Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Valutazione del modello
Ora che hai addestrato e distribuito un modello utilizzando Amazon SageMaker AI, valuta il modello per assicurarti che generi previsioni accurate su nuovi dati. Per la valutazione del modello, utilizza il set di dati di test creato in Preparazione di un set di dati.
Valuta il modello implementato nei servizi di hosting AI SageMaker
Per valutare il modello e utilizzarlo in produzione, richiama l'endpoint con il set di dati di test e verifica se le inferenze ottenute restituiscono la precisione desiderata.
Per valutare il modello
-
Configura la seguente funzione per prevedere ogni riga del set di test. Nel seguente codice di esempio, l'argomento
rowsconsiste nello specificare il numero di righe da prevedere alla volta. Puoi modificarne il valore per eseguire un'inferenza in batch che utilizzi appieno la risorsa hardware dell'istanza.import numpy as np def predict(data, rows=1000): split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1)) predictions = '' for array in split_array: predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')]) return np.fromstring(predictions[1:], sep=',') -
Esegui il seguente codice per fare previsioni sul set di dati di test e tracciare un istogramma. Devi prendere solo le colonne delle funzionalità del set di dati di test, esclusa la colonna 0 per i valori effettivi.
import matplotlib.pyplot as plt predictions=predict(test.to_numpy()[:,1:]) plt.hist(predictions) plt.show()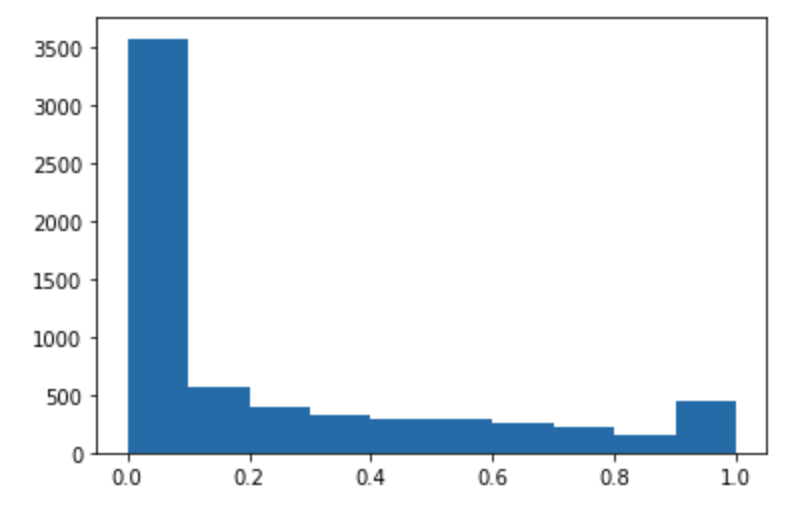
-
I valori previsti sono di tipo float. Per determinare
TrueoFalsein base ai valori float, devi impostare un valore limite. Come illustrato nel codice di esempio seguente, utilizzate la Scikit-learn libreria per restituire le metriche di confusione in uscita e il rapporto di classificazione con un limite di 0,5.import sklearn cutoff=0.5 print(sklearn.metrics.confusion_matrix(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0))) print(sklearn.metrics.classification_report(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))Questo dovrebbe restituire la seguente matrice di confusione:
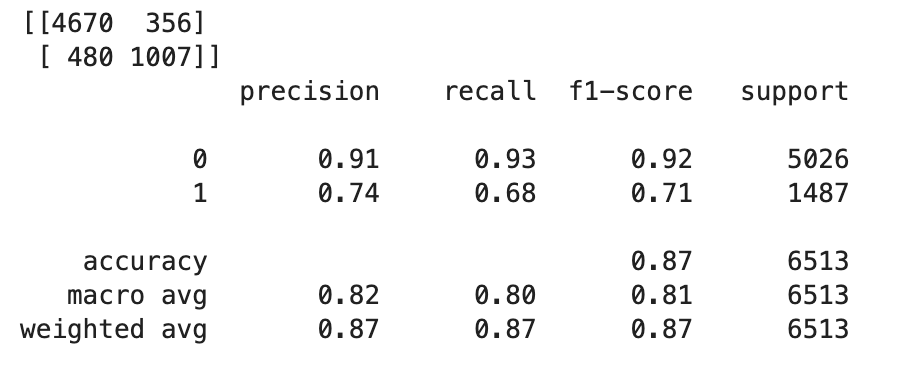
-
Per trovare il limite migliore con il set di test specificato, calcola la funzione di perdita di log della regressione logistica. La funzione di perdita di log è definita come la probabilità log negativa di un modello logistico che restituisce le probabilità di previsione per le etichette ground truth. Il seguente codice di esempio calcola numericamente e iterativamente i valori di perdita di log (
-(y*log(p)+(1-y)log(1-p)), doveyè l'etichetta vera epè una stima della probabilità dell'esempio di test corrispondente. Restituisce una perdita di log rispetto al grafico limite.import matplotlib.pyplot as plt cutoffs = np.arange(0.01, 1, 0.01) log_loss = [] for c in cutoffs: log_loss.append( sklearn.metrics.log_loss(test.iloc[:, 0], np.where(predictions > c, 1, 0)) ) plt.figure(figsize=(15,10)) plt.plot(cutoffs, log_loss) plt.xlabel("Cutoff") plt.ylabel("Log loss") plt.show()Ciò deve restituire la seguente curva di perdita di log.
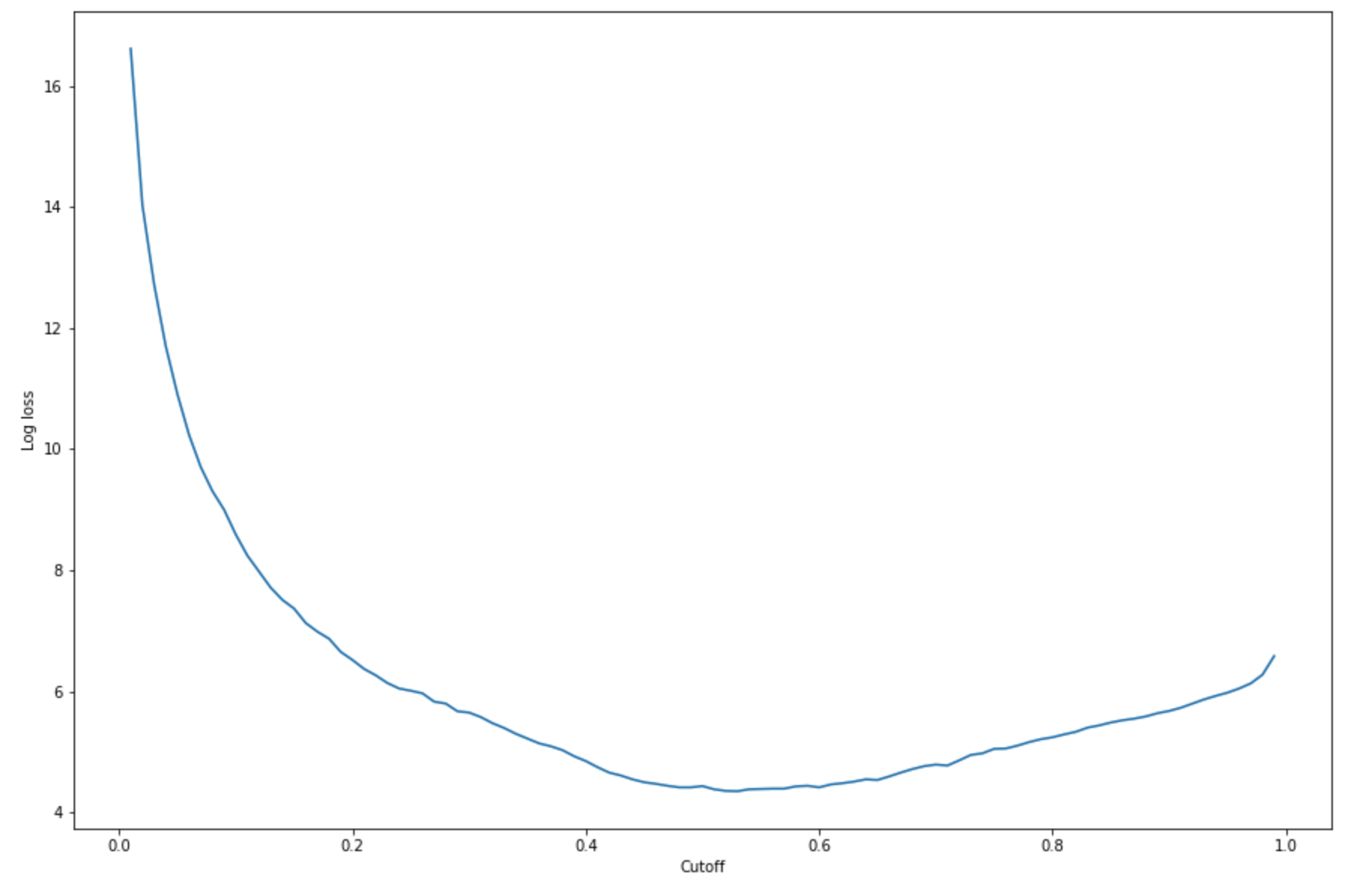
-
Trova i punti minimi della curva di errore utilizzando le funzioni NumPy
argminandmin:print( 'Log loss is minimized at a cutoff of ', cutoffs[np.argmin(log_loss)], ', and the log loss value at the minimum is ', np.min(log_loss) )Ciò dovrebbe restituire:
Log loss is minimized at a cutoff of 0.53, and the log loss value at the minimum is 4.348539186773897.Invece di calcolare e ridurre al minimo la funzione di perdita di log, puoi stimare una funzione di costo come alternativa. Ad esempio, se desideri addestrare un modello a eseguire una classificazione binaria per un problema aziendale, ad esempio un problema di predizione del tasso di abbandono dei clienti, puoi impostare pesi sugli elementi della matrice di confusione e calcolare di conseguenza la funzione di costo.
Ora hai addestrato, implementato e valutato il tuo primo modello di intelligenza artificiale. SageMaker
Suggerimento
Per monitorare la qualità del modello, la qualità dei dati e la deriva dei bias, usa Amazon SageMaker Model Monitor e SageMaker AI Clarify. Per ulteriori informazioni, consulta Amazon SageMaker Model Monitor, Monitor Data Quality, Monitor Model Quality, Monitor Bias Drift e Monitor Feature Attribution Drift.
Suggerimento
Per ottenere la revisione umana di previsioni ML a bassa attendibilità o di un campione casuale di previsioni, utilizza i flussi di lavoro di revisione umana di IA aumentata Amazon. Per ulteriori informazioni, consulta Using Amazon Augmented AI for Human Review.
