Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Training del modello
La fase di addestramento dell'intero ciclo di vita di machine learning (ML) va dall'accesso al set di dati di addestramento alla generazione di un modello finale e alla selezione del modello più performante per la distribuzione. Le sezioni seguenti forniscono una panoramica delle funzionalità e delle risorse di SageMaker formazione disponibili, con informazioni tecniche approfondite per ciascuna di esse.
L'architettura di base della formazione SageMaker
Se utilizzi l' SageMaker intelligenza artificiale per la prima volta e desideri trovare una soluzione ML rapida per addestrare un modello sul tuo set di dati, prendi in considerazione l'utilizzo di una soluzione senza codice o low-code come SageMaker Canvas, JumpStartall'interno di SageMaker Studio Classic o Autopilot. SageMaker
Per esperienze di programmazione di livello intermedio, prendi in considerazione l'utilizzo di un notebook Studio Classic o di Notebook Instances. SageMaker SageMaker Per iniziare, segui le istruzioni riportate nella guida SageMaker AI Eseguire il training di un modello Getting Started. Si consiglia di utilizzare questa opzione per i casi d'uso in cui si crea il proprio modello e lo script di addestramento utilizzando un framework di ML.
Il fulcro dei lavori di SageMaker intelligenza artificiale è la containerizzazione dei carichi di lavoro ML e la capacità di gestire le risorse di elaborazione. La piattaforma di SageMaker formazione si occupa del carico di lavoro associato alla configurazione e alla gestione dell'infrastruttura per i carichi di lavoro di formazione ML. Con SageMaker Training, puoi concentrarti sullo sviluppo, l'addestramento e la messa a punto del tuo modello.
Il seguente diagramma di architettura mostra come l' SageMaker intelligenza artificiale gestisce i lavori di formazione ML ed effettua il provisioning delle istanze Amazon EC2 per conto SageMaker degli utenti di intelligenza artificiale. Come utente di SageMaker intelligenza artificiale puoi portare il tuo set di dati di addestramento, salvandolo su Amazon S3. Puoi scegliere un modello di formazione ML tra gli algoritmi integrati di SageMaker intelligenza artificiale disponibili o utilizzare il tuo script di formazione con un modello costruito con i più diffusi framework di machine learning.
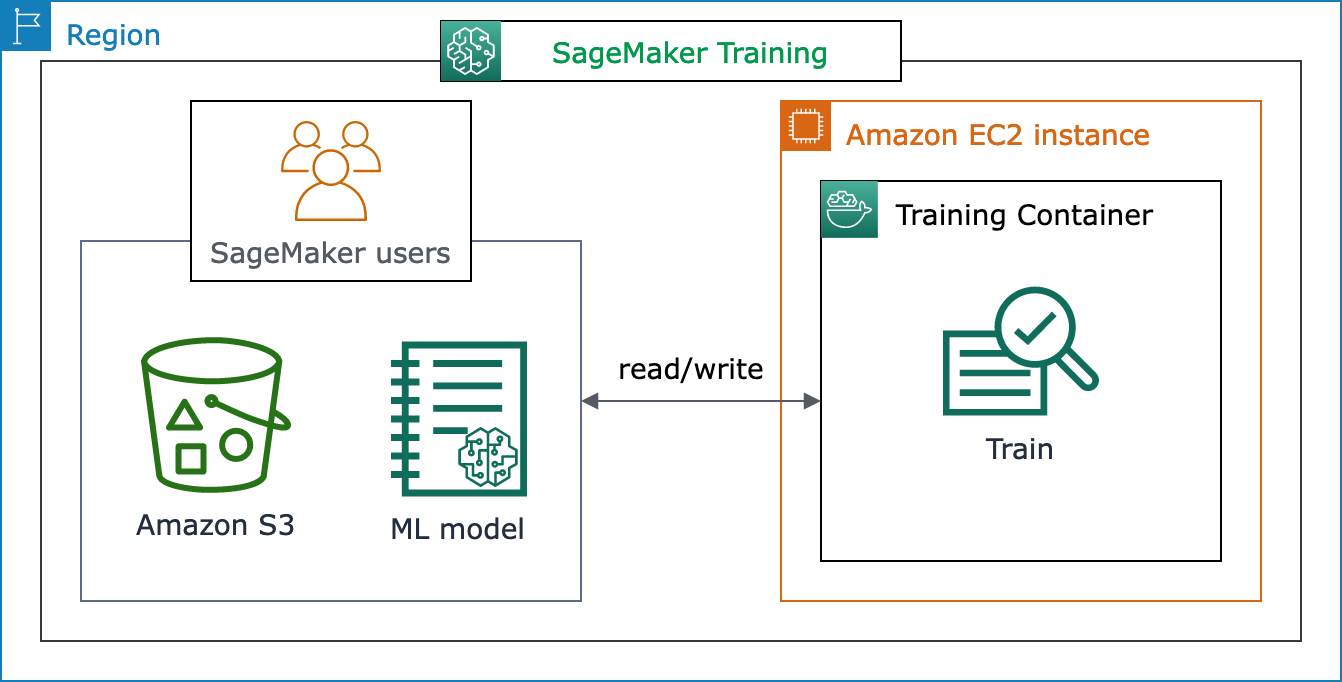
Visualizzazione completa del flusso di lavoro e delle SageMaker funzionalità della formazione
L'intero percorso di addestramento di ML coinvolge attività che vanno oltre l'importazione dei dati nei modelli di ML, l’addestramento dei modelli sulle istanze di calcolo e l'ottenimento degli artefatti e degli output del modello. È necessario valutare ogni fase prima, durante e dopo l’addestramento per assicurarsi che il modello sia ben addestrato e che raggiunga l'accuratezza desiderata per i propri obiettivi.
Il seguente diagramma di flusso mostra una panoramica di alto livello delle tue azioni (in riquadri blu) e delle funzionalità di SageMaker formazione disponibili (in riquadri blu chiaro) durante la fase di formazione del ciclo di vita del machine learning.
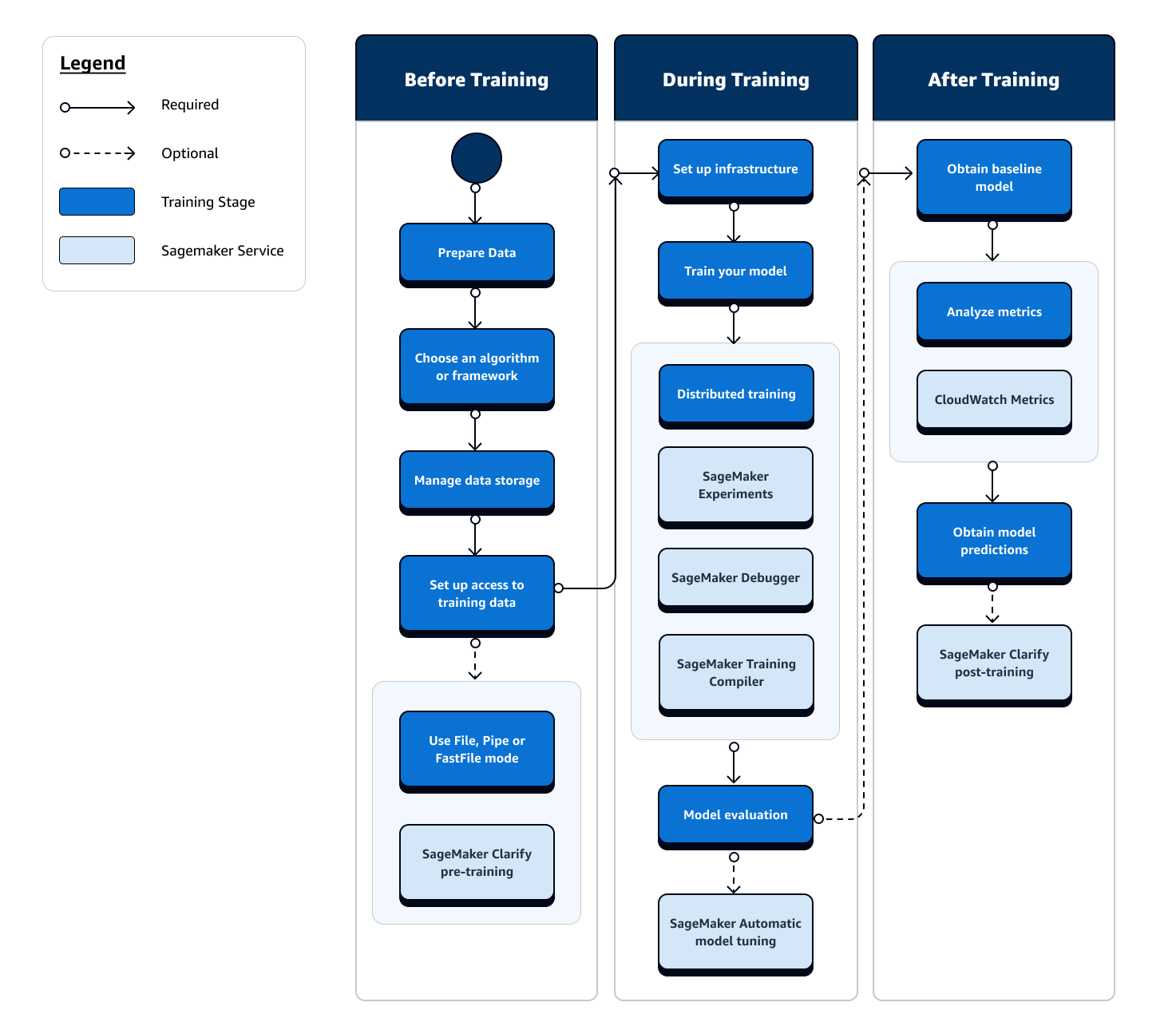
Le seguenti sezioni illustrano ogni fase della formazione illustrata nel diagramma di flusso precedente e le utili funzionalità offerte dall' SageMaker IA nelle tre fasi secondarie della formazione ML.
Prima dell’addestramento
Prima dell’addestramento è necessario considerare una serie di scenari per l'impostazione delle risorse e dell'accesso ai dati. Per avere un'idea delle decisioni da prendere, fai riferimento al diagramma seguente e ai dettagli di ogni fase precedente all’addestramento.
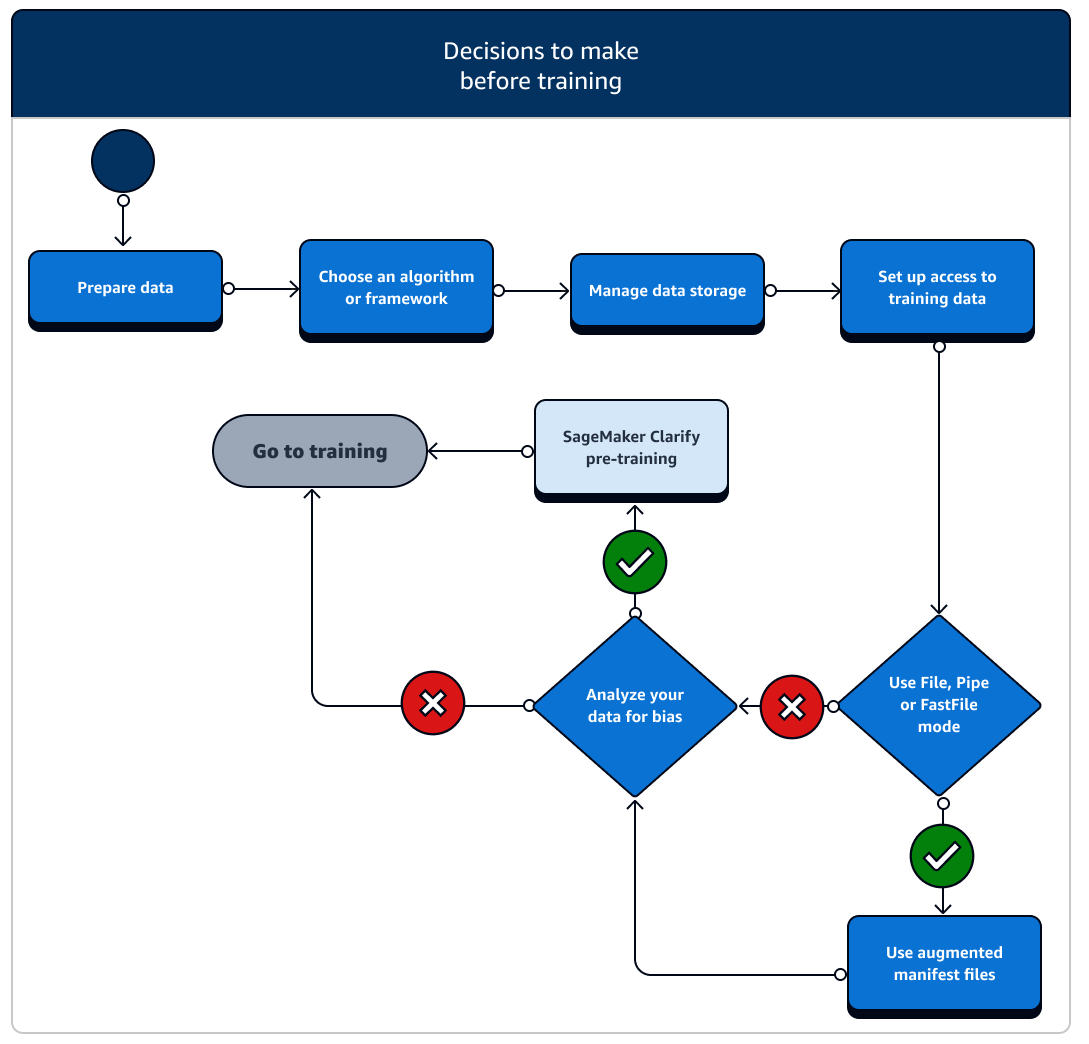
-
Preparazione dei dati: prima dell'addestramento, è necessario aver completato la pulizia dei dati e la progettazione delle funzionalità durante la fase di preparazione dei dati. SageMaker L'intelligenza artificiale dispone di diversi strumenti di etichettatura e progettazione delle funzionalità per aiutarti. Per ulteriori informazioni, consulta Etichettatura dei dati, Preparare e analizzare set di dati, Elaborare i dati e Funzioni di creazione, archiviazione e condivisione.
-
Scegli un algoritmo o un framework: a seconda del livello di personalizzazione necessario, esistono diverse opzioni di algoritmi e framework.
-
Se preferisci un'implementazione low-code di un algoritmo predefinito, utilizza uno degli algoritmi integrati offerti dall'IA. SageMaker Per informazioni su come scegliere un algoritmo, consulta Scelta di un algoritmo.
-
Se hai bisogno di maggiore flessibilità per personalizzare il tuo modello, esegui lo script di formazione utilizzando i framework e i toolkit che preferisci all'interno dell'IA. SageMaker Per ulteriori informazioni, consulta Framework e toolkit di ML.
-
Per portare il tuo contenitore Docker personalizzato nell' SageMaker IA, consulta Adattamento del tuo contenitore Docker personale per lavorare con l'intelligenza artificiale. SageMaker È necessario installare nel proprio container il toolkit sagemaker-training
.
-
-
Gestisci lo storage dei dati: comprendi la mappatura tra lo storage dei dati (ad esempio Amazon S3, Amazon EFS o Amazon FSx) e il contenitore di formazione che viene eseguito nell'istanza di calcolo Amazon EC2. SageMaker L'intelligenza artificiale aiuta a mappare i percorsi di archiviazione e i percorsi locali nel contenitore di formazione. Puoi anche specificarli manualmente. Al termine della mappatura, prendi in considerazione l'utilizzo di una delle modalità di trasmissione dei dati: File, Pipe e FastFile mode. Per scoprire come l' SageMaker IA mappa i percorsi di archiviazione, consulta Training Storage Folders.
-
Configura l'accesso ai dati di formazione: utilizza il dominio Amazon SageMaker AI, un profilo utente di dominio, IAM, Amazon VPC e AWS KMS per soddisfare i requisiti delle organizzazioni più sensibili alla sicurezza.
-
Per l'amministrazione dell'account, consulta il dominio Amazon SageMaker AI.
-
Per un riferimento completo sulle politiche e la sicurezza di IAM, consulta Security in Amazon SageMaker AI.
-
-
Trasmetti in streaming i tuoi dati di input: SageMaker AI fornisce tre modalità di immissione dei dati, File, Pipe e FastFile. La modalità di input predefinita è File, che carica l'intero set di dati durante l'inizializzazione del processo di addestramento. Per conoscere le best practice generali per lo streaming dei dati dal tuo archivio dati al container di addestramento, consulta la sezione Accedere ai dati di addestramento.
Nel caso della modalità Pipe, puoi anche prendere in considerazione l'utilizzo di un file manifest aumentato per lo streaming dei dati direttamente da Amazon Simple Storage Service (Amazon S3) e addestrare il tuo modello. L'uso della modalità pipe riduce lo spazio su disco perché Amazon Elastic Block Store deve solo archiviare gli artefatti del modello finale, anziché archiviare l'intero set di dati di addestramento. Per maggiori informazioni, consulta Fornitura dei metadati dei set di dati ai processi di addestramento con un file manifest aumentato.
-
Analizza i dati per individuare eventuali distorsioni: prima dell'addestramento, puoi analizzare il set di dati e creare un modello per individuare eventuali distorsioni confrontandolo con un gruppo svantaggiato, in modo da verificare che il modello apprenda un set di dati imparziale utilizzando Clarify. SageMaker
-
Scegli quale SageMaker SDK utilizzare: Esistono due modi per avviare un processo di formazione sull' SageMaker intelligenza artificiale: utilizzare l'SDK AI SageMaker Python di alto livello o utilizzare le SageMaker API di basso livello per SDK for Python (Boto3) o il. AWS CLI L'SDK SageMaker Python astrae l' SageMaker API di basso livello per fornire strumenti convenienti. Come accennato in precedenzaL'architettura di base della formazione SageMaker, puoi anche utilizzare opzioni senza codice o con codice minimo utilizzando SageMaker Canvas, Studio Classic o AI Autopilot. JumpStart SageMaker SageMaker
Durante l’addestramento
Durante l’addestramento, è necessario migliorare continuamente la stabilità, la velocità e l'efficienza dell’addestramento, dimensionando al contempo le risorse di elaborazione, l'ottimizzazione dei costi e, soprattutto, le prestazioni dei modelli. Continua a leggere per ulteriori informazioni sulle fasi di allenamento e sulle relative funzionalità di allenamento. SageMaker
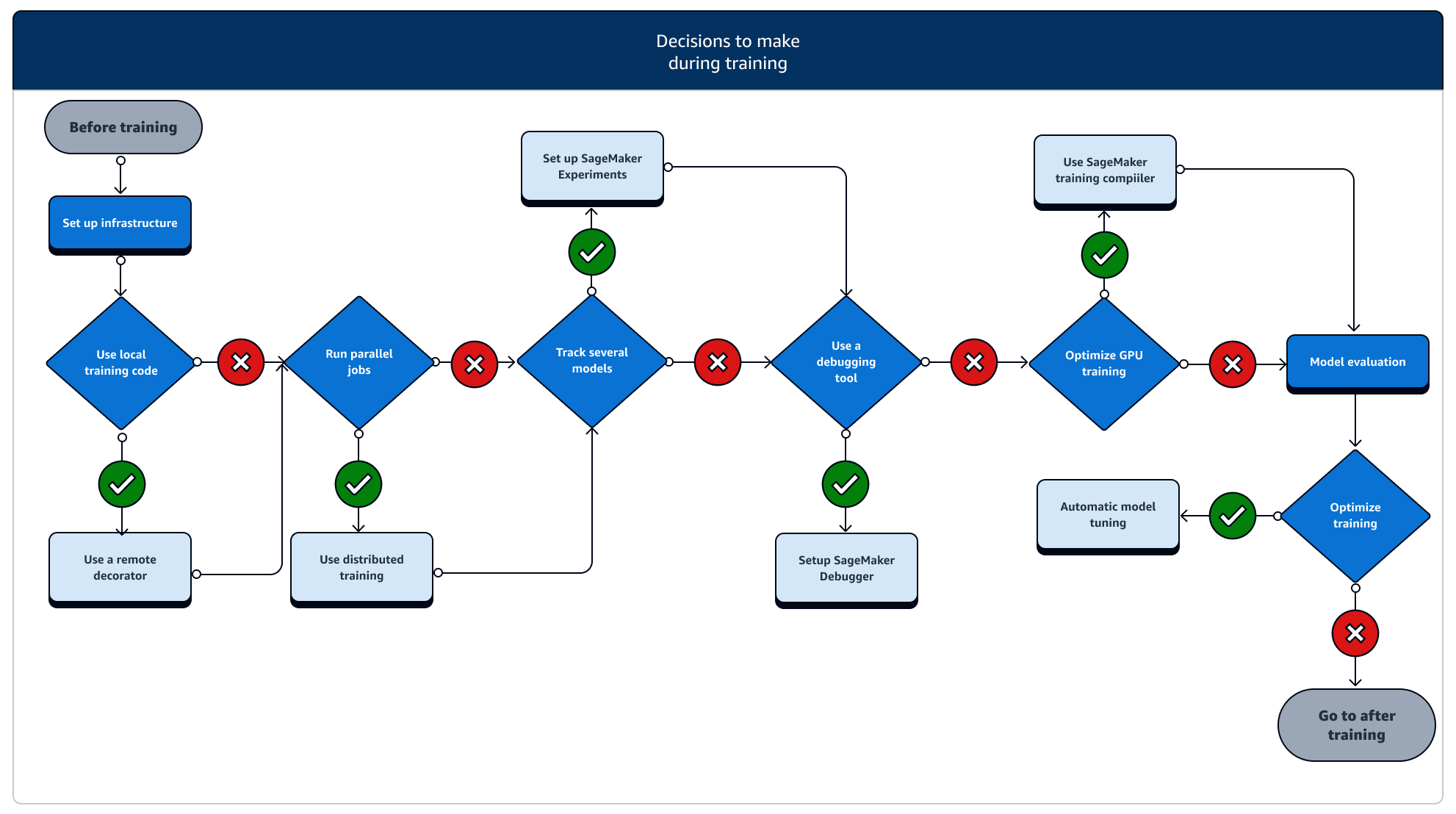
-
Configura l'infrastruttura: scegli il tipo di istanza e gli strumenti di gestione dell'infrastruttura giusti per il tuo caso d'uso. Puoi iniziare da una piccola istanza e aumentarla a seconda del carico di lavoro. Per effettuare l’addestramento di un modello su un set di dati tabulare, inizia con l'istanza CPU più piccola delle famiglie di istanze C4 o C5. Per effettuare l’addestramento di un modello di grandi dimensioni per la visione artificiale o l'elaborazione del linguaggio naturale, inizia con l'istanza GPU più piccola delle famiglie di istanze P2, P3, G4dn o G5. Puoi anche combinare diversi tipi di istanze in un cluster o conservare le istanze in pool caldi utilizzando i seguenti strumenti di gestione delle istanze offerti dall' SageMaker IA. È inoltre possibile utilizzare la cache persistente per ridurre la latenza e il tempo fatturabile dei processi di addestramento rispetto alla sola riduzione della latenza dovuta ai pool caldi. Per ulteriori informazioni, consulta i seguenti argomenti.
Per eseguire un processo di addestramento è necessario disporre di una quota sufficiente. Se esegui il processo di addestramento su un'istanza in cui hai una quota insufficiente, riceverai un messaggio di errore
ResourceLimitExceeded. Per controllare le quote attualmente disponibili nel tuo account, usa la console Service Quotas. Per ulteriori informazioni su come richiedere un aumento delle quote, consulta Regioni e quote supportate. Inoltre, per trovare informazioni sui prezzi e i tipi di istanze disponibili a seconda del Regioni AWS, consulta le tabelle nella pagina SageMaker dei prezzi di Amazon . -
Esegui un processo di formazione da un codice locale: puoi annotare il codice locale con un decoratore remoto per eseguire il codice come processo di SageMaker formazione dall'interno di Amazon SageMaker Studio Classic, un SageMaker notebook Amazon o dal tuo ambiente di sviluppo integrato locale. Per ulteriori informazioni, consulta Esegui il tuo codice locale come processo SageMaker di formazione.
-
Tieni traccia dei lavori di formazione: monitora e monitora i tuoi lavori di formazione utilizzando SageMaker Experiments, SageMaker Debugger o Amazon. CloudWatch Puoi osservare le prestazioni del modello in termini di precisione e convergenza ed eseguire analisi comparative delle metriche tra più lavori di formazione utilizzando AI Experiments. SageMaker Puoi controllare il tasso di utilizzo delle risorse di calcolo utilizzando gli strumenti di profilazione di SageMaker Debugger o Amazon. CloudWatch Per ulteriori informazioni, consulta i seguenti argomenti.
Inoltre, per le attività di deep learning, utilizza gli strumenti di SageMaker debug del modello Amazon Debugger e le regole integrate per identificare problemi più complessi nella convergenza dei modelli e nei processi di aggiornamento del peso.
-
Addestramento distribuito: se il tuo processo di addestramento sta entrando in una fase stabile senza subire interruzioni a causa di una configurazione errata dell'infrastruttura di addestramento o di problemi di memoria esaurita, potresti voler trovare altre opzioni per dimensionare il tuo processo e farlo funzionare per un periodo di tempo prolungato per giorni e persino mesi. Quando sei pronto per la crescita, prendi in considerazione la formazione distribuita. SageMaker L'intelligenza artificiale offre varie opzioni per il calcolo distribuito, dai carichi di lavoro ML leggeri ai carichi di lavoro pesanti di deep learning.
Per le attività di deep learning che prevedono l'addestramento di modelli molto grandi su set di dati molto grandi, prendi in considerazione l'utilizzo di una delle strategie di formazione distribuita dell'SageMaker IA per scalare e ottenere il parallelismo dei dati, il parallelismo dei modelli o una combinazione dei due. Puoi anche utilizzare SageMaker Training Compiler per compilare e ottimizzare i grafici dei modelli su istanze GPU. Queste funzionalità di SageMaker intelligenza artificiale supportano framework di deep learning come PyTorch TensorFlow, e Hugging Face Transformers.
-
Ottimizzazione degli iperparametri dei modelli: ottimizza gli iperparametri del modello utilizzando l'ottimizzazione automatica dei modelli con l'intelligenza artificiale. SageMaker SageMaker L'intelligenza artificiale fornisce metodi di ottimizzazione degli iperparametri come la ricerca a griglia e la ricerca bayesiana, avviando lavori di ottimizzazione parallela degli iperparametri con funzionalità di arresto anticipato per lavori di ottimizzazione degli iperparametri che non migliorano.
-
Controllo e risparmio sui costi con le istanze Spot: se i tempi di addestramento non sono un grosso problema, potresti prendere in considerazione l'ottimizzazione dei costi di addestramento dei modelli con istanze Spot gestite. Tieni presente che devi attivare il checkpoint per l’addestramente su Spot per evitare pause lavorative intermittenti dovute alla sostituzione delle istanze Spot. Puoi anche utilizzare la funzionalità di checkpoint per eseguire il backup dei tuoi modelli in caso di arresto imprevisto del processo di addestramento. Per ulteriori informazioni, consulta i seguenti argomenti.
Dopo l’addestramento
Dopo l’addestramento, si ottiene un artefatto finale del modello da utilizzare per la distribuzione e l'inferenza del modello. Nella fase successiva all’addestramento sono previste ulteriori azioni, come mostrato nel diagramma seguente.
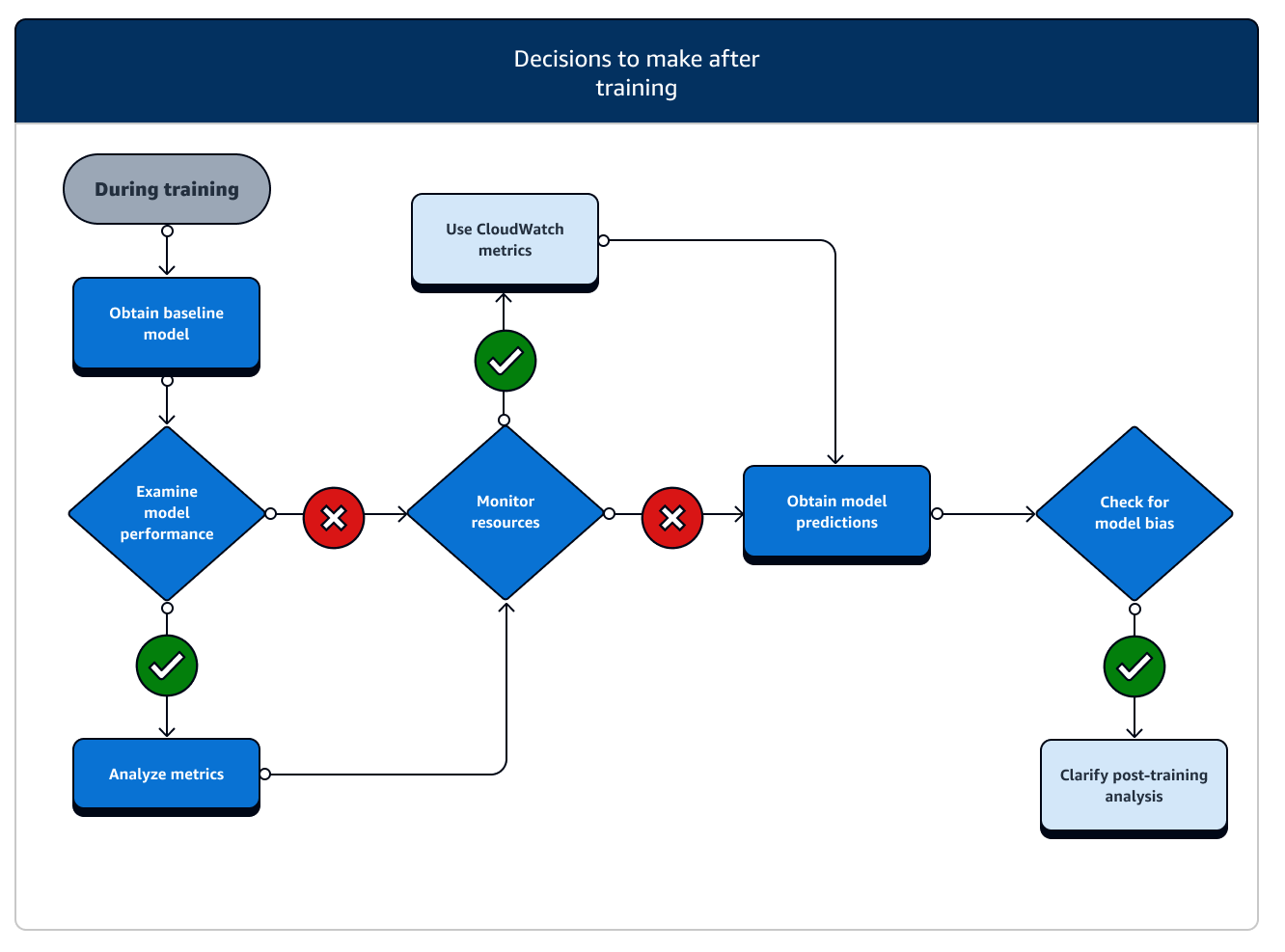
-
Ottieni il modello di base: dopo aver ottenuto l'artefatto del modello, puoi impostarlo come modello di base. Prendi in considerazione le seguenti azioni post-formazione e l'utilizzo delle funzionalità di SageMaker intelligenza artificiale prima di passare alla distribuzione dei modelli alla produzione.
-
Esamina le prestazioni del modello e verifica eventuali distorsioni: utilizza Amazon CloudWatch Metrics e SageMaker Clarify per rilevare eventuali distorsioni nei dati in entrata e modellare nel tempo rispetto alla linea di base. È necessario valutare regolarmente o in tempo reale i nuovi dati e le previsioni del modello rispetto ai nuovi dati. Grazie a queste funzioni, puoi ricevere avvisi su eventuali cambiamenti o anomalie acute, così come su cambiamenti graduali o derive nei dati e nel modello.
-
Puoi anche utilizzare la funzionalità Incremental Training dell' SageMaker IA per caricare e aggiornare il modello (o perfezionarlo) con un set di dati esteso.
-
Puoi registrare la formazione sui modelli come fase della tua SageMaker AI Pipeline o come parte di altre funzionalità di Workflow offerte dall' SageMaker IA per orchestrare l'intero ciclo di vita del machine learning.
