Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Parallelismo dei dati partizionati
Il parallelismo dei dati condivisi è una tecnica di addestramento distribuito che consente di risparmiare memoria che suddivide lo stato di un modello (parametri del modello, gradienti e stati dell'ottimizzatore) in un gruppo parallelo di dati. GPUs
Nota
Il parallelismo dei dati suddivisi è disponibile nella libreria di parallelismo dei modelli v1.11.0 e versioni successive. PyTorch SageMaker
Quando si ridimensiona il processo di formazione su un cluster di GPU di grandi dimensioni, è possibile ridurre l'ingombro di memoria per GPU del modello suddividendo lo stato di addestramento del modello su più livelli. GPUs Ciò offre due vantaggi: è possibile utilizzare modelli più grandi, che altrimenti esaurirebbero la memoria con il parallelismo dei dati standard, oppure è possibile aumentare la dimensione del batch utilizzando la memoria della GPU liberata.
La tecnica standard di parallelismo dei dati replica gli stati di addestramento GPUs in tutto il gruppo parallelo di dati ed esegue l'aggregazione del gradiente in base all'operazione. AllReduce Il parallelismo dei dati partizionati modifica la procedura di addestramento distribuito standard parallelo ai dati per tenere conto della natura di partizionamento degli stati dell'ottimizzatore. Un gruppo di classificazioni sui cui gli stati del modello e dell'ottimizzatore sono partizionati viene chiamato gruppo di partizione. La tecnica di parallelismo dei dati frammentati suddivide i parametri addestrabili di un modello e i gradienti e gli stati di ottimizzazione corrispondenti all'interno del gruppo di sharding. GPUs
SageMaker L'intelligenza artificiale raggiunge il parallelismo condiviso dei dati attraverso l'implementazione di MIC, di cui si parla nel post sul blog Near-linear scaling of gigantic-model training on. AWSAWSAllGather Dopo il passaggio in avanti o all'indietro di ogni livello, MiCS partiziona nuovamente i parametri per risparmiare memoria della GPU. Durante il passaggio all'indietro, i MIC riducono i gradienti e li suddividono simultaneamente attraverso l'operazione. GPUs ReduceScatter Infine, MiCS applica i gradienti locali ridotti e partizionati alle corrispondenti partizioni di parametri locali, utilizzando le partizioni locali degli stati dell'ottimizzatore. Per ridurre il sovraccarico di comunicazione, la libreria di parallelismo dei SageMaker modelli precarica i livelli successivi in avanti o indietro e sovrappone la comunicazione di rete al calcolo.
Lo stato di addestramento del modello viene replicato tra i gruppi di partizione. Ciò significa che prima di applicare i gradienti ai parametri, l'operazione AllReduce deve avvenire tra i gruppi di partizione, oltre all'operazione ReduceScatter che avviene all'interno del gruppo di partizione.
In effetti, il parallelismo dei dati partizionati introduce un compromesso tra il sovraccarico delle comunicazioni e l'efficienza della memoria della GPU. L'uso del parallelismo dei dati partizionati aumenta i costi della comunicazione, ma l'ingombro della memoria della GPU (escluso l'utilizzo della memoria dovuto alle attivazioni) viene suddiviso per il grado di parallelismo dei dati partizionati, quindi è possibile inserire modelli più grandi nel cluster della GPU.
Selezione del grado di parallelismo dei dati partizionati
Quando si seleziona un valore per il grado di parallelismo dei dati partizionati, il valore deve dividere equamente il grado di parallelismo dei dati. Ad esempio, per un processo di parallelismo dei dati a 8 vie, scegli 2, 4 o 8 per il grado di parallelismo dei dati partizionati. Nella scelta del grado di parallelismo dei dati partizionati, si consiglia di iniziare con un numero piccolo e di aumentarlo gradualmente fino a quando il modello non si adatta alla memoria con la dimensione del batch desiderata.
Selezione della dimensione del batch
Dopo aver impostato il parallelismo dei dati partizionati, assicurati di trovare la configurazione di addestramento più ottimale che possa essere eseguito correttamente sul cluster GPU. Per addestrare modelli linguistici di grandi dimensioni (LLM), iniziate dalla dimensione del batch 1 e aumentatela gradualmente fino a raggiungere il punto in cui si verificherà l'errore (OOM). out-of-memory Se riscontri l'errore OOM anche con la dimensione del batch più piccola, applica un grado più elevato di parallelismo dei dati partizionati o una combinazione di parallelismo dei dati partizionati e parallelismo tensoriale.
Argomenti
Come applicare il parallelismo dei dati partizionati al tuo processo di addestramento
Addestramento misto di precisione con parallelismo di dati partizionati
Parallelismo dei dati partizionati con parallelismo tensoriale
Suggerimenti e considerazioni per l'utilizzo del parallelismo dei dati partizionati
Come applicare il parallelismo dei dati partizionati al tuo processo di addestramento
Per iniziare con il parallelismo dei dati frammentati, applica le modifiche necessarie allo script di addestramento e configura lo stimatore con i SageMaker PyTorch parametri. sharded-data-parallelism-specific Considera anche di prendere come punto di partenza i valori di riferimento e i notebook di esempio.
PyTorch Adatta il tuo script di allenamento
Segui le istruzioni riportate nella Fase 1: Modifica uno script di PyTorch addestramento per avvolgere il modello e gli oggetti dell'ottimizzatore con i smdistributed.modelparallel.torch wrapper dei torch.nn.parallel moduli and. torch.distributed
(Facoltativo) Modifica aggiuntiva per registrare i parametri esterni del modello
Se il modello è costruito con torch.nn.Module e utilizza parametri che non sono definiti all'interno della classe del modulo, è necessario registrarli manualmente nel modulo per consentire a SMP di raccogliere i parametri completi. Per registrare i parametri in un modulo, utilizza smp.register_parameter(module,
parameter).
class Module(torch.nn.Module): def __init__(self, *args): super().__init__(self, *args) self.layer1 = Layer1() self.layer2 = Layer2() smp.register_parameter(self, self.layer1.weight) def forward(self, input): x = self.layer1(input) # self.layer1.weight is required by self.layer2.forward y = self.layer2(x, self.layer1.weight) return y
Configura lo stimatore SageMaker PyTorch
Quando configuri uno SageMaker PyTorch stimatoreFase 2: Avviare un job di formazione utilizzando SageMaker Python SDK, aggiungi i parametri per il parallelismo dei dati suddivisi.
Per attivare il parallelismo dei dati frammentati, aggiungi il parametro all'Estimator. sharded_data_parallel_degree SageMaker PyTorch Questo parametro specifica il numero di volte in cui viene suddiviso lo stato GPUs di allenamento. Il valore di sharded_data_parallel_degree deve essere un numero intero compreso tra uno e il grado di parallelismo dei dati e deve dividere equamente il grado di parallelismo dei dati. Si noti che la libreria rileva automaticamente il numero di dati, GPUs quindi il grado di parallelità dei dati. I seguenti parametri aggiuntivi sono disponibili per configurare il parallelismo dei dati partizionati.
-
"sdp_reduce_bucket_size"(int, default: 5e8) — Specifica la dimensione dei bucket di gradiente PyTorch DDPin numero di elementi del dtype predefinito. -
"sdp_param_persistence_threshold"(int, default: 1e6): specifica la dimensione di un tensore di parametri in numero di elementi che possono persistere in ogni GPU. Il parallelismo dei dati condivisi divide ogni tensore di parametri in un gruppo parallelo di GPUs dati. Se il numero di elementi nel tensore dei parametri è inferiore a questa soglia, il tensore del parametro non viene suddiviso; ciò aiuta a ridurre il sovraccarico di comunicazione perché il tensore del parametro viene replicato su dati paralleli. GPUs -
"sdp_max_live_parameters"(int, default: 1e9): specifica il numero massimo di parametri che possono trovarsi contemporaneamente in uno stato di addestramento ricombinato durante il passaggio in avanti e all'indietro. Il recupero dei parametri con l'operazioneAllGathersi interrompe quando il numero di parametri attivi raggiunge la soglia specificata. Si noti che l'aumento di questo parametro aumenta l'ingombro di memoria. -
"sdp_hierarchical_allgather"(bool, default: True): se impostato suTrue, l'operazioneAllGatherviene eseguita in modo gerarchico: viene eseguita prima all'interno di ogni nodo e poi tra i nodi. Per i processi di addestramento distribuito su più nodi, l'operazioneAllGathergerarchica viene attivata automaticamente. -
"sdp_gradient_clipping"(float, default: 1.0): specifica una soglia per il ritaglio del gradiente secondo la norma L2 dei gradienti prima di propagarli all'indietro attraverso i parametri del modello. Quando è attivato il parallelismo dei dati partizionati, viene attivato anche il ritaglio del gradiente. La soglia predefinita è1.0. Regola questo parametro se hai il problema dei gradienti esplosivi.
Il codice seguente mostra un esempio di come configurare il parallelismo dei dati partizionati.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled": True, "parameters": { # "pipeline_parallel_degree": 1, # Optional, default is 1 # "tensor_parallel_degree": 1, # Optional, default is 1 "ddp": True, # parameters for sharded data parallelism "sharded_data_parallel_degree":2, # Add this to activate sharded data parallelism "sdp_reduce_bucket_size": int(5e8), # Optional "sdp_param_persistence_threshold": int(1e6), # Optional "sdp_max_live_parameters": int(1e9), # Optional "sdp_hierarchical_allgather":True, # Optional "sdp_gradient_clipping":1.0# Optional } } mpi_options = { "enabled" : True, # Required "processes_per_host" :8# Required } smp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script role=sagemaker.get_execution_role(), instance_count=1, instance_type='ml.p3.16xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-job" ) smp_estimator.fit('s3://my_bucket/my_training_data/')
Configurazioni di riferimento
Il team di formazione SageMaker distribuito fornisce le seguenti configurazioni di riferimento che è possibile utilizzare come punto di partenza. Puoi estrapolare le configurazioni seguenti per sperimentare e stimare l'utilizzo della memoria della GPU per la configurazione del modello.
Parallelismo dei dati partizionati con i collettivi SMDDP
| Modello/numero di parametri | Numero di istanze | Tipo di istanza | Lunghezza della sequenza | Dimensioni batch globali | Dimensioni del mini-batch | Grado parallelo di dati partizionati |
|---|---|---|---|---|---|---|
| GPT-NEOX-20B | 2 | ml.p4d.24xlarge | 2048 | 64 | 4 | 16 |
| GPT-NEOX-20B | 8 | ml.p4d.24xlarge | 2048 | 768 | 12 | 32 |
Ad esempio, se aumenti la lunghezza della sequenza per un modello da 20 miliardi di parametri o aumenti le dimensioni del modello a 65 miliardi di parametri, dovresti prima provare a ridurre la dimensione del batch. Se il modello continua a non adattarsi alla dimensione del batch più piccola (la dimensione del batch pari a 1), prova ad aumentare il grado di parallelismo del modello.
Parallelismo dei dati partizionati con parallelismo tensoriale e collettivi NCCL
| Modello/numero di parametri | Numero di istanze | Tipo di istanza | Lunghezza della sequenza | Dimensioni batch globali | Dimensioni del mini-batch | Grado parallelo di dati partizionati | Grado di parallelo tensoriale | Offload di attivazione |
|---|---|---|---|---|---|---|---|---|
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 2048 | 512 | 8 | 16 | 8 | Y |
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 4096 | 512 | 2 | 64 | 2 | Y |
L'uso combinato del parallelismo dei dati frammentati e del parallelismo tensoriale è utile quando si desidera inserire un modello linguistico di grandi dimensioni (LLM) in un cluster su larga scala utilizzando dati di testo con una lunghezza di sequenza maggiore, il che porta a utilizzare un batch di dimensioni inferiori e, di conseguenza, a gestire l'utilizzo della memoria della GPU per allenarsi con sequenze di testo più lunghe. LLMs Per ulteriori informazioni, consulta Parallelismo dei dati partizionati con parallelismo tensoriale.
Per case study, benchmark e altri esempi di configurazione, consulta il post sul blog Nuovi miglioramenti delle prestazioni nella libreria parallela del modello Amazon SageMaker AI
Parallelismo dei dati partizionati con i collettivi SMDDP
La libreria di parallelismo SageMaker dei dati offre primitive di comunicazione collettiva (collettivi SMDDP) ottimizzate per l'infrastruttura. AWS Raggiunge l'ottimizzazione adottando un modello di all-to-all-type comunicazione basato sull'uso di Elastic Fabric Adapter (
Nota
Il parallelismo dei dati condivisi con SMDDP Collectives è disponibile nella libreria di parallelismo dei SageMaker modelli v1.13.0 e successive e nella libreria di parallelismo dei dati v1.6.0 e successive. SageMaker Vedi anche Supported configurations per utilizzare il parallelismo dei dati partizionati con i collettivi SMDDP.
Nel parallelismo dei dati partizionati, che è una tecnica comunemente usata nell'addestramento distribuito su larga scala, il collettivo AllGather viene utilizzato per ricostituire i parametri dei livelli partizionati per i calcoli dei passaggi avanti e indietro, in parallelo al calcolo della GPU. Per i modelli di grandi dimensioni, eseguire l'operazione AllGather in modo efficiente è fondamentale per evitare problemi legati alla GPU e rallentare la velocità di addestramento. Quando viene attivato il parallelismo dei dati partizionati, i collettivi SMDDP entrano a far parte di questi collettivi AllGather critici in termini di prestazioni, migliorando la produttività dell'addestramento.
Addestramento con i collettivi SMDDP
Quando il processo di addestramento ha attivato il parallelismo dei dati partizionati e soddisfa i requisiti Supported configurations, i collettivi SMDDP vengono attivati automaticamente. Internamente, i collettivi SMDDP ottimizzano il collettivo per renderlo efficiente sull'infrastruttura e ricorrono a NCCL per tutti gli altri collettivi. AllGather AWS Inoltre, in configurazioni non supportate, tutti i collettivi, incluso AllGather, utilizzano automaticamente il back-end NCCL.
A partire dalla versione 1.13.0 della libreria di parallelismo dei SageMaker modelli, il parametro viene aggiunto alle opzioni. "ddp_dist_backend" modelparallel Il valore predefinito per questo parametro di configurazione è "auto", che utilizza i collettivi SMDDP quando possibile, altrimenti ricorre a NCCL. Per forzare la libreria a utilizzare sempre NCCL, specifica "nccl" nel parametro di configurazione "ddp_dist_backend".
Il seguente esempio di codice mostra come impostare uno PyTorch stimatore utilizzando il parallelismo dei dati frammentati con il "ddp_dist_backend" parametro, che è impostato come impostazione predefinita e, pertanto, facoltativo "auto" da aggiungere.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled":True, "parameters": { "partitions": 1, "ddp": True, "sharded_data_parallel_degree":64"bf16": True, "ddp_dist_backend": "auto" # Specify "nccl" to force to use NCCL. } } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Configurazioni supportate
L'operazione AllGather con i collettivi SMDDP viene attivata nei processi di addestramento quando vengono soddisfatti tutti i seguenti requisiti di configurazione.
-
Il grado di parallelismo dei dati partizionati è maggiore di 1
-
Instance_countmaggiore di 1 -
Instance_typeuguale aml.p4d.24xlarge -
SageMaker contenitore di formazione per v1.12.1 o versione successiva PyTorch
-
La libreria di parallelismo SageMaker dei dati v1.6.0 o successiva
-
La libreria di SageMaker parallelismo dei modelli v1.13.0 o successiva
Ottimizzazione delle prestazioni e della memoria
I collettivi SMDDP utilizzano memoria GPU aggiuntiva. Esistono due variabili di ambiente per configurare l'utilizzo della memoria della GPU a seconda dei diversi casi d'uso di addestramento del modello.
-
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES: durante l'operazioneAllGatherSMDDP, il buffer di inputAllGatherviene copiato in un buffer temporaneo per la comunicazione tra i nodi. La variabileSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTEScontrolla la dimensione (in byte) di questo buffer temporaneo. Se la dimensione del buffer temporaneo è inferiore alla dimensione del buffer di inputAllGather, il collettivoAllGathertorna a utilizzare NCCL.-
Valore predefinito: 16 * 1024 * 1024 (16 MB)
-
Valori accettabili: qualsiasi multiplo di 8192
-
-
SMDDP_AG_SORT_BUFFER_SIZE_BYTES: la variabileSMDDP_AG_SORT_BUFFER_SIZE_BYTESserve a dimensionare il buffer temporaneo (in byte) per contenere i dati raccolti dalla comunicazione tra i nodi. Se la dimensione di questo buffer temporaneo è inferiore a1/8 * sharded_data_parallel_degree * AllGather input size, il collettivoAllGathertorna a utilizzare NCCL.-
Valore predefinito: 128 * 1024 * 1024 (128 MB)
-
Valori accettabili: qualsiasi multiplo di 8192
-
Guida all'ottimizzazione delle variabili relative alla dimensione del buffer
I valori predefiniti per le variabili di ambiente dovrebbero funzionare bene per la maggior parte dei casi d'uso. Consigliamo di ottimizzare queste variabili solo se durante l'addestramento si verifica l'errore (OOM). out-of-memory
L'elenco seguente illustra alcuni suggerimenti di ottimizzazione per ridurre l'ingombro di memoria della GPU dei collettivi SMDDP, preservando al contempo il miglioramento delle prestazioni che ne derivano.
-
Ottimizzazione
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES-
La dimensione del buffer di input
AllGatherè inferiore per i modelli più piccoli. Pertanto, la dimensione richiesta perSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESpuò essere inferiore per i modelli con meno parametri. -
La dimensione del buffer di
AllGatherinput diminuisce all'sharded_data_parallel_degreeaumentare, poiché il modello viene ulteriormente suddiviso. GPUs Pertanto, la dimensione richiesta perSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESpuò essere inferiore per processi di addestramento con valori grandi persharded_data_parallel_degree.
-
-
Ottimizzazione
SMDDP_AG_SORT_BUFFER_SIZE_BYTES-
La quantità di dati raccolti dalla comunicazione tra nodi è inferiore per i modelli con un minor numero di parametri. Pertanto, la dimensione richiesta per
SMDDP_AG_SORT_BUFFER_SIZE_BYTESpuò essere inferiore per tali modelli con un numero inferiore di parametri.
-
Alcuni collettivi potrebbero tornare a utilizzare NCCL; di conseguenza, potresti non ottenere il miglioramento delle prestazioni dai collettivi SMDDP ottimizzati. Se è disponibile memoria GPU aggiuntiva, è possibile valutare la possibilità di aumentare i valori SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES e SMDDP_AG_SORT_BUFFER_SIZE_BYTES per trarre vantaggio dall'aumento delle prestazioni.
Il codice seguente mostra come configurare le variabili di ambiente aggiungendole mpi_options nel parametro di distribuzione dello stimatore. PyTorch
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { .... # All modelparallel configuration options go here } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } # Use the following two lines to tune values of the environment variables for buffer mpioptions += " -x SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES=8192" mpioptions += " -x SMDDP_AG_SORT_BUFFER_SIZE_BYTES=8192" smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo-with-tuning", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Addestramento misto di precisione con parallelismo di dati partizionati
Per risparmiare ulteriormente la memoria della GPU con numeri in virgola mobile a mezza precisione e parallelismo dei dati frammentati, puoi attivare il formato a virgola mobile a 16 bit (FP16) o il formato a virgola mobile Brain () aggiungendo un parametro aggiuntivo alla configurazione di addestramento
Nota
L'addestramento misto di precisione con parallelismo dei dati condiviso è disponibile nella libreria di parallelismo dei modelli v1.11.0 e versioni successive. SageMaker
Per FP16 la formazione con Sharded Data Parallelism
Per eseguire l' FP16 allenamento con il parallelismo dei dati condivisi, aggiungilo al dizionario di configurazione. "fp16": True" smp_options Nello script di addestramento, puoi scegliere tra le opzioni di dimensionamento delle perdite statiche e dinamiche tramite il modulo smp.DistributedOptimizer. Per ulteriori informazioni, consulta FP16 Formazione con Model Parallelism.
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "fp16":True} }
Per la BF16 formazione con Sharded Data Parallelism
La funzionalità di parallelismo dei dati condivisi dell' SageMaker IA supporta l'addestramento sul tipo di dati. BF16 Il tipo di BF16 dati utilizza 8 bit per rappresentare l'esponente di un numero in virgola mobile, mentre il tipo di dati utilizza 5 bit. FP16 La conservazione degli 8 bit per l'esponente consente di mantenere la stessa rappresentazione dell'esponente di un numero a virgola mobile () a precisione singola a 32 bit. FP32 Ciò semplifica la conversione da un modello all'altro FP32 ed è notevolmente meno incline a causare problemi di overflow e underflow, che spesso si presentano durante l'addestramento, specialmente quando si addestrano modelli BF16 più grandi. FP16 Sebbene entrambi i tipi di dati utilizzino 16 bit in totale, questo maggiore intervallo di rappresentazione dell'esponente nel BF16 formato va a scapito della riduzione della precisione. Per l'addestramento di modelli di grandi dimensioni, questa precisione ridotta è spesso considerata un compromesso accettabile per quanto riguarda la portata e la stabilità dell'addestramento.
Nota
Attualmente, la BF16 formazione funziona solo quando è attivato il parallelismo dei dati suddivisi.
Per eseguire l' BF16 allenamento con il parallelismo dei dati frammentati, aggiungilo al dizionario di configurazione. "bf16": True smp_options
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "bf16":True} }
Parallelismo dei dati partizionati con parallelismo tensoriale
Se utilizzi il parallelismo dei dati partizionati e devi anche ridurre la dimensione globale del batch, prendi in considerazione l'utilizzo del parallelismo tensoriale con il parallelismo dei dati partizionati. Quando si addestra un modello di grandi dimensioni con parallelismo dei dati partizionati su un cluster di elaborazione molto grande (in genere 128 nodi o più), anche un batch di piccole dimensioni per GPU si traduce in un batch globale di dimensioni molto grandi. Potrebbe portare a problemi di convergenza o a basse prestazioni di calcolo. La riduzione della dimensione del batch per GPU a volte non è possibile con il solo parallelismo dei dati partizionati, quando un singolo batch è già di grandi dimensioni e non può essere ulteriormente ridotto. In questi casi, l'utilizzo del parallelismo dei dati partizionati in combinazione con il parallelismo tensoriale aiuta a ridurre la dimensione globale del batch.
La scelta dei gradi ottimali partizionati di parallelismo dei dati e dei tensori dipende dalla scala del modello, dal tipo di istanza e dalla dimensione globale del batch che è ragionevole per la convergenza del modello. Ti consigliamo di iniziare da un grado di parallelo tensoriale basso per adattare la dimensione globale del batch al cluster di calcolo per risolvere out-of-memory gli errori CUDA e ottenere le migliori prestazioni. Guardate i due casi di esempio seguenti per scoprire come la combinazione del parallelismo tensoriale e del parallelismo dei dati condivisi aiuta a regolare la dimensione globale del batch raggruppando GPUs per il parallelismo del modello, con il risultato di un minor numero di repliche del modello e una dimensione globale del batch più piccola.
Nota
Questa funzionalità è disponibile nella libreria di parallelismo dei modelli v1.15 e supporta la versione 1.13.1. SageMaker PyTorch
Nota
Questa funzionalità è disponibile per i modelli supportati dalla funzionalità di parallelismo tensoriale della libreria. Per trovare l'elenco dei modelli supportati, consulta Supporto per i modelli Hugging Face Transformer. Tieni inoltre presente che devi passare tensor_parallelism=True all'argomento smp.model_creation mentre modifichi lo script di addestramento. Per saperne di più, consulta lo script di formazione nell'archivio AI Examples. train_gpt_simple.py
Esempio 1
Supponiamo di voler addestrare un modello su un cluster di 1536 GPUs (192 nodi con 8 GPUs in ciascuno), impostando il grado di parallelismo dei dati frammentati su 32 (sharded_data_parallel_degree=32) e la dimensione del batch per GPU su 1, dove ogni batch ha una lunghezza di sequenza di 4096 token. In questo caso, ci sono 1536 repliche di modelli, la dimensione globale del batch diventa 1536 e ogni batch globale contiene circa 6 milioni di token.
(1536 GPUs) * (1 batch per GPU) = (1536 global batches) (1536 batches) * (4096 tokens per batch) = (6,291,456 tokens)
L'aggiunta del parallelismo tensoriale può ridurre la dimensione globale del batch. Un esempio di configurazione può essere l'impostazione del grado parallelo tensoriale su 8 e la dimensione del batch per GPU su 4. Questo forma 192 gruppi tensoriali paralleli o 192 repliche di modelli, in cui ogni replica del modello è distribuita su 8. GPUs La dimensione del batch di 4 è la quantità di dati di addestramento per iterazione e per gruppo parallelo di tensori; ovvero, ogni replica del modello consuma 4 batch per iterazione. In questo caso, la dimensione globale del batch diventa 768 e ogni batch globale contiene circa 3 milioni di token. Pertanto, la dimensione globale del batch è ridotta della metà rispetto al caso precedente con il solo parallelismo dei dati partizionati.
(1536 GPUs) / (8 tensor parallel degree) = (192 tensor parallelism groups) (192 tensor parallelism groups) * (4 batches per tensor parallelism group) = (768 global batches) (768 batches) * (4096 tokens per batch) = (3,145,728 tokens)
Esempio 2
Quando sono attivati sia il parallelismo dei dati partizionati che il parallelismo tensoriale, la libreria applica innanzitutto il parallelismo tensoriale e partiziona il modello in questa dimensione. Per ogni classificazione parallela dei tensori, il parallelismo dei dati viene applicato come per sharded_data_parallel_degree.
Ad esempio, supponiamo di voler impostare 32 GPUs con un grado di parallelo del tensore di 4 (formando gruppi di 4 GPUs), un grado di parallelo dei dati frammentati di 4, finendo con un grado di replica di 2. L'assegnazione crea otto gruppi di GPU in base al grado di parallelismo tensoriale come segue: (0,1,2,3), (4,5,6,7), (8,9,10,11), (12,13,14,15), (16,17,18,19), (20,21,22,23), (24,25,26,27), (28,29,30,31). Cioè, quattro GPUs formano un gruppo parallelo tensoriale. In questo caso, il gruppo parallelo di dati ridotto per il rango 0 GPUs dei gruppi paralleli tensoriali sarebbe. (0,4,8,12,16,20,24,28) Il gruppo parallelo di dati ridotto viene suddiviso in base al grado di parallelismo dei dati condivisi pari a 4, ottenendo due gruppi di replica per il parallelismo dei dati. GPUs(0,4,8,12)formano un gruppo di sharding, che collettivamente contiene una copia completa di tutti i parametri per lo 0th tensor parallel rank, e GPUs (16,20,24,28) formano un altro gruppo di questo tipo. Anche altre classificazioni tensoriali parallele hanno gruppi di partizioni e replica simili.
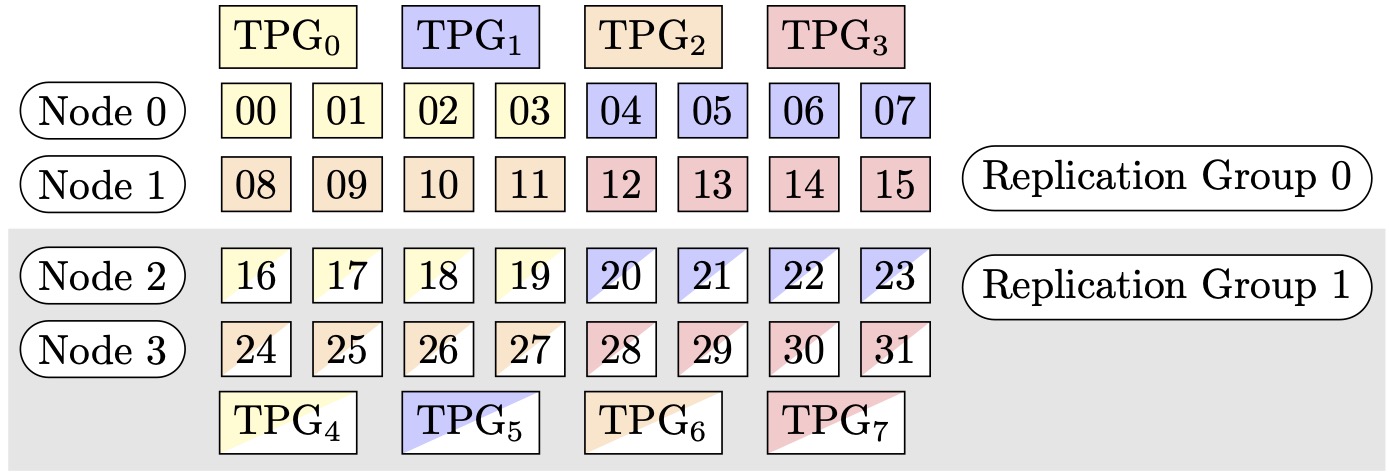
Figura 1: Gruppi di parallelizzazione tensoriale per (nodi, grado di parallelizzazione dei dati sottoposti a sharding, grado di parallelizzazione tensoriale) = (4, 4, 4), dove ogni rettangolo rappresenta una GPU con indici da 0 a 31. Il parallelismo tensoriale GPUs di forma raggruppa da TPG a TPG. 0 7 I gruppi di replica sono ({TPG0, TPG4}, {TPG1, TPG5}, {TPG2, TPG6} e {TPG3, TPG7}); ogni coppia di gruppi di replica condivide lo stesso colore, ma presenta un riempimento diverso.
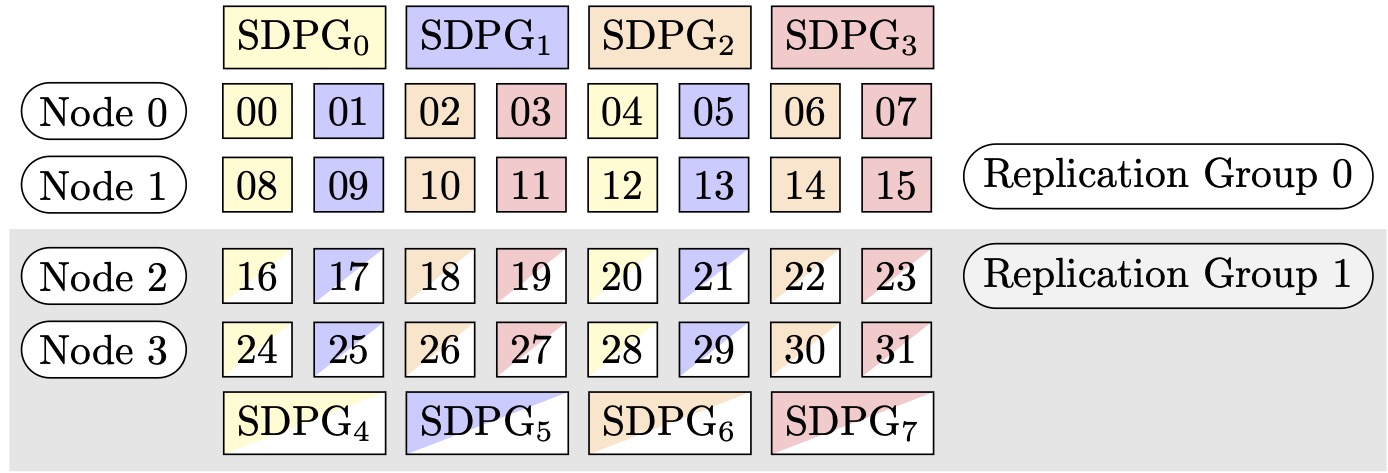
Figura 2: Gruppi di parallelizzazione dei dati sottoposti a sharding (nodi, grado di parallelizzazione dei dati sottoposti a sharding, grado di parallelizzazione tensoriale) = (4, 4, 4), dove ogni rettangolo rappresenta una GPU con indici da 0 a 31. Il GPUs modulo Sharded Data Parallelism raggruppa da SDPG a SDPG. 0 7 I gruppi di replica sono ({SDPG0, SDPG4}, {SDPG1, SDPG5}, {SDPG2, SDPG6} e {SDPG3, SDPG7}); ogni coppia di gruppi di replica condivide lo stesso colore, ma presenta un riempimento diverso.
Come attivare il parallelismo dei dati partizionati con il parallelismo tensoriale
Per utilizzare il parallelismo dei dati condivisi con il parallelismo tensoriale, è necessario impostarli entrambi sharded_data_parallel_degree e tensor_parallel_degree nella configurazione durante la creazione di un oggetto della classe estimator. distribution SageMaker PyTorch
È inoltre necessario attivare prescaled_batch. Ciò significa che, invece di leggere il proprio batch di dati, ogni gruppo parallelo tensoriale legge collettivamente un batch combinato della dimensione del batch scelta. In effetti, invece di dividere il set di dati in parti uguali al numero di GPUs (o dimensione parallela dei datismp.dp_size()), lo divide in parti uguali al numero di GPUs diviso per tensor_parallel_degree (chiamato anche dimensione parallela dei dati ridotta). smp.rdp_size() Per maggiori dettagli sul batch prescalato, consulta Prescaled Batchtrain_gpt_simple.py
Il seguente frammento di codice mostra un esempio di creazione di un oggetto PyTorch estimatore basato sullo scenario sopra menzionato in. Esempio 2
mpi_options = "-verbose --mca orte_base_help_aggregate 0 " smp_parameters = { "ddp": True, "fp16": True, "prescaled_batch": True, "sharded_data_parallel_degree":4, "tensor_parallel_degree":4} pytorch_estimator = PyTorch( entry_point="your_training_script.py", role=role, instance_type="ml.p4d.24xlarge", volume_size=200, instance_count=4, sagemaker_session=sagemaker_session, py_version="py3", framework_version="1.13.1", distribution={ "smdistributed": { "modelparallel": { "enabled": True, "parameters": smp_parameters, } }, "mpi": { "enabled": True, "processes_per_host": 8, "custom_mpi_options": mpi_options, }, }, source_dir="source_directory_of_your_code", output_path=s3_output_location)
Suggerimenti e considerazioni per l'utilizzo del parallelismo dei dati partizionati
Considerate quanto segue quando utilizzate il parallelismo dei dati frammentati della libreria SageMaker Model Parallelism.
-
Il parallelismo dei dati condivisi è compatibile con la formazione. FP16 Per eseguire l' FP16allenamento, consulta la sezione. FP16 Formazione con Model Parallelism
-
Il parallelismo dei dati partizionati è compatibile con il parallelismo tensoriale. I seguenti elementi sono ciò che potresti dover considerare per utilizzare il parallelismo dei dati partizionati con il parallelismo tensoriale.
-
Quando si utilizza il parallelismo dei dati partizionati con il parallelismo tensoriale, anche i livelli di incorporamento vengono distribuiti automaticamente nel gruppo parallelo tensoriale. In altre parole, il parametro
distribute_embeddingviene impostato automaticamente suTrue. Per maggiori informazioni sul parallelismo tensoriale, consulta Parallelismo tensoriale. -
Si noti che il parallelismo dei dati partizionati con il parallelismo tensoriale attualmente utilizza i collettivi NCCL come back-end della strategia di addestramento distribuito.
Per ulteriori informazioni, consulta la sezione Parallelismo dei dati partizionati con parallelismo tensoriale.
-
-
Il parallelismo dei dati partizionati attualmente non è compatibile con il parallelismo di pipeline o il partizionamento dello stato dell'ottimizzatore. Per attivare il parallelismo dei dati partizionati, disattiva il partizionamento dello stato dell'ottimizzatore e imposta il grado di parallelismo della pipeline su 1.
-
Le funzionalità checkpoint di attivazione e offload di attivazione sono compatibili con il parallelismo dei dati partizionati.
-
Per utilizzare il parallelismo dei dati partizionati con l'accumulo di gradienti, impostate l'argomento
backward_passes_per_stepsul numero di fasi di accumulo mentre effettui il wrapping del modello con il modulosmdistributed.modelparallel.torch.DistributedModel. Ciò garantisce che l'operazione AllReducedel gradiente tra i gruppi di replica del modello (gruppi di partizionamento) avvenga al limite dell'accumulo del gradiente. -
Puoi eseguire il checkpoint dei tuoi modelli addestrati con il parallelismo dei dati frammentati utilizzando il checkpointing della libreria e. APIs
smp.save_checkpointsmp.resume_from_checkpointPer ulteriori informazioni, consulta Verifica di un PyTorch modello distribuito (per la libreria di parallelismo dei SageMaker modelli v1.10.0 e successive). -
Il comportamento del parametro di configurazione
delayed_parameter_initializationcambia in base al parallelismo dei dati partizionati. Quando queste due funzionalità sono attivate contemporaneamente, i parametri vengono inizializzati immediatamente dopo la creazione del modello in modo partizionato anziché ritardare l'inizializzazione dei parametri, in modo che ogni classificazione inizializzi e memorizzi la propria partizione di parametri. -
Quando è attivato il parallelismo dei dati partizionati, la libreria esegue internamente il ritaglio del gradiente durante l'esecuzione della chiamata
optimizer.step(). Non è necessario utilizzare l'utilità per il ritaglio del gradiente, ad APIs esempio.torch.nn.utils.clip_grad_norm_()Per regolare il valore di soglia per il ritaglio del gradiente, potete impostarlo tramite il sdp_gradient_clippingparametro per la configurazione dei parametri di distribuzione quando costruite lo stimatore, come mostrato nella sezione. SageMaker PyTorch Come applicare il parallelismo dei dati partizionati al tuo processo di addestramento
