Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Comprendi le opzioni per distribuire modelli e ottenere inferenze in Amazon SageMaker
Per aiutarti a iniziare a usare SageMaker Inference, consulta le sezioni seguenti che spiegano le opzioni per implementare il modello SageMaker e ottenere inferenze. La Opzioni di inferenza in Amazon SageMaker sezione può aiutarti a determinare quale funzionalità si adatta meglio al tuo caso d'uso per l'inferenza.
Puoi fare riferimento alla Risorse sezione per ulteriori informazioni sulla risoluzione dei problemi e di riferimento, blog ed esempi utili per iniziare e informazioni comuni. FAQs
Argomenti
Prima di iniziare
Questi argomenti presuppongono che tu abbia creato e preparato uno o più modelli di machine learning e che siano pronti per la distribuzione. Non è necessario addestrare il modello per implementarlo SageMaker e ottenere inferenze. SageMaker Se non disponi di un modello personale, puoi anche utilizzare gli algoritmi integrati o SageMaker i modelli preaddestrati.
Se sei nuovo SageMaker e non hai ancora scelto un modello da implementare, segui i passaggi del SageMaker tutorial Get Started with Amazon. Usa il tutorial per acquisire familiarità con la SageMaker gestione del processo di data science e con la distribuzione dei modelli. Per ulteriori informazioni sull'addestramento di un modello, consulta Addestramento di modelli.
Per ulteriori informazioni, riferimenti ed esempi, consulta Risorse.
Fasi per l’implementazione di un modello
Per gli endpoint di inferenza, il flusso di lavoro generale comprende:
Crea un modello in SageMaker Inference indicando gli artefatti del modello archiviati in Amazon S3 e un'immagine del contenitore.
Selezionare un'opzione di inferenza. Per ulteriori informazioni, consulta Opzioni di inferenza in Amazon SageMaker.
Crea una configurazione dell'endpoint di SageMaker inferenza scegliendo il tipo di istanza e il numero di istanze necessarie per l'endpoint. Puoi utilizzare Amazon SageMaker Inference Recommender per ottenere consigli sui tipi di istanze. Per inferenza serverless, devi solo fornire la configurazione di memoria necessaria in base alle dimensioni del modello.
Crea un endpoint di SageMaker inferenza.
Richiama il tuo endpoint per ricevere come risposta un'inferenza.
Il diagramma mostra il precedente flusso di lavoro:
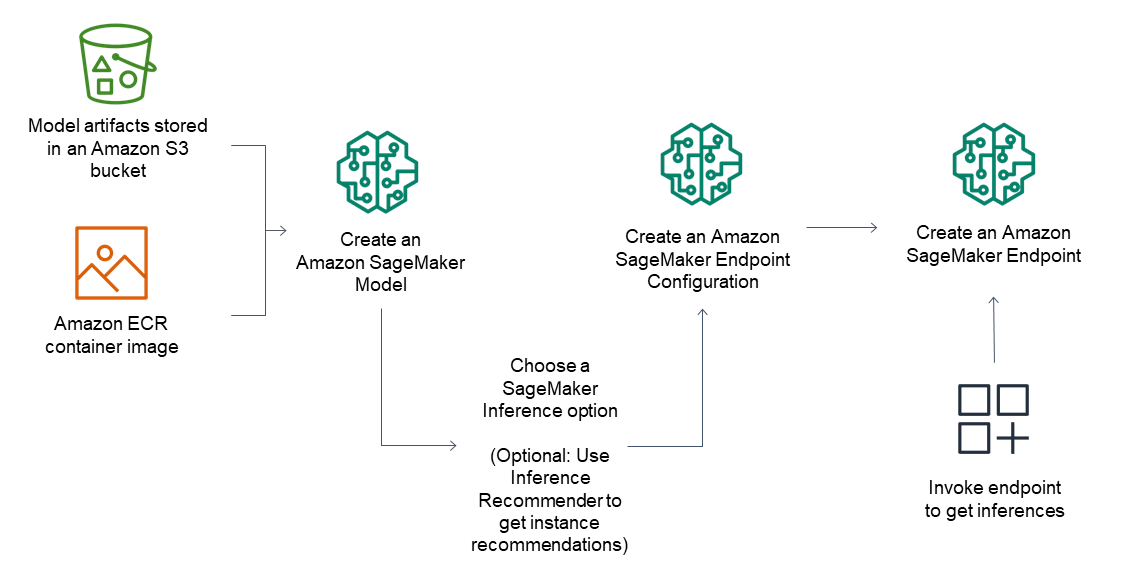
È possibile eseguire queste azioni utilizzando la AWS console AWS SDKs, SageMaker Python SDK AWS CloudFormation o. AWS CLI
Per l'inferenza in batch con la trasformazione in batch, punti agli artefatti del modello e ai dati di input e crei un processo di inferenza in batch. Invece di ospitare un endpoint per l'inferenza, invia le inferenze in una SageMaker posizione Amazon S3 di tua scelta.
