Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Mappatura dei percorsi di storage della formazione gestiti da Amazon SageMaker AI
Questa pagina fornisce un riepilogo di alto livello di come la piattaforma di SageMaker formazione gestisce i percorsi di archiviazione per set di dati di addestramento, artefatti dei modelli, checkpoint e output tra l'archiviazione su cloud e i lavori di formazione nell'intelligenza artificiale. AWS SageMaker In questa guida, imparerai a identificare i percorsi predefiniti impostati dalla piattaforma SageMaker AI e come semplificare i canali di dati con le tue fonti di dati in Amazon Simple Storage Service (Amazon S3), FSx for Lustre e Amazon EFS. Per ulteriori informazioni sulle diverse classi di input e sulle classi di storage dei canali dati, consulta Configurazione di job di addestramento per accedere ai set di dati.
Panoramica di come l'IA mappa i percorsi di archiviazione SageMaker
Il diagramma seguente mostra un esempio di come l' SageMaker IA mappa i percorsi di input e output quando si esegue un processo di formazione utilizzando la classe SageMaker Python SDK
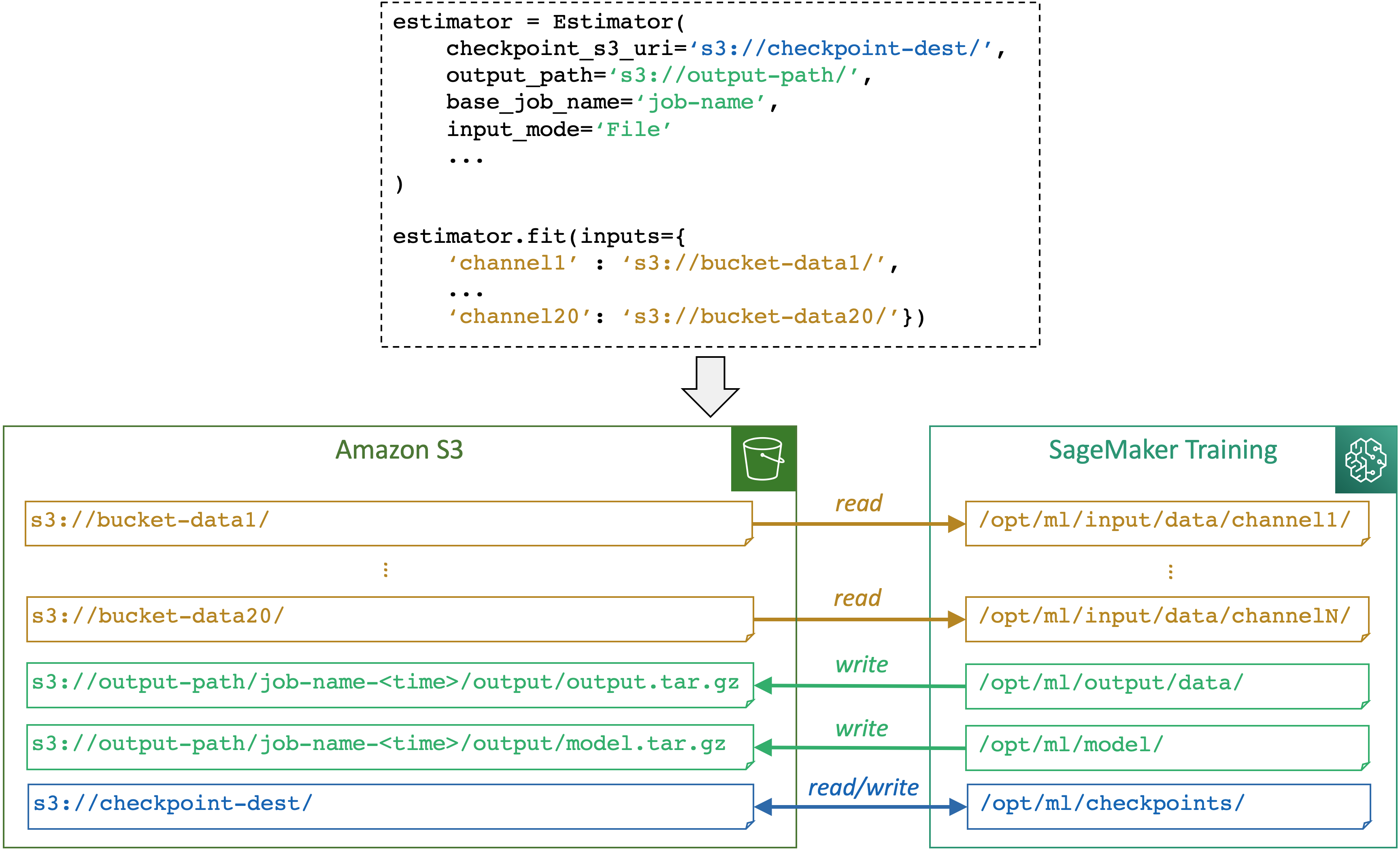
SageMaker L'intelligenza artificiale mappa i percorsi di storage tra uno storage (come Amazon S3, Amazon FSx e Amazon EFS) e il contenitore di SageMaker formazione in base ai percorsi e alla modalità di input specificati tramite un SageMaker oggetto di stima AI. Per ulteriori informazioni su come l' SageMaker intelligenza artificiale legge o scrive sui percorsi e sullo scopo dei percorsi, vedi. SageMaker Variabili di ambiente AI e percorsi predefiniti per l'addestramento dei luoghi di archiviazione
Puoi utilizzarli OutputDataConfig nell'CreateTrainingJobAPI per salvare i risultati dell'addestramento dei modelli in un bucket S3. Utilizza l'ModelArtifactsAPI per trovare il bucket S3 che contiene gli artefatti del modello. Consulta il notebook abalone_build_train_deploy
Argomenti
