Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Scelta di una modalità di input e di un'unità di archiviazione
La migliore origine dati per il processo di addestramento dipende dalle caratteristiche del carico di lavoro, come le dimensioni del set di dati, il formato del file, le dimensioni medie dei file, la durata dell'addestramento, lo schema di lettura sequenziale o casuale del data loader e la velocità con cui il modello può consumare i dati di addestramento. Le seguenti best practice forniscono linee guida per iniziare a utilizzare la modalità di input e il servizio di archiviazione dati più adatti al tuo caso d'uso.
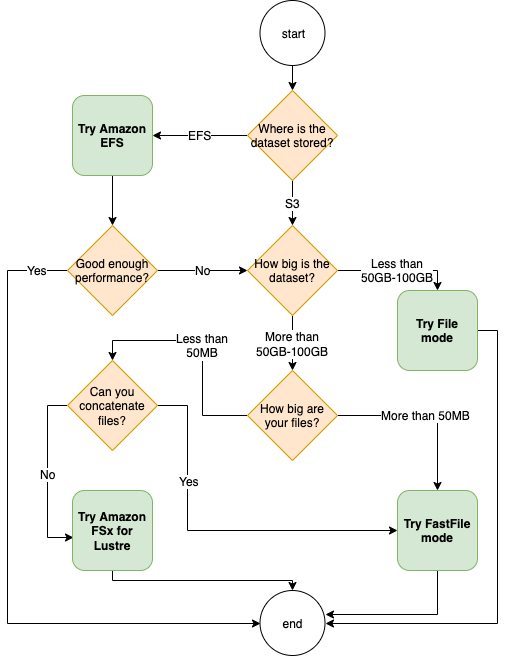
Quando usare Amazon EFS
Se il tuo set di dati è archiviato in Amazon Elastic File System, potresti avere un'applicazione di preelaborazione o annotazioni che utilizza Amazon EFS per lo storage. Puoi eseguire un processo di formazione configurato con un canale dati che punta al EFS file system Amazon. Per ulteriori informazioni, consulta Accelerare la formazione su Amazon SageMaker utilizzando Amazon FSx for Lustre e i EFS file system Amazon
Uso della modalità dei file per piccoli set di dati
Se il set di dati è archiviato in Amazon Simple Storage Service e il suo volume complessivo è relativamente piccolo (ad esempio, meno di 50-100 GB), prova a utilizzare la modalità dei file. Il sovraccarico derivante dal download di un set di dati da 50 GB può variare in base al numero totale di file. Ad esempio, se un set di dati è suddiviso in partizioni da 100 MB, sono necessari circa 5 minuti. L'accettabilità di questo sovraccarico all’avvio dipende principalmente dalla durata complessiva del processo di addestramento, in quanto una fase di addestramento più lunga significa una fase di download proporzionalmente più piccola.
Serializzazione di molti file di piccole dimensioni
Se le dimensioni del set di dati sono ridotte (inferiori a 50-100 GB), ma sono composti da molti file di piccole dimensioni (inferiori a 50 MB per file), il sovraccarico di download in modalità dei file aumenta, poiché ogni file deve essere scaricato singolarmente da Amazon Simple Storage Service sul volume delle istanze di addestramento. Per ridurre questo sovraccarico e il tempo di attraversamento dei dati in generale, prendi in considerazione la serializzazione di gruppi di file così piccoli in contenitori di file meno grandi (ad esempio 150 MB per file) utilizzando formati di file come TFRecord
Quando utilizzare la modalità dei file veloce
Per set di dati più grandi con file più grandi (più di 50 MB per file), la prima opzione è provare la modalità file veloce, che è più semplice da usare rispetto FSx a Lustre perché non richiede la creazione di un file system o la connessione a unVPC. La modalità dei file veloce è ideale per container di file di grandi dimensioni (superiori a 150 MB) e può funzionare bene anche con file di dimensioni superiori a 50 MB. Poiché la modalità file veloce fornisce un'POSIXinterfaccia, supporta letture casuali (lettura di intervalli di byte non sequenziali). Tuttavia, questo non è il caso d'uso ideale e il throughput potrebbe essere inferiore rispetto alle letture sequenziali. Tuttavia, se utilizzi un modello ML relativamente ampio e con un uso intensivo di calcolo, la modalità file veloce potrebbe comunque essere in grado di saturare la larghezza di banda effettiva della pipeline di addestramento e non creare un collo di bottiglia di I/O. Dovrai sperimentare e verificare. Per passare dalla modalità file alla modalità file veloce (e viceversa), basta aggiungere (o rimuovere) il input_mode='FastFile' parametro mentre si definisce il canale di input utilizzando SageMaker PythonSDK:
sagemaker.inputs.TrainingInput(S3_INPUT_FOLDER, input_mode = 'FastFile')
Quando usare Amazon FSx for Lustre
Se il set di dati è troppo grande per la modalità file, contiene molti file di piccole dimensioni che non è possibile serializzare facilmente o utilizza un modello di accesso alla lettura casuale, FSx for Lustre è una buona opzione da prendere in considerazione. Il suo file system è scalabile fino a centinaia di gigabyte al secondo (GB/s) di velocità effettiva e milioni diIOPS, una soluzione ideale quando si hanno molti file di piccole dimensioni. Tuttavia, tieni presente che potrebbe esserci un problema di avvio a freddo dovuto al lazy loading e al sovraccarico di configurazione e inizializzazione del file system for Lustre. FSx
Suggerimento
Per ulteriori informazioni, consulta Scegli la migliore fonte di dati per il tuo lavoro di SageMaker formazione su Amazon
