Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Registra metriche, parametri e MLflow modelli durante l'allenamento
Dopo esserti connesso al server di MLflow tracciamento, puoi MLflow SDK utilizzarlo per registrare metriche, parametri e MLflow modelli.
Registra le metriche di allenamento
Utilizzale mlflow.log_metric all'interno di una sessione MLflow di allenamento per tenere traccia delle metriche. Per ulteriori informazioni sull'utilizzo MLflow delle metriche di registrazione, consulta. mlflow.log_metric
with mlflow.start_run(): mlflow.log_metric("foo",1) print(mlflow.search_runs())
Questo script dovrebbe creare un esperimento, eseguire e stampare un output simile al seguente:
run_id experiment_id status artifact_uri ... tags.mlflow.source.name tags.mlflow.user tags.mlflow.source.type tags.mlflow.runName 0 607eb5c558c148dea176d8929bd44869 0 FINISHED s3://dddd/0/607eb5c558c148dea176d8929bd44869/a... ... file.py user-id LOCAL experiment-code-name
All'interno dell'MLflowinterfaccia utente, questo esempio dovrebbe essere simile al seguente:
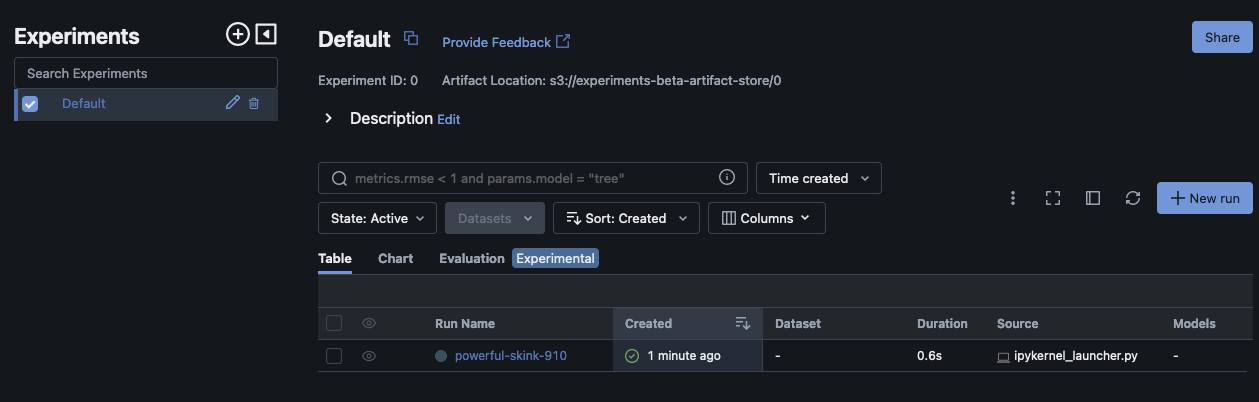
Scegli Run Name per visualizzare ulteriori dettagli sulla corsa.
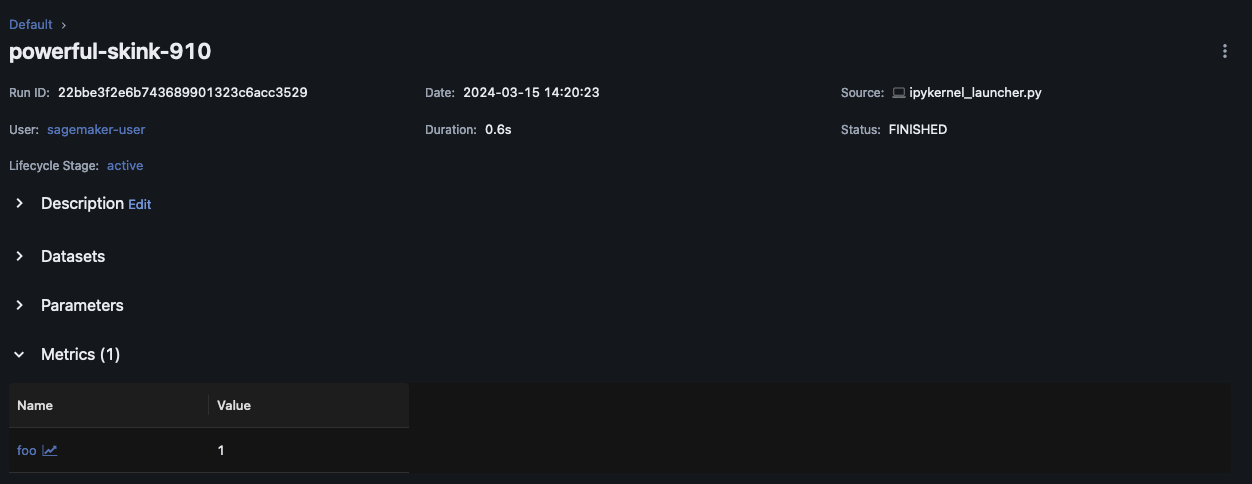
Parametri e modelli di log
Nota
L'esempio seguente richiede che l'ambiente disponga di s3:PutObject autorizzazioni. Questa autorizzazione deve essere associata al IAM ruolo che l'MLflowSDKutente assume quando accede o si federa al proprio account. AWS Per ulteriori informazioni, consulta Esempi di policy relative a utenti e ruoli.
L'esempio seguente illustra un flusso di lavoro di formazione di base sull'utilizzo di un modello SKLearn e mostra come tenere traccia di tale modello durante l'esecuzione di un MLflow esperimento. Questo esempio registra parametri, metriche e artefatti del modello.
import mlflow from mlflow.models import infer_signature import pandas as pd from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # This is the ARN of the MLflow Tracking Server you created mlflow.set_tracking_uri(your-tracking-server-arn) mlflow.set_experiment("some-experiment") # Load the Iris dataset X, y = datasets.load_iris(return_X_y=True) # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Define the model hyperparameters params = {"solver": "lbfgs", "max_iter": 1000, "multi_class": "auto", "random_state": 8888} # Train the model lr = LogisticRegression(**params) lr.fit(X_train, y_train) # Predict on the test set y_pred = lr.predict(X_test) # Calculate accuracy as a target loss metric accuracy = accuracy_score(y_test, y_pred) # Start an MLflow run and log parameters, metrics, and model artifacts with mlflow.start_run(): # Log the hyperparameters mlflow.log_params(params) # Log the loss metric mlflow.log_metric("accuracy",accuracy) # Set a tag that we can use to remind ourselves what this run was for mlflow.set_tag("Training Info","Basic LR model for iris data") # Infer the model signature signature = infer_signature(X_train, lr.predict(X_train)) # Log the model model_info = mlflow.sklearn.log_model( sk_model=lr, artifact_path="iris_model", signature=signature, input_example=X_train, registered_model_name="tracking-quickstart", )
All'interno dell'MLflowinterfaccia utente, scegli il nome dell'esperimento nel riquadro di navigazione a sinistra per esplorare tutte le esecuzioni associate. Scegli il nome dell'esecuzione per visualizzare ulteriori informazioni su ogni esecuzione. Per questo esempio, la pagina di esecuzione dell'esperimento per questa esecuzione dovrebbe essere simile alla seguente.
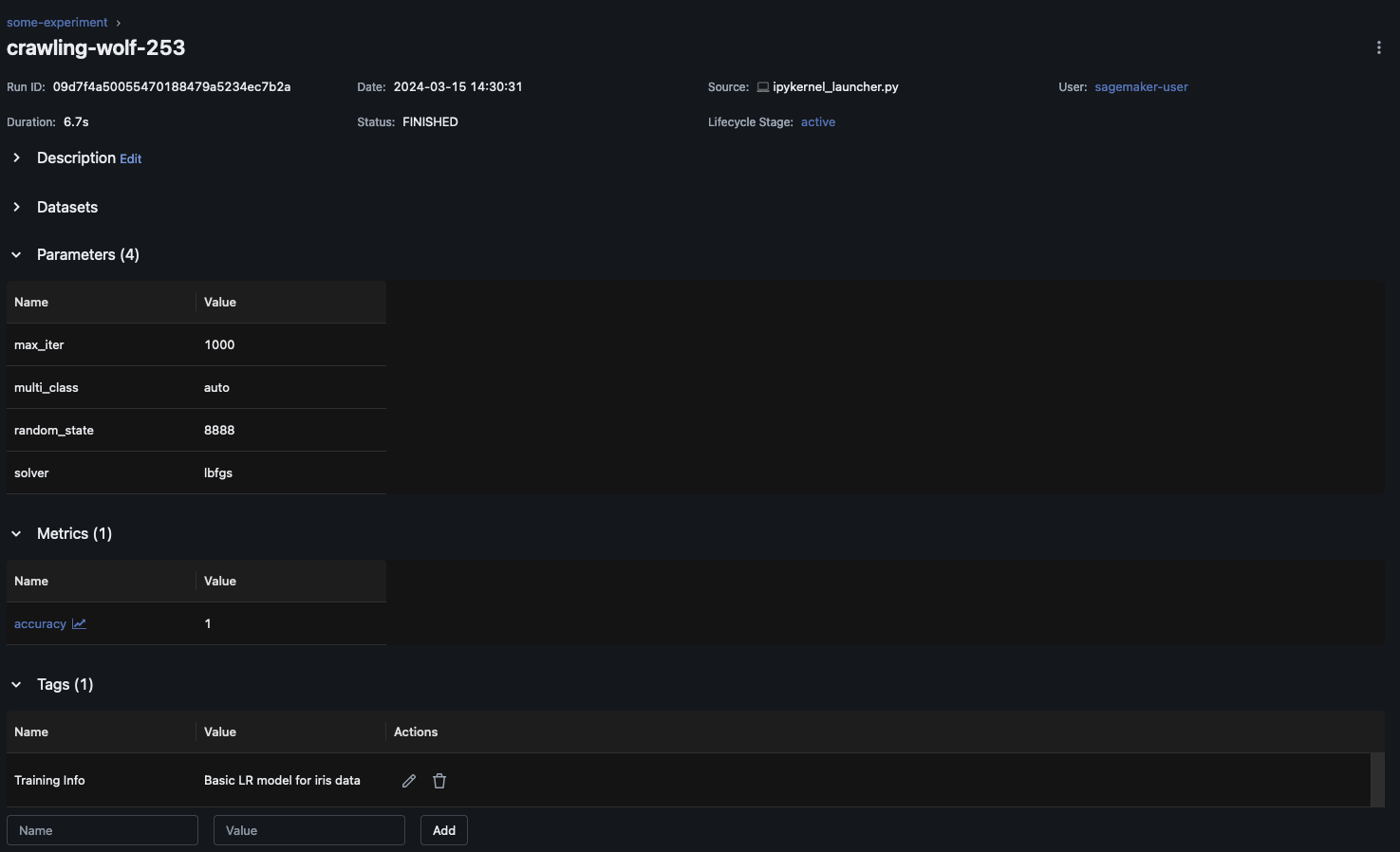
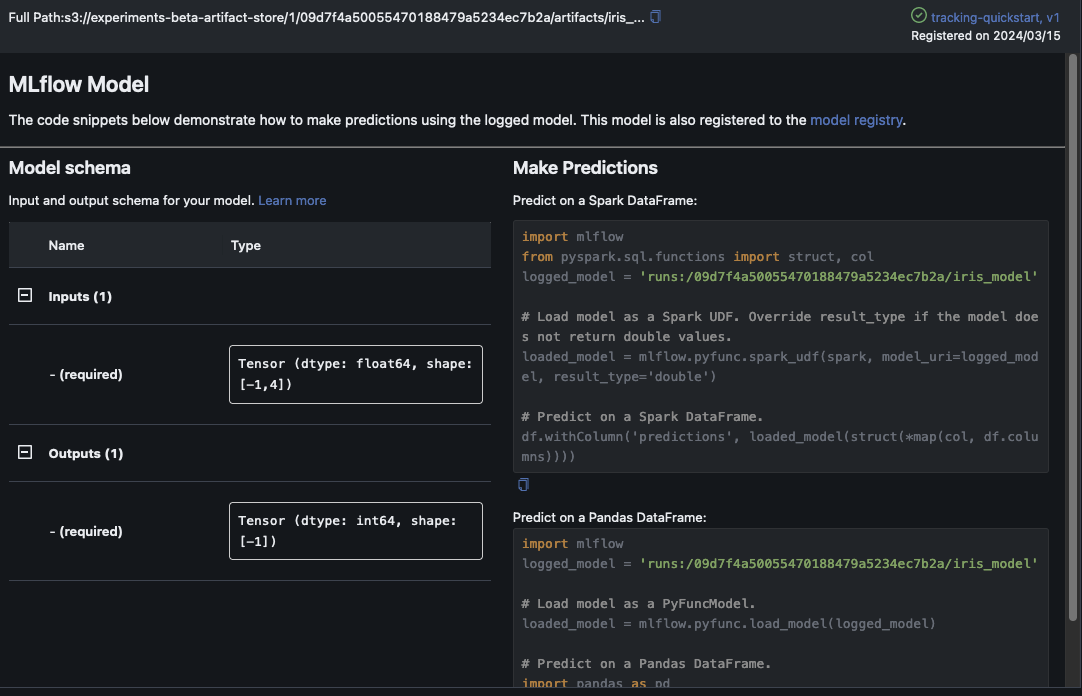
Questo esempio registra il modello di regressione logistica. All'interno dell'MLflowinterfaccia utente, dovresti vedere anche gli artefatti del modello registrati.