Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Come funziona l'algoritmo PCA
L'analisi delle componenti principali (PCA, Principal Component Analysis) è un algoritmo di apprendimento che riduce la dimensionalità (numero di caratteristiche) di un set di dati mantenendo la maggior quantità possibile di informazioni.
L'algoritmo PCA riduce le dimensioni individuando un nuovo insieme di caratteristiche denominate componenti, che sono compositi delle caratteristiche originali non correlate le une alle altre. La prima componente rappresenta la maggiore variabilità possibile nei dati, la seconda componente la seconda maggiore variabilità e così via.
Si tratta di un algoritmo di riduzione dimensionale non supervisionata. Nell'apprendimento non supervisionato, le etichette che possono essere associate con gli oggetti nel set di dati di addestramento non verranno utilizzate.
Considerato l'input di una matrice con righe
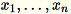 ciascuna con dimensione
ciascuna con dimensione 1 * d, i dati vengono partizionati in mini-batch di righe e distribuiti tra i nodi di addestramento (worker). Quindi, ogni worker calcola un riepilogo dei propri dati. I riepiloghi dei diversi worker vengono quindi uniti in un'unica soluzione al termine del calcolo.
Modalità
L'algoritmo PCA di Amazon SageMaker AI utilizza una delle due modalità per calcolare questi riepiloghi, a seconda della situazione:
-
regular (normale): per i set di dati con dati a densità bassa e un numero modesto di osservazioni e caratteristiche.
-
randomized (randomizzata): per i set di dati con un elevato numero di osservazioni e caratteristiche. Questo modo adotta un algoritmo di approssimazione.
Come ultima fase, l'algoritmo esegue la decomposizione dei singoli valori sulla soluzione unificata, dalla quale derivano le componenti principali.
Modalità 1: regular (normale)
I worker calcolano insieme
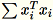 e
e
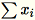 .
.
Nota
Poiché
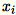 sono vettori della riga
sono vettori della riga 1 * d,
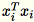 è una matrice (non un valore scalare). L'utilizzo dei vettori delle righe nel codice permette di ottenere il caching efficiente.
è una matrice (non un valore scalare). L'utilizzo dei vettori delle righe nel codice permette di ottenere il caching efficiente.
La matrice di covarianza viene calcolata come
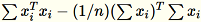 e i relativi vettori delle singole
e i relativi vettori delle singole num_components superiori formano il modello.
Nota
Se subtract_mean è False, si evita di calcolare e sottrarre
.
Utilizza questo algoritmo quando la dimensione d dei vettori è sufficientemente piccola affinché
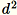 rientri in memoria.
rientri in memoria.
Modalità 2: randomized (randomizzata)
Quando il numero di caratteristiche nel set di dati di input è elevato, si utilizza un metodo di approssimazione del parametro di covarianza. Per ogni mini-batch
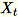 di dimensione
di dimensione b * d, si inizializza in modo casuale una matrice (num_components + extra_components) * b da moltiplicare per ogni mini-batch per creare una matrice (num_components + extra_components) * d. La somma di queste matrici viene calcolata dai worker e i server eseguono la SVD (Singular Value Decomposition) sulla matrice (num_components + extra_components) * d finale. I vettori delle singole num_components in alto a destra sono l'approssimazione dei vettori singoli superiori della matrice di input.
Consenti
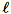
= num_components + extra_components. Considerato un mini-batch
di dimensione b * d, il worker disegna una matrice casuale
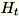 di dimensione
di dimensione
 . A seconda se l'ambiente utilizza una GPU o un CPU e in base alla grandezza della dimensione, la matrice è una matrice a segni casuali dove ogni voce è
. A seconda se l'ambiente utilizza una GPU o un CPU e in base alla grandezza della dimensione, la matrice è una matrice a segni casuali dove ogni voce è +-1 o una FJLT (Fast Johnson-Lindenstrauss Transform; per informazioni consulta FJLT Transforms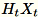 e mantiene
e mantiene
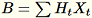 . Il worker mantiene anche
. Il worker mantiene anche
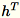 , la somma delle colonne di
, la somma delle colonne di
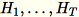 (dove
(dove T è il numero totale di mini-batch) e s, la somma di tutte le righe di input. Dopo l'elaborazione dell'intero shard di dati, il worker invia al server B, h, s e n (il numero di righe di input).
Indica i diversi input al server come
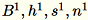 Il server calcola
Il server calcola B, h, s, n le somme dei rispettivi input. Quindi, calcola
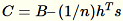 e rileva la relativa decomposizione dei singoli valori. I vettori singoli in alto a destra e i valori singoli di
e rileva la relativa decomposizione dei singoli valori. I vettori singoli in alto a destra e i valori singoli di C vengono utilizzati come soluzione approssimativa del problema.
