Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Metriche di Amazon SageMaker AI in Amazon CloudWatch
Puoi monitorare Amazon SageMaker AI utilizzando Amazon CloudWatch, che raccoglie dati grezzi e li elabora in metriche leggibili quasi in tempo reale. che vengono conservate per 15 mesi. Queste consentono di accedere alle informazioni storiche per ottenere una prospettiva migliore sulle prestazioni del servizio o dell’applicazione web. Tuttavia, la CloudWatch console Amazon limita la ricerca alle metriche aggiornate nelle ultime 2 settimane. Questa limitazione consente di visualizzare nello spazio dei nomi i processi più aggiornati.
Per rappresentare graficamente i parametri senza utilizzare una ricerca, specifica il nome esatto nella visualizzazione di origine. È anche possibile impostare allarmi che controllano determinate soglie e inviare notifiche o intraprendere azioni quando queste soglie vengono raggiunte. Per ulteriori informazioni, consulta la Amazon CloudWatch User Guide.
SageMaker Metriche e dimensioni dell'IA
SageMaker Metriche degli endpoint AI
Il /aws/sagemaker/Endpoints namespace include le seguenti metriche per le istanze degli endpoint.
I parametri sono disponibili a una frequenza di 1 minuto. Puoi configurare la frequenza di pubblicazione su 10, 30, 60, 120, 180, 240 o 300 secondi impostando. MetricPublishFrequencyInSeconds MetricsConfig Non è necessario EnableEnhancedMetrics abilitare questa impostazione. Se si imposta su EnableEnhancedMetricsTrue, sono disponibili le dimensioni InstanceId e le metriche aggiuntive AcceleratorId (solo metriche GPU). Per ulteriori informazioni, consulta Parametri avanzati di Amazon SageMaker AI per gli endpoint di inferenza.
Nota
Amazon CloudWatch supporta metriche personalizzate ad alta risoluzione e la sua risoluzione massima è di 1 secondo. Tuttavia, maggiore è la risoluzione, minore è la durata delle metriche. CloudWatch Per la risoluzione di frequenza di 1 secondo, le CloudWatch metriche sono disponibili per 3 ore. Per ulteriori informazioni sulla risoluzione e sulla durata delle CloudWatch metriche, consulta Amazon CloudWatch API GetMetricStatisticsReference.
| Metrica | Description |
|---|---|
CPUReservation |
La somma delle CPU riservate dai container su un’istanza. Questa metrica viene fornita solo per gli endpoint che ospitano componenti di inferenza attivi. Il valore è compreso tra 0 e 100%. Nelle impostazioni di un componente di inferenza, imposta la prenotazione della CPU con il parametro |
CPUUtilization |
La somma dell'utilizzo di ogni singolo core CPU. L'utilizzo della CPU di ciascun core è compreso tra 0 e 100. Ad esempio, se ci sono quattro CPU, il Per le varianti dell'endpoint, il valore è la somma dell'utilizzo delle CPU dei container principali e supplementari sull'istanza. Unità: percentuale |
CPUUtilizationNormalized |
Somma normalizzata dell’utilizzo di ogni singolo core CPU. Questa metrica viene fornita solo per gli endpoint che ospitano componenti di inferenza attivi. Il valore è compreso tra 0 e 100%. Ad esempio, se sono presenti quattro CPU e la metrica |
DiskUtilization |
Percentuale di spazio su disco utilizzata dai container su un'istanza. Questo intervallo di valori è compreso tra 0% e 100%. Per le varianti dell'endpoint, il valore è la somma dell'utilizzo dello spazio su disco dei container principali e supplementari sull'istanza.Unità: percentuale |
GPUMemoryUtilization |
Percentuale di memoria GPU utilizzata dai container su un'istanza. Il valore varia da 0 e 100 ed è moltiplicato per il numero di GPU. Ad esempio, se ci sono quattro GPU, il Per le varianti dell'endpoint, il valore è la somma dell'utilizzo di memoria GPU dei container principali e supplementari sull'istanza. Unità: percentuale |
GPUMemoryUtilizationNormalized |
Percentuale normalizzata della memoria GPU utilizzata dai container su un’istanza. Questa metrica viene fornita solo per gli endpoint che ospitano componenti di inferenza attivi. Il valore è compreso tra 0 e 100%. Ad esempio, se sono presenti quattro GPU e la metrica |
GPUReservation |
La somma delle GPU riservate dai container su un’istanza. Questa metrica viene fornita solo per gli endpoint che ospitano componenti di inferenza attivi. Il valore è compreso tra 0 e 100%. Nelle impostazioni di un componente di inferenza, imposta la prenotazione della GPU per |
GPUUtilization |
Percentuale di unità GPU utilizzata dai container su un'istanza. Il valore può essere compreso tra 0 e 100 ed è moltiplicato per il numero di GPU. Ad esempio, se ci sono quattro GPU, il Per le varianti dell'endpoint, il valore è la somma dell'utilizzo delle GPU dei container principali e supplementari sull'istanza. Unità: percentuale |
GPUUtilizationNormalized |
Percentuale normalizzata di unità GPU utilizzate dai container su un’istanza. Questa metrica viene fornita solo per gli endpoint che ospitano componenti di inferenza attivi. Il valore è compreso tra 0 e 100%. Ad esempio, se sono presenti quattro GPU e la metrica |
MemoryReservation |
La somma della memoria riservata dai container su un’istanza. Questa metrica viene fornita solo per gli endpoint che ospitano componenti di inferenza attivi. Il valore è compreso tra 0 e 100%. Nelle impostazioni di un componente di inferenza, imposta la prenotazione della memoria con il parametro |
MemoryUtilization |
Percentuale di memoria utilizzata dai container su un'istanza. Questo intervallo di valori è compreso tra 0% e 100%. Per le varianti dell'endpoint, il valore è la somma dell'utilizzo di memoria dei container principali e supplementari sull'istanza. Unità: percentuale |
| Dimensione | Description |
|---|---|
EndpointName, VariantName |
Filtra le metriche degli endpoint per uno |
EndpointName, VariantName, InstanceType |
Filtra le metriche degli endpoint per tipo di istanza per una variante di produzione che utilizza pool di istanze. Utilizza questa dimensione per monitorare separatamente le metriche per ogni tipo di istanza all'interno della variante. |
InstanceId |
Filtra le metriche degli endpoint per un'istanza specifica. Disponibile quando |
AcceleratorId |
(Solo metriche GPU) Filtra le metriche degli endpoint per una GPU specifica. Disponibile quando è impostato su in |
SageMaker Metriche di invocazione degli endpoint AI
Lo spazio dei nomi AWS/SageMaker include i seguenti parametri di richiesta dalle chiamate a InvokeEndpoint.
I parametri sono disponibili a una frequenza di 1 minuto. Puoi configurare la frequenza di pubblicazione su 10, 30, 60, 120, 180, 240 o 300 secondi impostando. MetricPublishFrequencyInSeconds MetricsConfig Per le metriche di invocazione, questa impostazione deve essere impostata EnableEnhancedMetrics su. True Quando si imposta su EnableEnhancedMetricsTrue, sono disponibili anche le dimensioni InstanceId e ContainerId (solo i componenti di inferenza) aggiuntivi. Per ulteriori informazioni, consulta Parametri avanzati di Amazon SageMaker AI per gli endpoint di inferenza.
L'illustrazione seguente mostra come un endpoint SageMaker AI interagisce con l'API Amazon SageMaker Runtime. Il tempo complessivo tra l'invio di una richiesta a un endpoint e la ricezione di una risposta dipende dai seguenti tre componenti.
-
Latenza di rete: il tempo che intercorre tra l'invio di una richiesta e la ricezione di una risposta dall'API Runtime Runtime. SageMaker
-
Latenza di sovraccarico: il tempo necessario per trasportare una richiesta al container del modello e riportare la risposta all'API SageMaker Runtime Runtime.
-
Latenza del modello: il tempo impiegato dal container del modello per elaborare la richiesta e restituire una risposta.
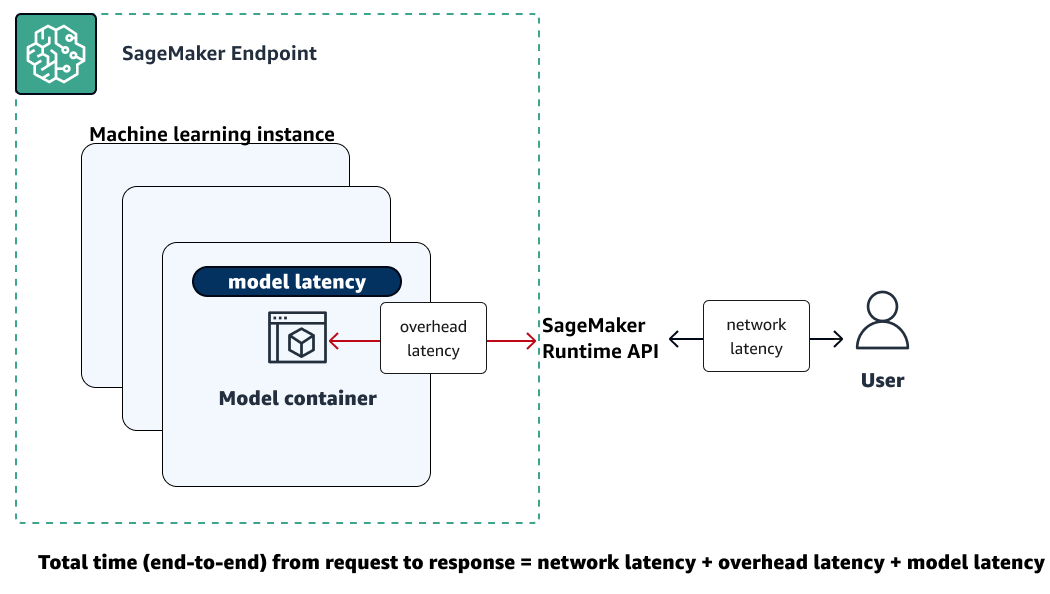
Per ulteriori informazioni sulla latenza totale, consulta Best practice for load testing degli endpoint di inferenza in tempo reale di Amazon SageMaker AI
| Metrica | Description |
|---|---|
ConcurrentRequestsPerCopy |
Il numero di richieste simultanee ricevute dal componente di inferenza, normalizzato da ogni copia di un componente di inferenza. Statistiche valide: Min, Max |
ConcurrentRequestsPerModel |
Il numero di richieste simultanee ricevute dal modello. Statistiche valide: Min, Max |
Invocation4XXErrors |
Numero di richieste Unità: nessuna Statistiche valide: Average, Sum |
Invocation5XXErrors |
Numero di richieste Unità: nessuna Statistiche valide: Average, Sum |
InvocationModelErrors |
Il numero di richieste di invocazione del modello che non hanno prodotto una risposta HTTP 2XX. Ciò include codici di 4XX/5XX stato, errori di socket di basso livello, risposte HTTP non corrette e timeout delle richieste. Per ogni risposta di errore, viene inviato 1; altrimenti, viene inviato 0. Unità: nessuna Statistiche valide: Average, Sum |
Invocations |
Il numero delle richieste Per ottenere il numero totale di richieste inviate a un endpoint di un modello, utilizza la statistica Sum. Unità: nessuna Statistiche valide: somma |
InvocationsPerCopy |
Il numero di invocazioni normalizzate da ogni copia di un componente di inferenza. Statistiche valide: somma |
InvocationsPerInstance |
Il numero di chiamate inviate a un modello, normalizzato da Unità: nessuna Statistiche valide: somma |
ModelLatency |
L'intervallo di tempo impiegato da un modello per rispondere a una richiesta di SageMaker Runtime API. Questo intervallo include il tempo che le comunicazioni locali impiegano per inviare la richiesta e recuperare la risposta dal container del modello e il tempo richiesto per completare l’inferenza nel container. Unità: microsecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi, percentili |
ModelSetupTime |
Il tempo necessario per lanciare nuove risorse di calcolo per un endpoint serverless. Il tempo può variare a seconda delle dimensioni del modello, del tempo necessario per scaricare il modello e dal tempo di avvio del container. Unità: microsecondi Statistiche valide: media, minimo, massimo, numero di esempi, percentili |
OverheadLatency |
Intervallo di tempo aggiunto al tempo impiegato per rispondere a una richiesta del client mediante l' SageMaker IA overhead. Questo intervallo viene misurato dal momento in cui l' SageMaker IA riceve la richiesta fino a quando non restituisce una risposta al client, meno il. Unità: microsecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi |
MidStreamErrors
|
Il numero di errori che si verificano durante lo streaming delle risposte dopo l'invio della risposta iniziale al cliente. Unità: nessuna Statistiche valide: Average, Sum |
FirstChunkLatency
|
Il tempo trascorso dal momento in cui la richiesta arriva all'endpoint SageMaker AI fino all'invio della prima parte della risposta al cliente. Questa metrica si applica alle richieste di inferenza in streaming bidirezionale. Unità: microsecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi, percentili |
FirstChunkModelLatency
|
Il tempo impiegato dal contenitore del modello per elaborare la richiesta e restituire la prima parte della risposta. Questo viene misurato dal momento in cui la richiesta viene inviata al contenitore del modello fino alla ricezione del primo byte dal modello. Questa metrica si applica alle richieste di inferenza in streaming bidirezionale. Unità: microsecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi, percentili |
FirstChunkOverheadLatency
|
La latenza di sovraccarico per il primo blocco, escluso il tempo di elaborazione del modello. Viene calcolato come valore Unità: microsecondi Statistiche valide: media, somma, minimo, massimo, numero di campioni, percentile |
| Dimensione | Description |
|---|---|
EndpointName, VariantName |
Filtra i parametri di invocazione dell'endpoint per il valore |
EndpointName, VariantName, InstanceType |
Filtra le metriche di chiamata degli endpoint per tipo di istanza per una variante di produzione che utilizza pool di istanze. Utilizza questa dimensione per visualizzare i modelli di invocazione per ogni tipo di istanza all'interno della variante. |
InferenceComponentName |
Filtra le metriche di invocazione dei componenti di inferenza. |
InstanceId |
Filtra le metriche di chiamata per un'istanza specifica. Disponibile quando |
ContainerId |
(Solo componenti di inferenza) Filtra le metriche di invocazione per un contenitore specifico. Disponibile quando |
SageMaker Metriche dei componenti di inferenza AI
Lo spazio dei /aws/sagemaker/InferenceComponents nomi include le seguenti metriche relative alle chiamate agli endpoint che ospitano componenti InvokeEndpointdi inferenza. Container-level la granularità è richiesta nella configurazione degli endpoint. EnableEnhancedMetrics=True MetricsConfig
I parametri sono disponibili a una frequenza di 1 minuto. È possibile configurare la frequenza di pubblicazione su 10, 30, 60, 120, 180, 240 o 300 secondi impostando. MetricPublishFrequencyInSeconds MetricsConfig Non è necessario EnableEnhancedMetrics abilitare questa impostazione. Quando si imposta EnableEnhancedMetrics suTrue, sono disponibili le dimensioni InstanceId aggiuntive e AcceleratorId (solo metriche GPU). ContainerId Per ulteriori informazioni, consulta Parametri avanzati di Amazon SageMaker AI per gli endpoint di inferenza.
| Metrica | Description |
|---|---|
CPUUtilizationNormalized |
Il valore della metrica |
GPUMemoryUtilizationNormalized |
Il valore della metrica |
GPUUtilizationNormalized |
Il valore della metrica |
MemoryUtilizationNormalized |
Il valore |
| Dimensione | Description |
|---|---|
InferenceComponentName |
Filtra le metriche dei componenti di inferenza. |
InferenceComponentName, InstanceType |
Filtra le metriche dei componenti di inferenza per tipo di istanza. Utilizza questa dimensione quando il componente di inferenza viene distribuito in una variante di produzione con pool di istanze per visualizzare le metriche per ogni tipo di istanza separatamente. |
InstanceId |
Filtra le metriche dei componenti di inferenza per un'istanza specifica. Disponibile quando |
ContainerId |
Filtra le metriche dei componenti di inferenza per un contenitore specifico. Disponibile quando |
AcceleratorId |
(Solo metriche GPU) Filtra le metriche dei componenti di inferenza per una GPU specifica. Disponibile quando è impostato su in |
SageMaker Metriche degli endpoint basati sull'intelligenza artificiale multimodello
Il AWS/SageMaker namespace include il seguente modello di caricamento delle metriche dalle chiamate a. InvokeEndpoint
I parametri sono disponibili a una frequenza di 1 minuto.
Per informazioni sulla durata di conservazione dei CloudWatch parametri, consulta GetMetricStatisticsAmazon CloudWatch API Reference.
| Metrica | Description |
|---|---|
ModelLoadingWaitTime |
L’intervallo di tempo in cui una richiesta di invocazione ha atteso il download o il caricamento o entrambe le operazioni del modello di destinazione per eseguire l’inferenza. Unità: microsecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi |
ModelUnloadingTime |
L'intervallo di tempo necessario per scaricare il modello tramite la chiamata API Unità: microsecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi |
ModelDownloadingTime |
L'intervallo di tempo impiegato per scaricare il modello da Amazon Simple Storage Service (Amazon S3). Unità: microsecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi |
ModelLoadingTime |
L'intervallo di tempo necessario per caricare il modello tramite la chiamata API Unità: microsecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi |
ModelCacheHit |
Numero di richieste La statistica media mostra il rapporto tra richieste per le quali il modello è già stato caricato. Unità: nessuna Statistiche valide: media, somma, numero di esempi |
| Dimensione | Description |
|---|---|
EndpointName, VariantName |
Filtra i parametri di invocazione dell'endpoint per il valore |
Gli spazi dei nomi /aws/sagemaker/Endpoints includono i seguenti parametri di istanza dalle chiamate a InvokeEndpoint.
I parametri sono disponibili a una frequenza di 1 minuto.
Per informazioni sulla durata di conservazione dei CloudWatch parametri, consulta GetMetricStatisticsAmazon CloudWatch API Reference.
| Metrica | Description |
|---|---|
LoadedModelCount |
Numero di modelli caricati nei container dell'endpoint a più modelli. Questo parametro viene emesso per istanza. La statistica media con un periodo di 1 minuto indica il numero medio di modelli caricati per istanza. La statistica somma indica il numero totale di modelli caricati in tutte le istanze dell'endpoint. I modelli tracciati da questo parametro non sono necessariamente univoci perché un modello potrebbe essere caricato in più container dell'endpoint. Unità: nessuna Statistiche valide: media, somma, minimo, massimo, numero di esempi |
| Dimensione | Description |
|---|---|
EndpointName, VariantName |
Filtra i parametri di invocazione dell'endpoint per il valore |
SageMaker Metriche relative ai lavori basati sull'intelligenza artificiale
I /aws/sagemaker/TransformJobs namespace /aws/sagemaker/ProcessingJobs/aws/sagemaker/TrainingJobs, e includono le seguenti metriche per i lavori di elaborazione, i lavori di formazione e i lavori di trasformazione in batch.
I parametri sono disponibili a una frequenza di 1 minuto.
Nota
Amazon CloudWatch supporta metriche personalizzate ad alta risoluzione e la sua risoluzione massima è di 1 secondo. Tuttavia, maggiore è la risoluzione, minore è la durata delle metriche. CloudWatch Per la risoluzione di frequenza di 1 secondo, le CloudWatch metriche sono disponibili per 3 ore. Per ulteriori informazioni sulla risoluzione e sulla durata delle CloudWatch metriche, consulta Amazon CloudWatch API GetMetricStatisticsReference.
Suggerimento
Per profilare il tuo lavoro di formazione con una risoluzione più precisa con una granularità fino a 100 millisecondi (0,1 secondi) e archiviare i parametri di formazione a tempo indeterminato in Amazon S3 per analisi personalizzate in qualsiasi momento, prendi in considerazione l'utilizzo di Amazon Debugger. SageMaker SageMaker Debugger fornisce regole integrate per rilevare automaticamente i problemi di formazione più comuni. Rileva i problemi di utilizzo delle risorse hardware (come CPU, GPU e colli di bottiglia). I/O Individua inoltre i problemi non convergenti del modello (ad esempio overfitting, gradienti che spariscono e tensori che esplodono). SageMaker Debugger fornisce anche visualizzazioni tramite Studio Classic e il relativo rapporto di profilazione. Per esplorare le visualizzazioni del Debugger, consulta Debugger Insights Dashboard Walkthrough, SageMaker Debugger Profiling Report Walkthrough e Analyze Data Using the SMDebug Client Library.
| Metrica | Description |
|---|---|
CPUUtilization |
La somma dell'utilizzo di ogni singolo core CPU. L'utilizzo della CPU di ciascun core è compreso tra 0 e 100. Ad esempio, se ci sono quattro CPU, il CPUUtilization va da 0% a 400%. Per le attività elaborazione, il valore è l'utilizzo della CPU del container di elaborazione nell'istanza.Per i processi di addestramento, il valore corrisponde all'utilizzo della CPU del container di algoritmi sull'istanza. Per i processi di trasformazione in batch, il valore corrisponde all'utilizzo della CPU del container di trasformazione sull'istanza. NotaIn caso di processi multi-istanza, ogni istanza riferisce i parametri di utilizzo della CPU. Tuttavia, la visualizzazione predefinita CloudWatch mostra l'utilizzo medio della CPU in tutte le istanze. Unità: percentuale |
DiskUtilization |
Percentuale di spazio su disco utilizzata dai container su un'istanza. Questo intervallo di valori è compreso tra 0% e 100%. Questo parametro non è supportato per i processi di trasformazione in batch. Per le attività di elaborazione, il valore è l'utilizzo dello spazio su disco del container di elaborazione nell'istanza.Per i processi di addestramento, il valore corrisponde all'utilizzo dello spazio su disco del container di algoritmi sull'istanza. Unità: percentuale NotaIn caso di processi multi-istanza, ogni istanza riferisce i parametri di utilizzo del disco. Tuttavia, la visualizzazione predefinita in CloudWatch mostra l'utilizzo medio del disco in tutte le istanze. |
GPUMemoryUtilization |
Percentuale di memoria GPU utilizzata dai container su un'istanza. Il valore varia da 0 e 100 ed è moltiplicato per il numero di GPU. Ad esempio, se ci sono quattro GPU, il Per i processi di addestramento, il valore corrisponde all'utilizzo di memoria GPU del container di algoritmi sull'istanza. Per i processi di trasformazione in batch, il valore corrisponde all'utilizzo di memoria GPU del container di trasformazione sull'istanza. NotaIn caso di processi multi-istanza, ogni istanza riferisce i parametri di utilizzo della memoria della GPU. Tuttavia, la visualizzazione predefinita in CloudWatch mostra l'utilizzo medio della memoria GPU in tutte le istanze. Unità: percentuale |
GPUUtilization |
Percentuale di unità GPU utilizzata dai container su un'istanza. Il valore può essere compreso tra 0 e 100 ed è moltiplicato per il numero di GPU. Ad esempio, se ci sono quattro GPU, il Per i processi di addestramento, il valore corrisponde all'utilizzo della GPU del container di algoritmi sull'istanza. Per i processi di trasformazione in batch, il valore corrisponde all'utilizzo della GPU del container di trasformazione sull'istanza. NotaIn caso di processi multi-istanza, ogni istanza riferisce i parametri di utilizzo della GPU. Tuttavia, la visualizzazione predefinita in CloudWatch mostra l'utilizzo medio della GPU in tutte le istanze. Unità: percentuale |
MemoryUtilization |
Percentuale di memoria utilizzata dai container su un'istanza. Questo intervallo di valori è compreso tra 0% e 100%. Per le attività di elaborazione, il valore è l'utilizzo della memoria del container di elaborazione nell'istanza.Per i processi di addestramento, il valore corrisponde all'utilizzo della memoria del container di algoritmi sull'istanza. Per i processi di trasformazione in batch, il valore corrisponde all'utilizzo della memoria del container di trasformazione sull'istanza. Unità: percentuale NotaIn caso di processi multi-istanza, ogni istanza riferisce i parametri di utilizzo della memoria. Tuttavia, la visualizzazione predefinita in CloudWatch mostra l'utilizzo medio della memoria in tutte le istanze. |
| Dimensione | Description |
|---|---|
Host |
Per le attività di elaborazione, il valore di questa dimensione ha il formato Per i processi di addestramento, il valore di questa dimensione ha il formato Per i processi di trasformazione in batch, il valore di questa dimensione ha il formato |
SageMaker Metriche dei lavori di Inference Recommender
Lo spazio dei nomi /aws/sagemaker/InferenceRecommendationsJobs include i seguenti parametri per i processi di raccomandazione dell'inference.
| Metrica | Description |
|---|---|
ClientInvocations |
Il numero di richieste Unità: nessuna Statistiche valide: somma |
ClientInvocationErrors |
Il numero di richieste Unità: nessuna Statistiche valide: somma |
ClientLatency |
L'intervallo di tempo impiegato tra l'invio di una chiamata Unità: millisecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi, percentili |
NumberOfUsers |
Il numero di utenti simultanei che inviano richieste Unità: nessuna Statistiche valide: massimo, minimo, medio |
| Dimensione | Description |
|---|---|
JobName |
Filtra i parametri del processo del Suggeritore di inferenza per il processo del Suggeritore di inferenza specificato. |
EndpointName |
Filtra i parametri del processo del Suggeritore di inferenza per l’endpoint specificato. |
SageMaker Metriche di Ground Truth
| Metrica | Description |
|---|---|
ActiveWorkers |
Un singolo worker attivo in un team di lavoro privato ha inviato, rilasciato o rifiutato un'attività. Per ottenere il numero totale di worker attivi, utilizza la statistica Sum (Somma). Ground Truth tenta di fornire ogni singolo evento Unità: nessuna Statistiche valide: Sum, Sample Count |
DatasetObjectsAutoAnnotated |
Il numero di oggetti del set di dati annotati automaticamente in un processo di etichettatura. Questo parametro viene emesso solo quando è abilitata l'etichettatura automatizzata. Per visualizzare l'avanzamento del processo di etichettatura, utilizza il parametro Max. Unità: nessuna Statistiche valide: Max |
DatasetObjectsHumanAnnotated |
Il numero di oggetti del set di dati annotati da persone in un processo di etichettatura. Per visualizzare l'avanzamento del processo di etichettatura, utilizza il parametro Max. Unità: nessuna Statistiche valide: Max |
DatasetObjectsLabelingFailed |
Il numero di oggetti del set di dati in cui si è verificato un errore di etichettatura in un processo di etichettatura. Per visualizzare l'avanzamento del processo di etichettatura, utilizza il parametro Max. Unità: nessuna Statistiche valide: Max |
JobsFailed |
Un singolo processo di etichettatura non è riuscito. Per ottenere il numero totale di processi di etichettatura non riusciti, utilizza la statistica Sum. Unità: nessuna Statistiche valide: Sum, Sample Count |
JobsSucceeded |
Un singolo processo di etichettatura è riuscito. Per ottenere il numero totale di processi di etichettatura riusciti, utilizza la statistica Sum. Unità: nessuna Statistiche valide: Sum, Sample Count |
JobsStopped |
Un singolo processo di etichettatura è stato interrotto. Per ottenere il numero totale di processi di etichettatura interrotti, utilizza la statistica Sum. Unità: nessuna Statistiche valide: Sum, Sample Count |
TasksAccepted |
Un singolo compito è stato accettato da un worker. Per ottenere il numero totale di attività accettate dai worker, utilizza la statistica Sum (Somma). Ground Truth tenta di fornire ogni singolo evento Unità: nessuna Statistiche valide: Sum, Sample Count |
TasksDeclined |
Un singolo compito è stato rifiutato da un worker. Per ottenere il numero totale di attività rifiutate dai worker, utilizza la statistica Sum (Somma). Ground Truth tenta di fornire ogni singolo evento Unità: nessuna Statistiche valide: Sum, Sample Count |
TasksReturned |
È stata restituita una singola attività. Per ottenere il numero totale di attività restituite, utilizza la statistica Sum (Somma). Ground Truth tenta di fornire ogni singolo evento Unità: nessuna Statistiche valide: Sum, Sample Count |
TasksSubmitted |
Un singolo compito era svolto submitted/completed da un lavoratore privato. Per ottenere il numero totale di attività inviate dai worker, utilizza la statistica Sum (Somma). Ground Truth tenta di fornire ogni singolo evento Unità: nessuna Statistiche valide: Sum, Sample Count |
TimeSpent |
Tempo trascorso su un'attività completata da un worker privato. Questo parametro non include il tempo in cui un worker si è fermato o si è preso una pausa. Ground Truth tenta di fornire ogni evento Unità: secondi Statistiche valide: Sum, Sample Count |
TotalDatasetObjectsLabeled |
Il numero di oggetti del set di dati completati correttamente in un processo di etichettatura. Per visualizzare l'avanzamento del processo di etichettatura, utilizza il parametro Max. Unità: nessuna Statistiche valide: Max |
| Dimensione | Description |
|---|---|
LabelingJobName |
Filtra i parametri per il conteggio degli oggetti del set di dati per un processo di etichettatura. |
Metriche SageMaker di Amazon Feature Store
| Metrica | Description |
|---|---|
ConsumedReadRequestsUnits |
Il numero di unità di lettura consumate nel periodo di tempo specificato. È possibile recuperare le unità di lettura consumate da un'operazione di runtime dell'archivio funzionalità e il relativo gruppo di funzionalità corrispondente. Unità: nessuna Statistiche valide: tutte |
ConsumedWriteRequestsUnits |
Il numero di unità di scrittura consumate nel periodo di tempo specificato. È possibile recuperare le unità di scrittura consumate da un'operazione di runtime dell'archivio funzionalità e il relativo gruppo di funzionalità corrispondente. Unità: nessuna Statistiche valide: tutte |
ConsumedReadCapacityUnits |
Il numero di unità di capacità di lettura assegnate consumate nel periodo di tempo specificato. È possibile recuperare le unità di capacità di lettura da un’operazione di runtime dell’archivio delle caratteristiche e il gruppo di funzionalità corrispondente. Unità: nessuna Statistiche valide: tutte |
ConsumedWriteCapacityUnits |
Il numero di unità di capacità di scrittura assegnate consumate nel periodo di tempo specificato. È possibile recuperare le unità di capacità di scrittura da un’operazione di runtime dell’archivio delle caratteristiche e il gruppo di funzionalità corrispondente. Unità: nessuna Statistiche valide: tutte |
| Dimensione | Description |
|---|---|
FeatureGroupName, OperationName |
Filtra i parametri di utilizzo del runtime dell'archivio funzionalità del gruppo di funzionalità e dell'operazione che hai specificato. |
| Metrica | Description |
|---|---|
Invocations |
Il numero di richieste effettuate alle operazioni di runtime dell'archivio funzionalità nel periodo di tempo specificato. Unità: nessuna Statistiche valide: somma |
Operation4XXErrors |
Il numero di richieste effettuate alle operazioni di runtime dell'archivio funzionalità in cui l'operazione ha restituito un codice di risposta HTTP 4xx. Per ogni risposta 4xx, viene inviato 1; altrimenti, viene inviato 0. Unità: nessuna Statistiche valide: Average, Sum |
Operation5XXErrors |
Il numero di richieste effettuate alle operazioni di runtime dell'archivio funzionalità in cui l'operazione ha restituito un codice di risposta HTTP 5xx. Per ogni risposta 5xx, viene inviato 1; altrimenti, viene inviato 0. Unità: nessuna Statistiche valide: Average, Sum |
ThrottledRequests |
Il numero di richieste effettuate alle operazioni di runtime dell'archivio funzionalità in cui la richiesta è stata limitata. Per ogni richieste di limitazione, viene inviato 1; in caso contrario, viene inviato 0. Unità: nessuna Statistiche valide: Average, Sum |
Latency |
L'intervallo di tempo per l'elaborazione delle richieste effettuate alle operazioni di runtime dell'archivio funzionalità. Questo intervallo viene misurato dal momento in cui l' SageMaker IA riceve la richiesta fino a quando non restituisce una risposta al client. Unità: microsecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi, percentili |
| Dimensione | Description |
|---|---|
|
|
Filtra i parametri operativi del runtime dell'archivio funzionalità del gruppo di funzionalità e dell'operazione che hai specificato. È possibile utilizzare queste dimensioni per operazioni non in batch, ad esempio GetRecord PutRecord, e DeleteRecord. |
OperationName |
Filtra i parametri operativi del runtime dell'archivio funzionalità dell'operazione che hai specificato. È possibile utilizzare questa dimensione per operazioni batch come BatchGetRecord. |
SageMaker metriche delle pipeline
Lo spazio dei nomi AWS/Sagemaker/ModelBuildingPipeline include i seguenti parametri per le esecuzioni di pipeline.
Sono disponibili due categorie di metriche di esecuzione della pipeline:
-
Parametri di esecuzione su tutte le Pipeline: parametri di esecuzione di pipeline a livello di account (per tutte le pipeline dell'account corrente)
-
Parametri di esecuzione per pipeline: parametri di esecuzione di pipeline per pipeline
I parametri sono disponibili a una frequenza di 1 minuto.
| Metrica | Description |
|---|---|
ExecutionStarted |
Il numero di esecuzioni di pipeline avviate. Unità: numero Statistiche valide: Average, Sum |
ExecutionFailed |
Il numero di esecuzioni di pipeline non riuscite. Unità: numero Statistiche valide: Average, Sum |
ExecutionSucceeded |
Il numero di esecuzioni di pipeline che hanno avuto esito positivo. Unità: numero Statistiche valide: Average, Sum |
ExecutionStopped |
Il numero di esecuzioni di pipeline arrestate. Unità: numero Statistiche valide: Average, Sum |
ExecutionDuration |
La durata in millisecondi dell'esecuzione della pipeline. Unità: millisecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi |
| Dimensione | Description |
|---|---|
PipelineName |
Filtra i parametri di esecuzione di pipeline per una pipeline specificata. |
Lo spazio dei nomi AWS/Sagemaker/ModelBuildingPipeline include i seguenti parametri per le fasi di pipeline.
I parametri sono disponibili a una frequenza di 1 minuto.
| Metrica | Description |
|---|---|
StepStarted |
Il numero di fasi di esecuzione del flusso avviate. Unità: numero Statistiche valide: Average, Sum |
StepFailed |
Il numero di fasi non riuscite. Unità: numero Statistiche valide: Average, Sum |
StepSucceeded |
Il numero di fasi che hanno avuto esito positivo. Unità: numero Statistiche valide: Average, Sum |
StepStopped |
Il numero di fasi arrestate. Unità: numero Statistiche valide: Average, Sum |
StepDuration |
La durata in millisecondi dell'esecuzione della fase. Unità: millisecondi Statistiche valide: media, somma, minimo, massimo, numero di esempi |
| Dimensione | Description |
|---|---|
PipelineName, StepName |
Filtra i parametri delle fasi per una pipeline e una fase specificate. |
