualizza i tensori di un processo di apprendimento non supervisionato (o supervisionato autonomamente) su un set di dati di immagini MNIST di numeri scritti a mano.
Il modello di addestramento in questo notebook è un autoencoder convoluzionale con il framework MXNet. L'autoencoder convoluzionale ha una rete neurale convoluzionale a forma di collo di bottiglia che consiste in una parte encoder e una parte di decoder.
L'encoder in questo esempio ha due livelli di convoluzione per produrre una rappresentazione compressa (variabili latenti) delle immagini di input. In questo caso, l'encoder produce una variabile latente di dimensione (1, 20) da un'immagine di input originale di dimensioni (28, 28) e riduce significativamente la dimensione dei dati per l'addestramento di 40 volte.
Il decoder ha due livelli deconvoluzionali e assicura che le variabili latenti conservino le informazioni chiave ricostruendo le immagini di output.
L'encoder convoluzionale alimenta algoritmi di clustering con dimensioni ridotte dei dati di input, oltre a prestazioni di algoritmi di clustering come k-means, K-nn e T-distributed Stochastic Neighbor Embedding (T-sne).
In questo esempio di notebook viene illustrato come visualizzare le variabili latenti utilizzando Debugger, come illustrato nell'animazione seguente. Dimostra anche come l'algoritmo t-SNE classifica le variabili latenti in dieci cluster e le proietta in uno spazio bidimensionale. Lo schema di colori del grafico a dispersione sul lato destro dell'immagine riflette i valori reali per mostrare come il modello BERT e l'algoritmo T-sne organizzano le variabili latenti nei cluster.
Utilizzo di SageMaker Debugger per monitorare l'attenzione nell'addestramento del modello BERT
Le rappresentazioni di codifica bidirezionale da Transformers (BERT) è un modello di rappresentazione linguistica. Come indica il nome del modello, il modello BERT si basa sull'apprendimento del trasferimento e sul modello Transformer per Natural Language Processing (PNL).
Il modello BERT è pre-addestrato su compiti non supervisionati, come la previsione di parole mancanti in una frase o la previsione della frase successiva che naturalmente segue una frase precedente. I dati di addestramento contengono 3,3 miliardi di parole (token) di testo inglese da origini come Wikipedia e libri elettronici. Per un esempio semplice, il modello BERT può prestare molta attenzione ai token verbi appropriati o ai token pronome da un token soggetto.
Il modello BERT pre-addestrato può essere ottimizzato con un ulteriore livello di output per ottenere un addestramento di modelli all'avanguardia nelle attività PNL, come la risposta automatizzata alle domande, la classificazione dei testi e molti altri.
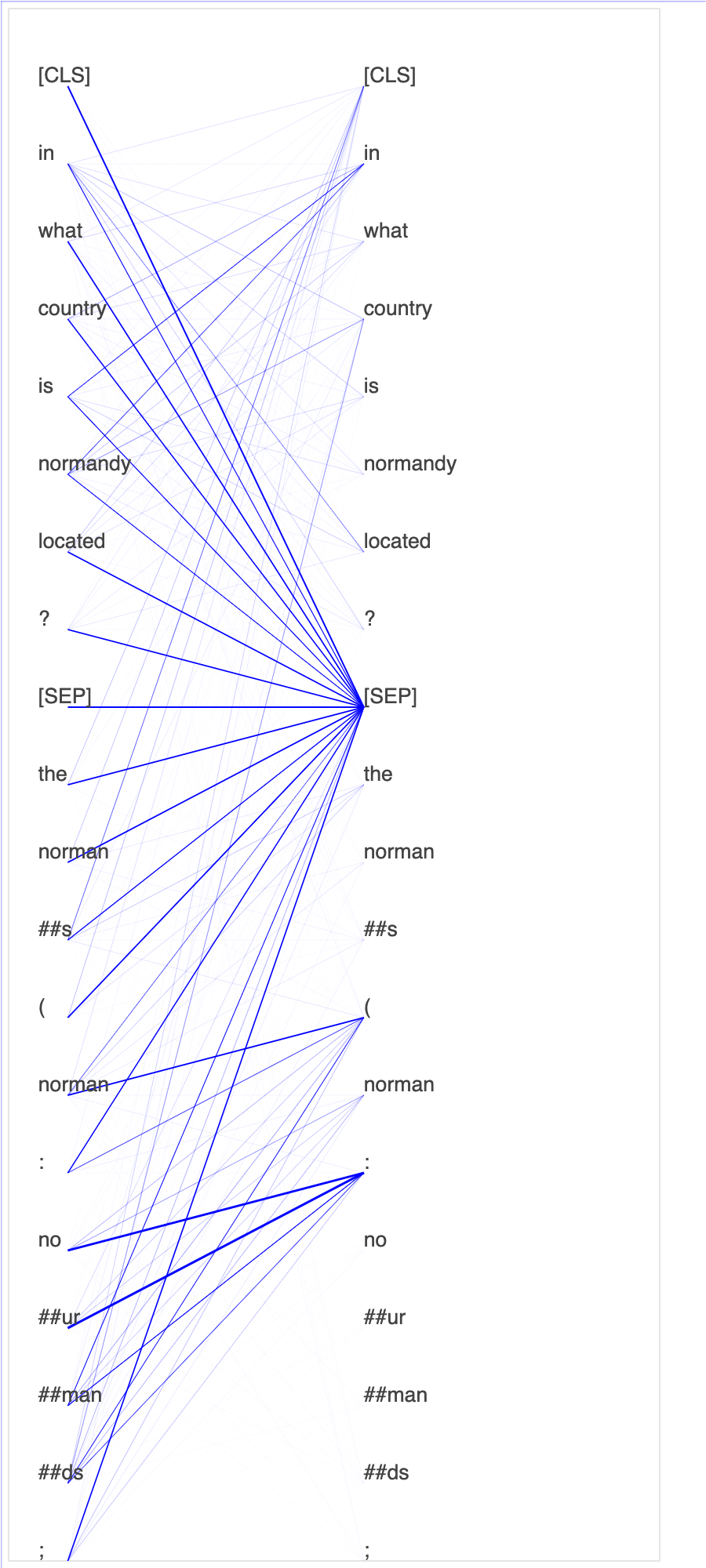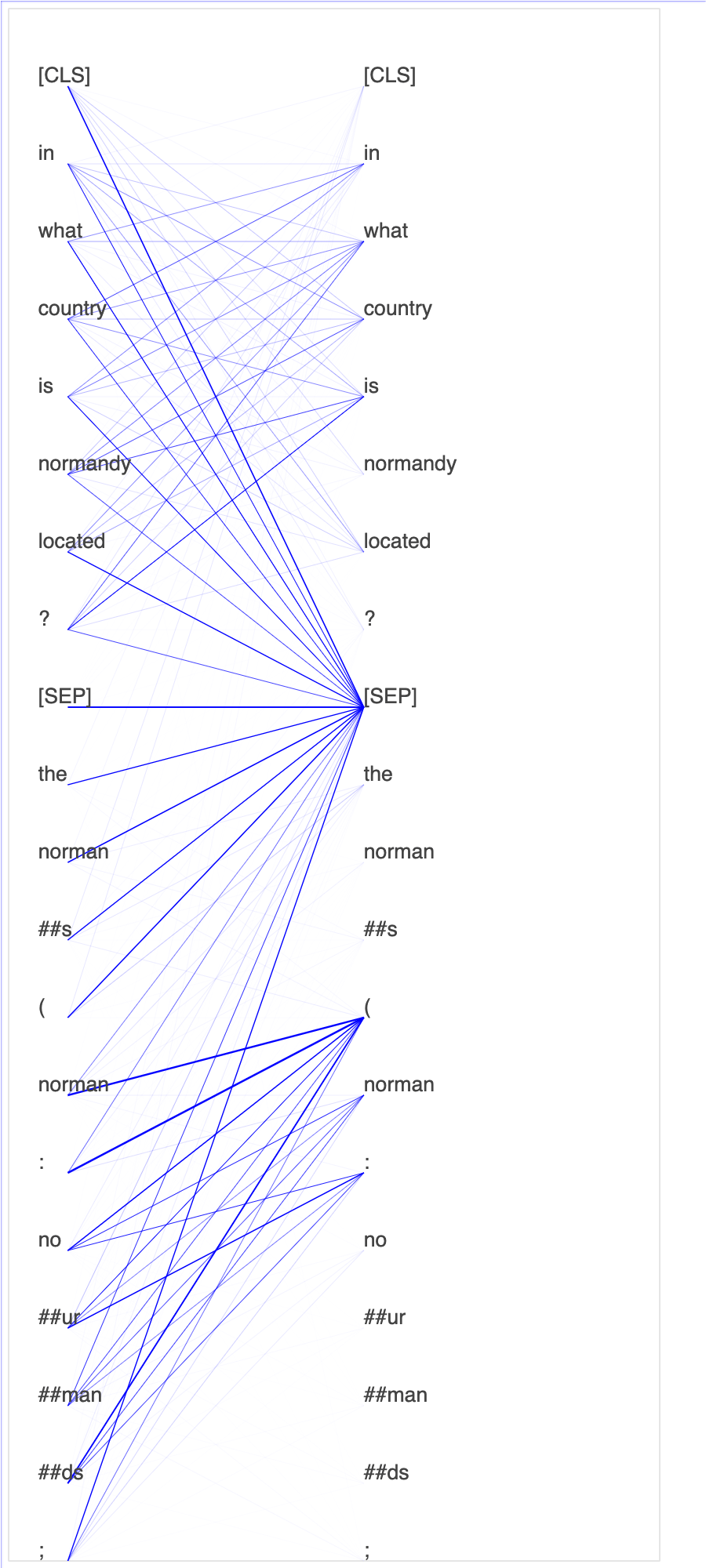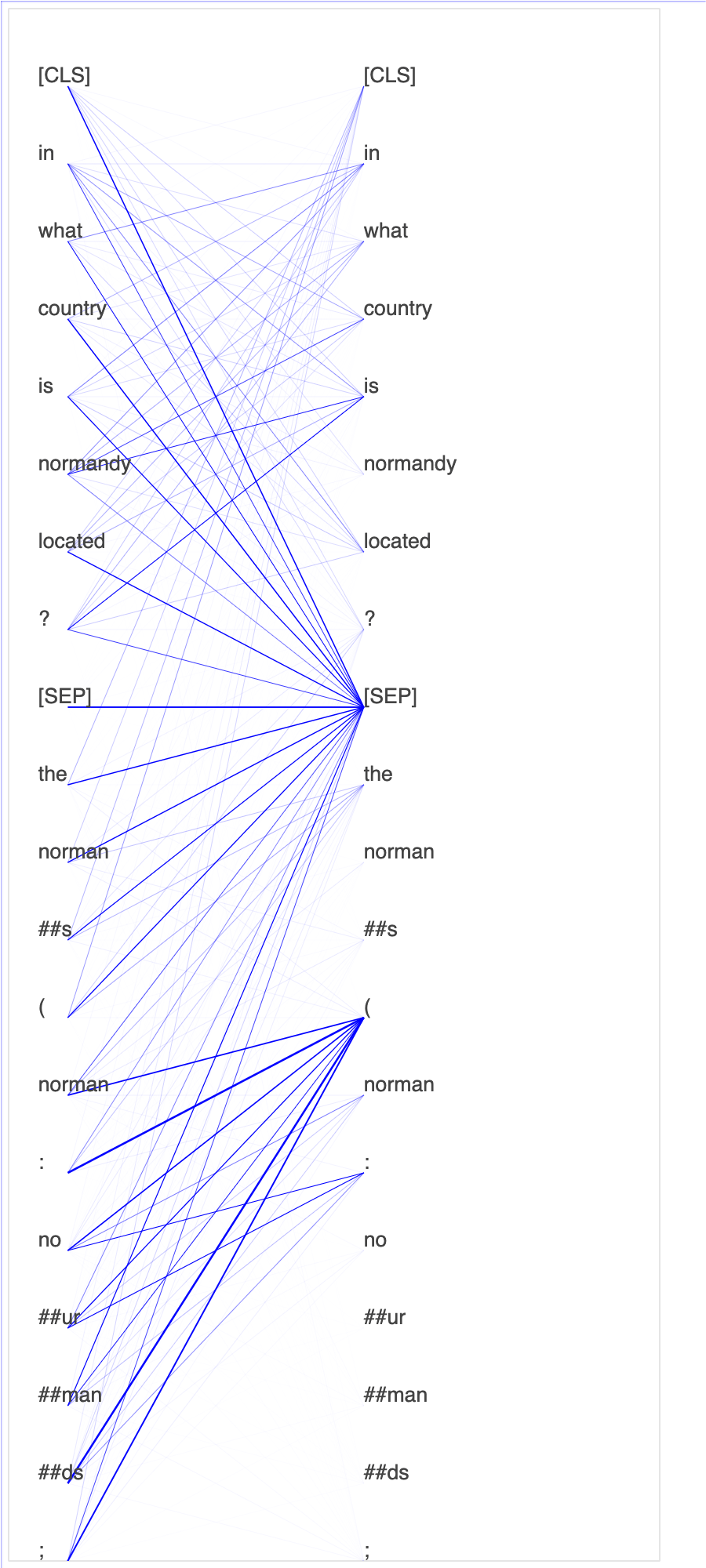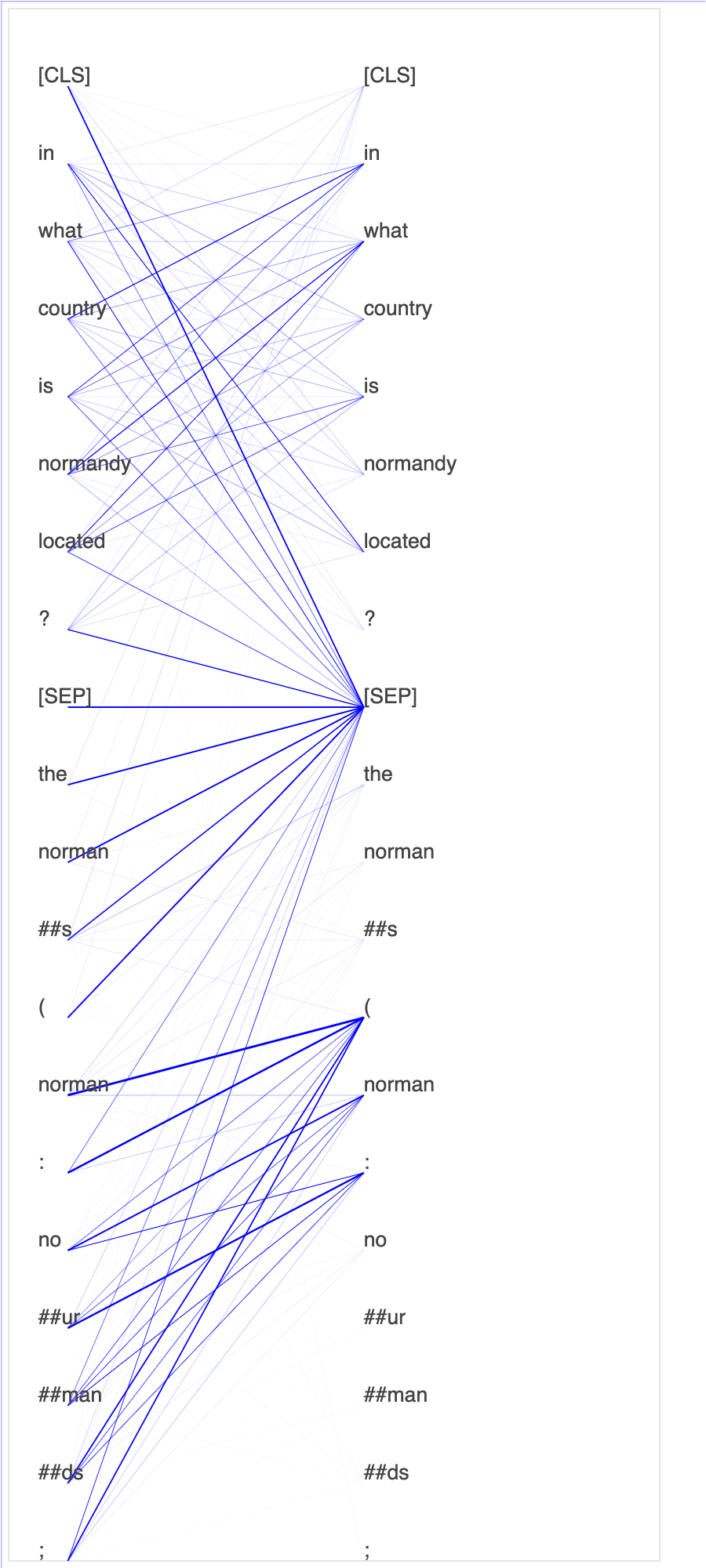
Debugger raccoglie i tensori dal processo di ottimizzazione. Nel contesto di NLP, si richiama l'attenzione sul peso dei neuroni.
Questo notebook dimostra come utilizzare il modello BERT pre-addestrato dallo zoo del modello GluonNLP
La tracciatura dei punteggi di attenzione e dei singoli neuroni nella query e nei vettori chiave può aiutare a identificare le cause delle previsioni errate del modello. Con SageMaker AI Debugger, puoi recuperare i tensori e tracciare in tempo reale la visualizzazione della testa di attenzione man mano che l'allenamento procede e capire cosa sta imparando il modello.
L'animazione seguente mostra i punteggi di attenzione dei primi 20 token di input per dieci iterazioni nel processo di addestramento fornito nell'esempio del notebook.
Utilizzo di SageMaker Debugger per visualizzare le mappe di attivazione delle classi nelle reti neurali convoluzionali (CNN)
Questo notebook dimostra come utilizzare SageMaker Debugger per tracciare mappe di attivazione delle classi per il rilevamento e la classificazione delle immagini nelle reti neurali convoluzionali (CNN). Nell'apprendimento profondo, una rete neurale convoluzionale (CNN o ConvNet) è una classe di reti neurali profonde, più comunemente applicata all'analisi di immagini visive. Una delle applicazioni che adotta le mappe di attivazione della classe è a guida autonoma e richiede il rilevamento istantaneo e la classificazione di immagini come segnali stradali, strade e ostacoli.
In questo taccuino, il PyTorch ResNet modello viene addestrato sul German Traffic Sign Dataset
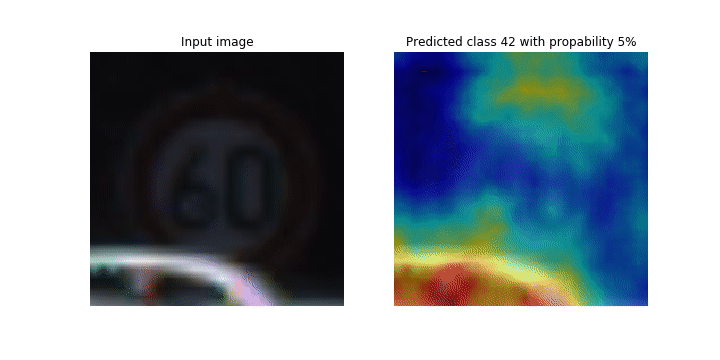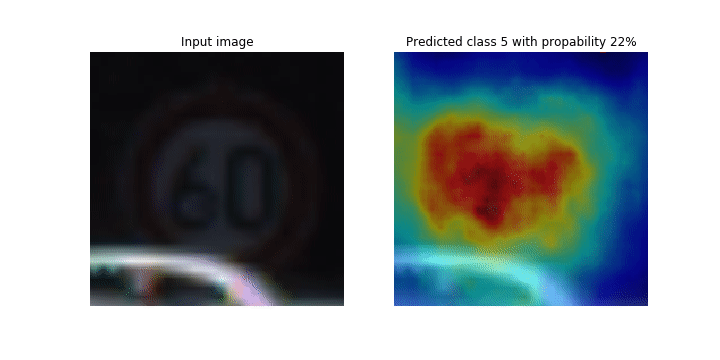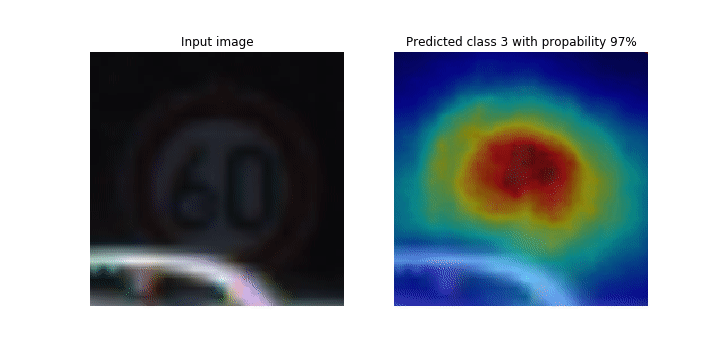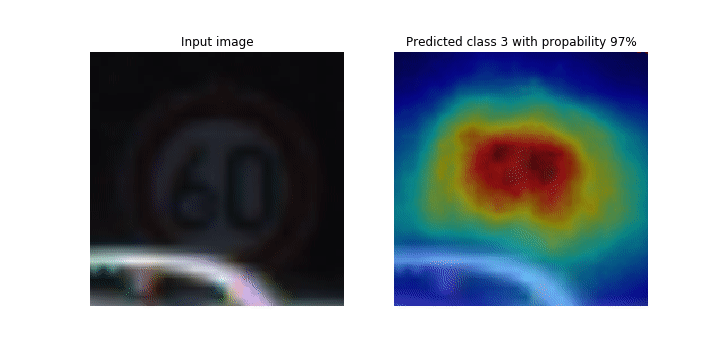
Durante il processo di addestramento, SageMaker Debugger raccoglie tensori per tracciare le mappe di attivazione della classe in tempo reale. Come mostrato nell'immagine animata, la mappa di attivazione della classe (detta anche mappa di salienza) evidenzia le Regioni con attivazione elevata in colore rosso.
Utilizzando i tensori catturati da Debugger, è possibile visualizzare l'evoluzione della mappa di attivazione durante l'addestramento del modello. Il modello inizia rilevando il bordo nell'angolo inferiore sinistro all'inizio del processo di addestramento. Man mano che l'allenamento procede, l'attenzione si sposta verso il centro e rileva il segnale del limite di velocità, e il modello prevede con successo l'immagine di input come Classe 3, che è una classe di segnali di limite di velocità, con un livello di confidenza del 97%. 60km/h
