Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ambienti RL in Amazon SageMaker AI
Amazon SageMaker AI RL utilizza gli ambienti per imitare gli scenari del mondo reale. Dato lo stato corrente dell'ambiente e un'azione eseguita dall'agente o dagli agenti, il simulatore elabora l'impatto dell'operazione e restituisce lo stato successivo e una ricompensa. I simulatori sono utili nei casi in cui non è sicuro eseguire l’addestramento di un agente in un contesto reale (ad esempio, far volare un drone) o se l'algoritmo RL richiede molto tempo per convergere (per esempio, quando si gioca a scacchi).
Il seguente diagramma mostra un esempio delle interazioni con un simulatore per un gioco di corse automobilistiche.
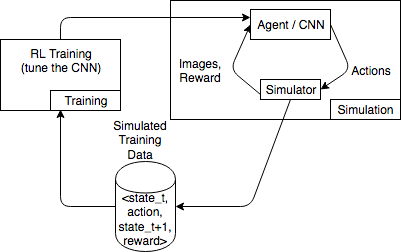
L'ambiente di simulazione è costituito da un agente e da un simulatore. Qui, una rete neurale convoluzionale (CNN) utilizza immagini del simulatore e genera azioni per controllare il controller di gioco. Con più simulazioni, questo ambiente genera dati di addestramento nel formato state_t, action, state_t+1 e reward_t+1. La definizione della ricompensa non è banale e influenza la qualità del modello RL. Vogliamo fornire alcuni esempi di funzioni ricompensa, rendendole però configurabili dall'utente.
Argomenti
Usa l'interfaccia OpenAI Gym per ambienti in SageMaker AI RL
Per utilizzare gli ambienti OpenAI Gym in SageMaker AI RL, utilizza i seguenti elementi API. Per ulteriori informazioni su OpenAI Gym, consulta la documentazione di Gym
-
env.action_space: definisce le azioni che l'agente può effettuare, specifica se ogni azione è continua o discreta e specifica il minimo e il massimo se l'azione è continua. -
env.observation_space: definisce le osservazioni che l'agente riceve dall'ambiente, nonché il minimo e il massimo per le osservazioni continue. -
env.reset(): inizializza un episodio di addestramento. La funzionereset()restituisce lo stato iniziale dell'ambiente e l'agente utilizza lo stato iniziale per effettuare la prima azione. L'azione viene quindi inviata astep()ripetutamente finché l'episodio non raggiunge uno stato terminale. Quandostep()restituiscedone = True, l'episodio termina. Il kit di strumenti RL re-inizializza l'ambiente chiamandoreset(). -
step(): prende l'operazione dell'agente come input e restituisce lo stato successivo dell'ambiente, la ricompensa, se l'episodio è terminato e un dizionarioinfoper comunicare le informazioni di debug. La convalida degli input è responsabilità dell'ambiente. -
env.render(): utilizzato per ambienti che dispongono di visualizzazione. Il kit di strumenti RL chiama questa funzione per acquisire visualizzazioni dell'ambiente dopo ogni chiamata alla funzionestep().
Usa gli ambienti Open-Source
Puoi utilizzare ambienti open source, come EnergyPlus and RoboSchool, in SageMaker AI RL creando il tuo contenitore. Per ulteriori informazioni su EnergyPlus, vedere https://energyplus.net/
Utilizzo di ambienti commerciali
Puoi utilizzare ambienti commerciali, come MATLAB e Simulink, in SageMaker AI RL creando il tuo container. Devi gestire le tue licenze.
