Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Meccanismo di classificazione quando si utilizza una combinazione di parallelismo di pipeline e parallelismo tensoriale
Questa sezione spiega come funziona il meccanismo di classificazione del parallelismo dei modelli con il parallelismo tensoriale. Si tratta di un'estensione di Ranking Basicssmp.tp_rank() tensor parallel rank, per smp.pp_rank() pipeline parallel rank e per reduced-data parallel rank. smp.rdp_rank() I gruppi di processi di comunicazione corrispondenti sono gruppo parallelo dei tensori (TP_GROUP), gruppo parallelo di pipeline (PP_GROUP) e gruppo parallelo dei dati ridotti (RDP_GROUP). I gruppi sono definiti come segue:
-
Un gruppo parallelo dei tensori (
TP_GROUP) è un sottoinsieme divisibile in modo uniforme del gruppo parallelo dei dati, sul quale avviene la distribuzione parallela tensoriale dei moduli. Quando il grado di parallelismo della pipeline è 1,TP_GROUPè uguale al gruppo parallelo del modello (MP_GROUP). -
Un gruppo parallelo di pipeline (
PP_GROUP) è il gruppo di processi su cui avviene il parallelismo della pipeline. Quando il grado di parallelismo tensoriale è 1,PP_GROUPè uguale aMP_GROUP. -
Un gruppo parallelo dei dati ridotti (
RDP_GROUP) è un insieme di processi che contengono sia le stesse partizioni di parallelismo della pipeline che le stesse partizioni parallele tensoriali ed eseguono il parallelismo dei dati tra di loro. Questo è chiamato gruppo parallelo dei dati ridotti perché è un sottoinsieme dell'intero gruppo di parallelismo dei datiDP_GROUP. Per i parametri del modello distribuito all'interno diTP_GROUP, l'operazioneallreducedi gradiente viene eseguita solo per il gruppo parallelo dei dati ridotti, mentre per i parametri che non sono distribuiti, il gradienteallreduceavviene sull'interoDP_GROUP. -
Un gruppo parallelo del modello (
MP_GROUP) si riferisce a un gruppo di processi che memorizzano collettivamente l'intero modello. Consiste nell'unione degliPP_GROUPdi tutte le classificazioni che fanno parte del processo correnteTP_GROUP. Quando il grado di parallelismo tensoriale è 1,MP_GROUPè equivalente aPP_GROUPÈ inoltre coerente con la definizione esistente diMP_GROUPdelle versioni precedentismdistributed. Nota che ilTP_GROUPcorrente è un sottoinsieme sia dellaDP_GROUPcorrente che delMP_GROUPcorrente.
Per saperne di più sul processo di comunicazione APIs nella libreria di parallelismo dei SageMaker modelli, consulta Common API
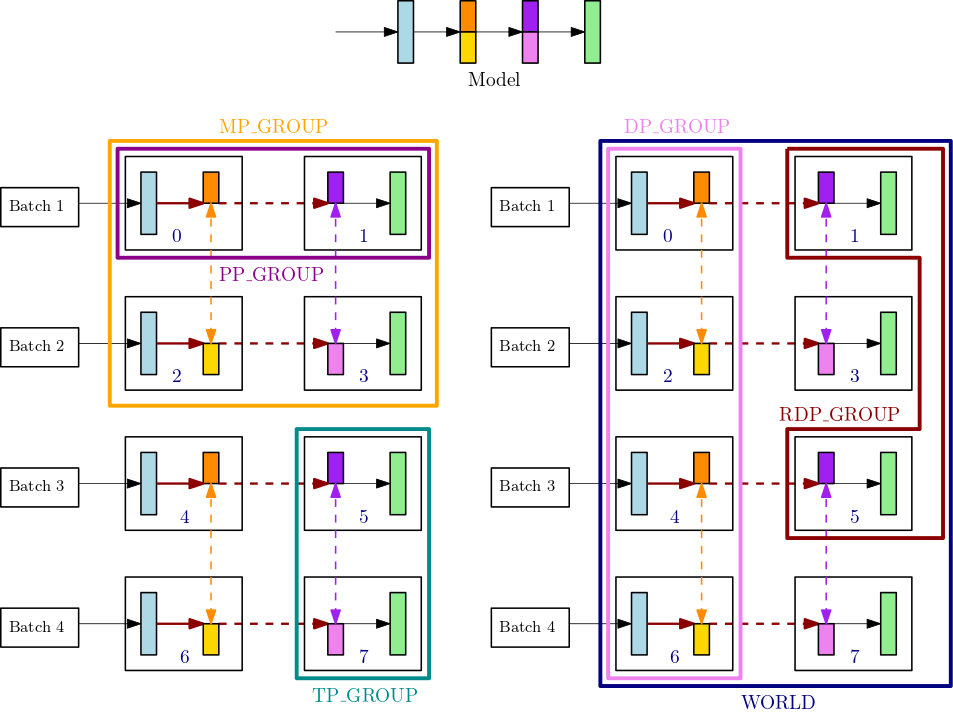
Ad esempio, considerate i gruppi di processi per un singolo nodo con 8GPUs, dove il grado di parallelismo tensoriale è 2, il grado di parallelismo della pipeline è 2 e il grado di parallelismo dei dati è 4. La parte centrale superiore della figura precedente mostra un esempio di modello con 4 livelli. Le parti in basso a sinistra e in basso a destra della figura illustrano il modello a 4 strati distribuito su 4 GPUs utilizzando sia il parallelismo della pipeline che il parallelismo tensoriale, dove il parallelismo tensoriale viene utilizzato per i due strati intermedi. Queste due figure inferiori sono semplici copie che illustrano le diverse linee di confine dei gruppi. Il modello partizionato viene replicato per il parallelismo dei dati su 0-3 e 4-7. GPUs La figura in basso a sinistra mostra le definizioni di MP_GROUP, PP_GROUP, e TP_GROUP. La figura in basso a destra mostraRDP_GROUP, DP_GROUP e sullo stesso set di. WORLD GPUs I gradienti per i livelli e le porzioni di livello che hanno lo stesso colore vengono allreduce assieme per il parallelismo dei dati. Ad esempio, il primo livello (blu chiaro) riceve le operazioni allreduce attraverso DP_GROUP, mentre la sezione arancione scuro del secondo livello trasmette solo le operazioni allreduce all'interno del relativo processo RDP_GROUP. Le frecce in grassetto rosso scuro rappresentano i tensori con il batch del loro insieme TP_GROUP.
GPU0: pp_rank 0, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 0 GPU1: pp_rank 1, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 1 GPU2: pp_rank 0, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 2 GPU3: pp_rank 1, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 3 GPU4: pp_rank 0, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 0 GPU5: pp_rank 1, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 1 GPU6: pp_rank 0, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 2 GPU7: pp_rank 1, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 3
In questo esempio, il parallelismo della pipeline si verifica tra le GPU coppie (0,1); (2,3); (4,5) e (6,7). Inoltre, il parallelismo dei dati (allreduce) avviene tra GPUs 0, 2, 4, 6 e indipendentemente su 1, 3, 5, 7. GPUs Il parallelismo tensoriale si verifica su sottoinsiemi di DP_GROUP s, tra le GPU coppie (0,2); (1,3); (4,6) e (5,7).
