Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Inizia con gli script del ciclo di vita di base forniti da HyperPod
Questa sezione illustra ogni componente del flusso di base di configurazione di Slurm on HyperPod con un approccio dall'alto verso il basso. Inizia dalla preparazione di una richiesta di creazione HyperPod del cluster su cui eseguire e approfondisce la CreateCluster API struttura gerarchica fino agli script del ciclo di vita. Utilizza gli script di esempio relativi al ciclo di vita forniti nell'archivio Awsome Distributed Training. GitHub
git clone https://github.com/aws-samples/awsome-distributed-training/
Gli script del ciclo di vita di base per la configurazione di un cluster Slurm sono disponibili all'indirizzo. SageMaker HyperPod 1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
cd awsome-distributed-training/1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
Il seguente diagramma di flusso mostra una panoramica dettagliata di come progettare gli script del ciclo di vita di base. Le descrizioni sotto il diagramma e la guida procedurale spiegano come funzionano durante la chiamata. HyperPod CreateCluster API
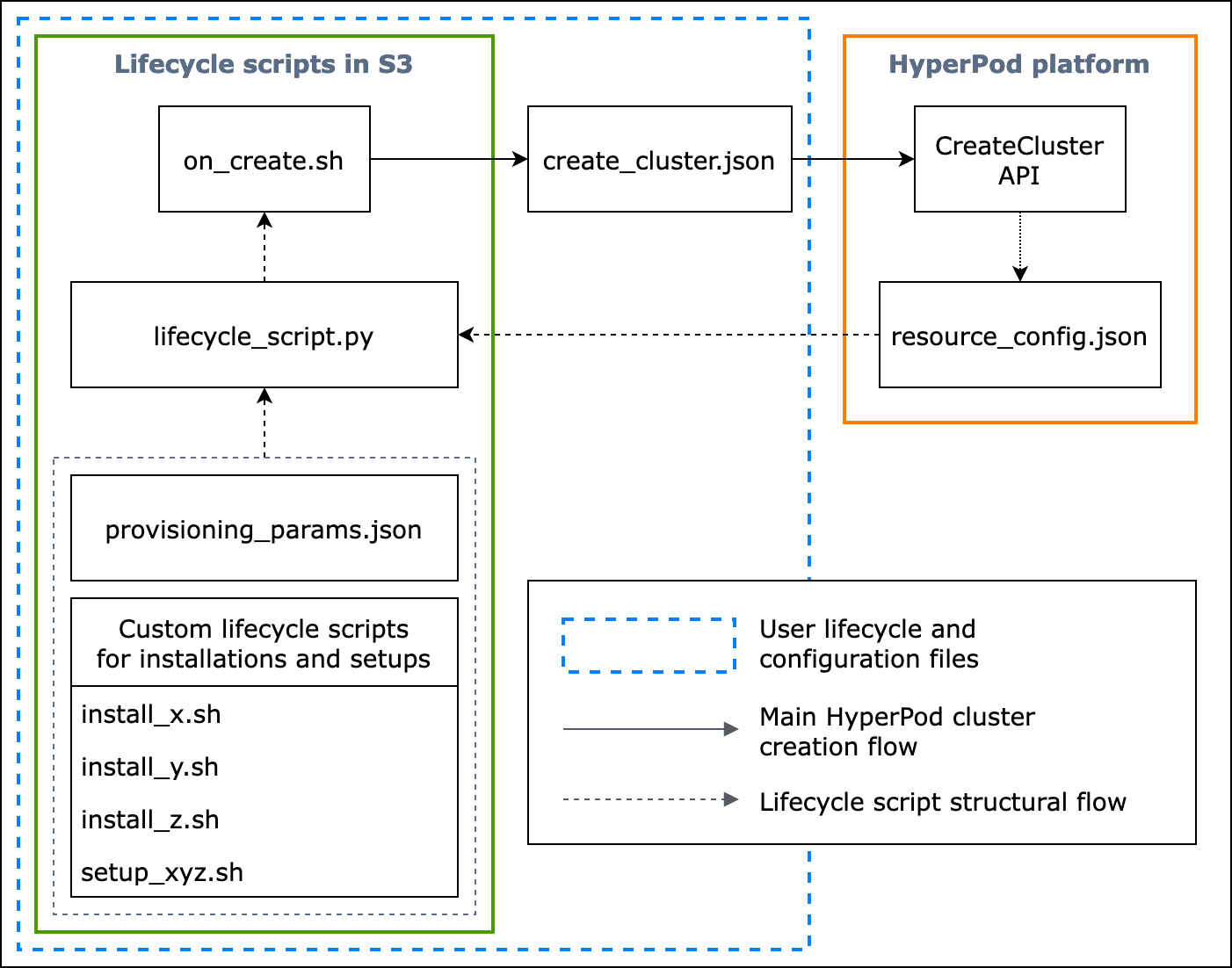
Figura: Un diagramma di flusso dettagliato della creazione dei HyperPod cluster e della struttura degli script del ciclo di vita. (1) Le frecce tratteggiate indicano il punto in cui vengono «richiamate» le caselle e mostrano il flusso dei file di configurazione e la preparazione degli script del ciclo di vita. Inizia dalla preparazione e dal ciclo di vita degli script. provisioning_parameters.json Questi vengono quindi codificati lifecycle_script.py per un'esecuzione collettiva. E l'esecuzione dello lifecycle_script.py script viene eseguita dallo script di on_create.sh shell, che deve essere eseguito nel terminale di HyperPod istanza. (2) Le frecce piene mostrano il flusso principale di creazione del HyperPod cluster e il modo in cui le caselle vengono «richiamate» o «inviate a». on_create.shè necessario per la richiesta di creazione del cluster, nel modulo Crea una richiesta di cluster create_cluster.json o nel modulo Crea una richiesta di cluster nell'interfaccia utente della console. Dopo aver inviato la richiesta, la HyperPod esegue CreateCluster API in base alle informazioni di configurazione fornite dalla richiesta e dagli script del ciclo di vita. (3) La freccia punteggiata indica che la HyperPod piattaforma crea istanze resource_config.json nel cluster durante il provisioning delle risorse del cluster. resource_config.jsoncontiene informazioni sulle risorse HyperPod del cluster come il clusterARN, i tipi di istanza e gli indirizzi IP. È importante notare che è necessario preparare gli script del ciclo di vita in modo che prevedano il resource_config.json file durante la creazione del cluster. Per ulteriori informazioni, consulta la guida procedurale riportata di seguito.
La seguente guida procedurale spiega cosa succede durante la creazione del HyperPod cluster e come sono progettati gli script del ciclo di vita di base.
-
create_cluster.json— Per inviare una richiesta di creazione di un HyperPod cluster, si prepara un file diCreateClusterrichiesta in formato. JSON In questo esempio di best practice, si presuppone che il file di richiesta abbia un nomecreate_cluster.json. Scrivicreate_cluster.jsonper fornire gruppi di istanze a un HyperPod cluster. La best practice consiste nell'aggiungere lo stesso numero di gruppi di istanze del numero di nodi Slurm che intendi configurare sul HyperPod cluster. Assicurati di assegnare nomi distintivi ai gruppi di istanze che assegnerai ai nodi Slurm che intendi configurare.Inoltre, devi specificare un bucket path S3 per memorizzare l'intero set di file di configurazione e script del ciclo di vita nel nome del campo
InstanceGroups.LifeCycleConfig.SourceS3Urinel modulo diCreateClusterrichiesta e specificare il nome del file di uno script di shell entrypoint (supponiamo che abbia un nome) a.on_create.shInstanceGroups.LifeCycleConfig.OnCreateNota
Se utilizzi il modulo di invio Crea un cluster nell'interfaccia utente della console, la HyperPod console gestisce la compilazione e l'invio della
CreateClusterrichiesta per tuo conto e la esegue nel backend.CreateClusterAPI In questo caso, non è necessario crearecreate_cluster.json, ma assicurati di specificare le informazioni corrette sulla configurazione del cluster nel modulo di invio per la creazione di un cluster. -
on_create.sh— Per ogni gruppo di istanze, è necessario fornire uno script di shell entrypoint per eseguire comandion_create.sh, eseguire script per installare pacchetti software e configurare l'ambiente del HyperPod cluster con Slurm. Le due cose da preparare sono unaprovisioning_parameters.jsonnecessaria per configurare Slurm e un set di script del ciclo di vita HyperPod per l'installazione dei pacchetti software. Questo script deve essere scritto per trovare ed eseguire i seguenti file, come mostrato nello script di esempio all'indirizzo.on_create.shNota
Assicurati di caricare l'intero set di script del ciclo di vita nella posizione S3 specificata.
create_cluster.jsonInoltre, dovresti collocare il tuoprovisioning_parameters.jsonnella stessa posizione.-
provisioning_parameters.json— Questo è unModulo di configurazione per il provisioning dei nodi Slurm su HyperPod. Loon_create.shscript trova questo JSON file e definisce la variabile di ambiente per identificarne il percorso. Tramite questo JSON file, puoi configurare nodi Slurm e opzioni di storage come Amazon FSx for Lustre for Slurm con cui comunicare. Quindiprovisioning_parameters.json, assicurati di assegnare i gruppi di istanze del HyperPod cluster utilizzando i nomi specificati ai nodi Slurm in modo appropriato in basecreate_cluster.jsona come intendi configurarli.Il diagramma seguente mostra un esempio di come i due file di JSON configurazione
provisioning_parameters.jsondevono essere scritti per HyperPod assegnarecreate_cluster.jsongruppi di istanze ai nodi Slurm. In questo esempio, ipotizziamo un caso di configurazione di tre nodi Slurm: nodo controller (gestione), nodo di log-in (che è opzionale) e nodo di calcolo (worker).Suggerimento
Per aiutarti a convalidare questi due JSON file, il team di HyperPod assistenza fornisce uno script di convalida,.
validate-config.pyPer ulteriori informazioni, consulta Convalida i file di JSON configurazione prima di creare un cluster Slurm su HyperPod. 
Figura: Confronto diretto tra la configurazione
create_cluster.jsonper la creazione di HyperPod cluster e quellaprovisiong_params.jsonper Slurm. Il numero di gruppi di istanze in essocreate_cluster.jsoncontenuti deve corrispondere al numero di nodi che si desidera configurare come nodi Slurm. Nel caso dell'esempio in figura, tre nodi Slurm verranno configurati su un HyperPod cluster di tre gruppi di istanze. È necessario assegnare i gruppi di istanze del HyperPod cluster ai nodi Slurm specificando di conseguenza i nomi dei gruppi di istanze. -
resource_config.json— Durante la creazione del cluster, lolifecycle_script.pyscript viene scritto in modo da aspettarsi un file da.resource_config.jsonHyperPod Questo file contiene informazioni sul cluster, come i tipi di istanze e gli indirizzi IP.Quando si esegue
CreateClusterAPI, HyperPod crea un file di configurazione delle risorse in/opt/ml/config/resource_config.jsonbase alcreate_cluster.jsonfile. Il percorso del file viene salvato nella variabile di ambiente denominataSAGEMAKER_RESOURCE_CONFIG_PATH.Importante
Il
resource_config.jsonfile viene generato automaticamente dalla HyperPod piattaforma e NOT devi crearlo. Il codice seguente serve a mostrare un esempio diresource_config.jsonciò che verrebbe creato dalla creazione del clustercreate_cluster.jsonin base al passaggio precedente e per aiutarti a capire cosa succede nel backend e comeresource_config.jsonapparirebbe un file generato automaticamente.{ "ClusterConfig": { "ClusterArn": "arn:aws:sagemaker:us-west-2:111122223333:cluster/abcde01234yz", "ClusterName": "your-hyperpod-cluster" }, "InstanceGroups": [ { "Name": "controller-machine", "InstanceType": "ml.c5.xlarge", "Instances": [ { "InstanceName": "controller-machine-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "login-group", "InstanceType": "ml.m5.xlarge", "Instances": [ { "InstanceName": "login-group-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "compute-nodes", "InstanceType": "ml.trn1.32xlarge", "Instances": [ { "InstanceName": "compute-nodes-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-2", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-3", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-4", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] } ] } -
lifecycle_script.py— Questo è lo script Python principale che esegue collettivamente gli script del ciclo di vita impostando Slurm sul cluster durante il provisioning. HyperPod Questo script leggeresource_config.jsondaprovisioning_parameters.jsone verso i percorsi specificati o identificati inon_create.sh, passa le informazioni pertinenti a ogni script del ciclo di vita e quindi esegue gli script del ciclo di vita nell'ordine.Gli script del ciclo di vita sono un set di script personalizzabili con la massima flessibilità per installare pacchetti software e configurare configurazioni necessarie o personalizzate durante la creazione di cluster, come la configurazione di Slurm, la creazione di utenti, l'installazione di Conda o Docker.
lifecycle_script.pyLo script di esempio è pronto per eseguire altri script del ciclo di vita di base nel repository, come l'avvio di Slurm deamons () start_slurm.sh, il montaggio di Amazon FSx for Lustre () e la configurazione di MariaDB accounting () mount_fsx.she accounting (). setup_mariadb_accounting.shRDSsetup_rds_accounting.shPuoi anche aggiungere altri script, impacchettarli nella stessa directory e aggiungere righe di codice per consentire l'esecuzione degli script. lifecycle_script.pyHyperPod Per ulteriori informazioni sugli script del ciclo di vita di base, consulta anche gli script del ciclo di vita 3.1 nell'archivio Awsome Distributed Training. GitHub Nota
HyperPod viene eseguito SageMaker HyperPod DLAMI su ogni istanza di un cluster e AMI dispone di pacchetti software preinstallati che garantiscono la compatibilità tra essi e le funzionalità. HyperPod Tieni presente che se reinstalli uno qualsiasi dei pacchetti preinstallati, sei responsabile dell'installazione dei pacchetti compatibili e tieni presente che alcune HyperPod funzionalità potrebbero non funzionare come previsto.
Oltre alle configurazioni predefinite, nella cartella sono disponibili altri script per l'installazione dei seguenti software.
utilsIl lifecycle_script.pyfile è già pronto per includere righe di codice per l'esecuzione degli script di installazione, quindi consultate i seguenti elementi per cercare in quelle righe e decommentare per attivarle.-
Le seguenti righe di codice servono per installare Docker
, Enroot e Pyxis. Questi pacchetti sono necessari per eseguire contenitori Docker su un cluster Slurm. Per abilitare questa fase di installazione, imposta il
enable_docker_enroot_pyxisparametro suTruenel file.config.py# Install Docker/Enroot/Pyxis if Config.enable_docker_enroot_pyxis: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_enroot_pyxis.sh").run(node_type) -
Puoi integrare il tuo HyperPod cluster con Amazon Managed Service for Prometheus e Amazon Managed Grafana per esportare i parametri relativi al cluster e ai nodi HyperPod del cluster nelle dashboard di Amazon Managed Grafana. Per esportare i parametri e utilizzare la dashboard Slurm, la dashboard NVIDIA
DCGMExporter e la dashboard EFAMetrics su Amazon Managed Grafana, devi installare l'esportatore Slurm per Prometheus, l'esportatore e l'esportatore di nodi. NVIDIA DCGM EFA Per ulteriori informazioni sull'installazione dei pacchetti exporter e sull'utilizzo delle dashboard Grafana in un'area di lavoro Amazon Managed Grafana, consulta. SageMaker HyperPod monitoraggio delle risorse del cluster Per abilitare questa fase di installazione, imposta il
enable_observabilityparametro su nel file.Trueconfig.py# Install metric exporting software and Prometheus for observability if Config.enable_observability: if node_type == SlurmNodeType.COMPUTE_NODE: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_dcgm_exporter.sh").run() ExecuteBashScript("./utils/install_efa_node_exporter.sh").run() if node_type == SlurmNodeType.HEAD_NODE: wait_for_scontrol() ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_slurm_exporter.sh").run() ExecuteBashScript("./utils/install_prometheus.sh").run()
-
-
-
Assicurati di caricare tutti i file di configurazione e gli script di configurazione dal passaggio 2 nel bucket S3 fornito nella
CreateClusterrichiesta nel passaggio 1. Ad esempio, supponiamo che il tuocreate_cluster.jsonabbia quanto segue."LifeCycleConfig": { "SourceS3URI": "s3://sagemaker-hyperpod-lifecycle/src", "OnCreate": "on_create.sh" }Quindi,
"s3://sagemaker-hyperpod-lifecycle/src"dovresti contenereon_create.sh,lifecycle_script.pyprovisioning_parameters.json, e tutti gli altri script di configurazione. Si supponga di aver preparato i file in una cartella locale come segue.└── lifecycle_files // your local folder ├── provisioning_parameters.json ├── on_create.sh ├── lifecycle_script.py └── ... // more setup scrips to be fed into lifecycle_script.pyPer caricare i file, utilizzate il comando S3 come segue.
aws s3 cp --recursive./lifecycle_scriptss3://sagemaker-hyperpod-lifecycle/src
