Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
SageMaker Risoluzione dei problemi del Training Compiler
Importante
Amazon Web Services (AWS) annuncia che non ci saranno nuove release o versioni di SageMaker Training Compiler. Puoi continuare a utilizzare SageMaker Training Compiler tramite i AWS Deep Learning Containers (DLC) esistenti per la formazione. SageMaker È importante notare che, sebbene i DLC esistenti rimangano accessibili, non riceveranno più patch o aggiornamenti da AWS, in conformità con la politica di supporto del AWS Deep Learning Containers Framework.
Se si verifica un errore, è possibile utilizzare l'elenco seguente per cercare di risolvere i problemi relativi al processo di addestramento. Se hai bisogno di ulteriore assistenza, contatta il team di SageMaker intelligenza artificiale tramite AWS Support
Il processo di addestramento non converge come previsto rispetto al processo di addestramento del framework nativo
I problemi di convergenza vanno da «il modello non apprende quando SageMaker Training Compiler è acceso» a «il modello sta imparando ma è più lento del framework nativo». In questa guida alla risoluzione dei problemi, supponiamo che la convergenza vada bene senza SageMaker Training Compiler (nel framework nativo) e consideriamo questa la linea di base.
Di fronte a tali problemi di convergenza, la prima fase consiste nell'identificare se il problema è limitato all'addestramento distribuito o deriva dall'addestramento su una singola GPU. La formazione distribuita con SageMaker Training Compiler è un'estensione della formazione su GPU singola con passaggi aggiuntivi.
-
Configurare un cluster con più istanze o GPU.
-
Distribuire i dati di input a tutti i worker.
-
Sincronizzare gli aggiornamenti del modello di tutti i worker.
Pertanto, qualsiasi problema di convergenza nell'addestramento su una singola GPU si ripercuote sull'addestramento distribuito con più worker.
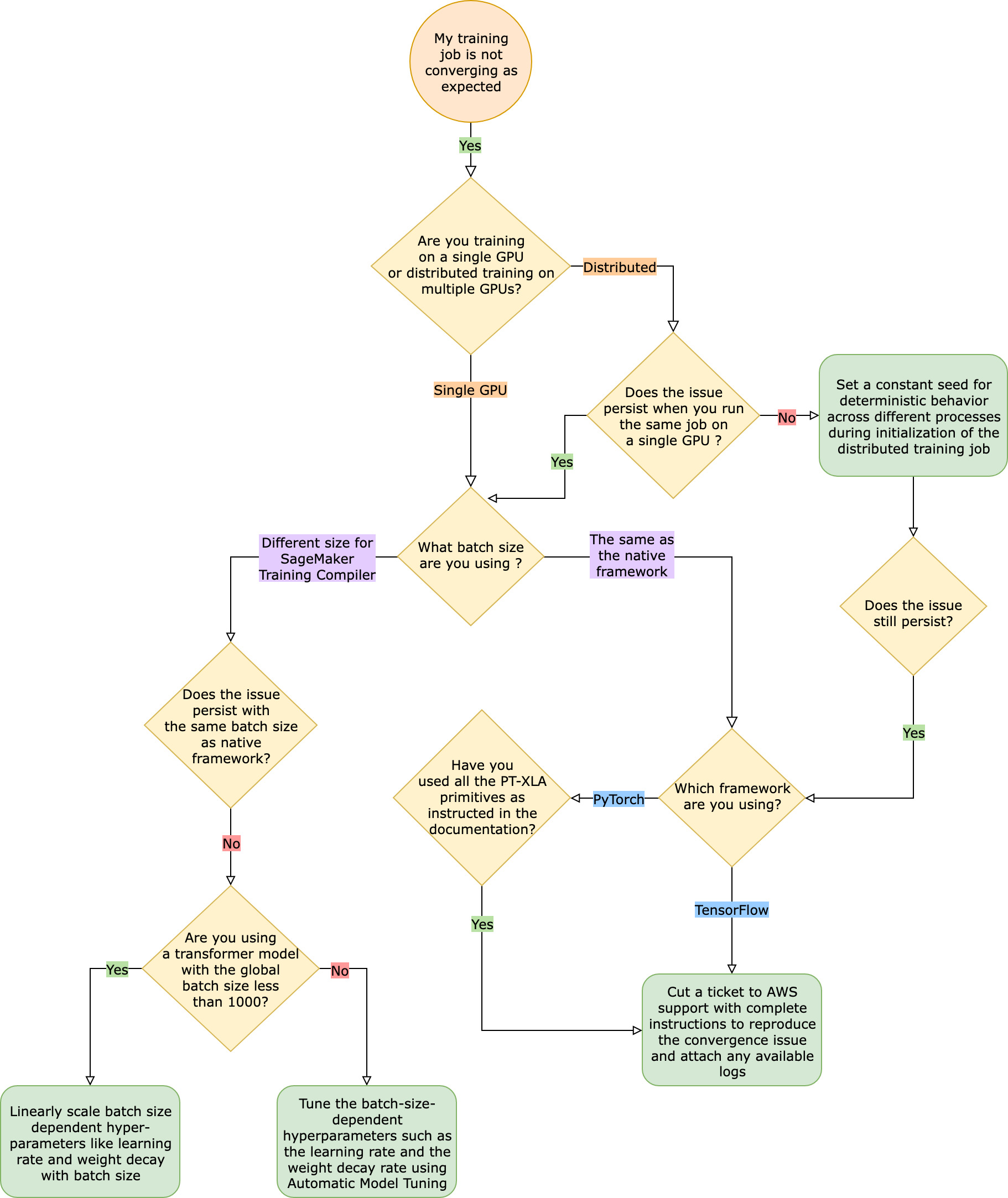
Problemi di convergenza che si verificano nell'addestramento su una singola GPU
Se il problema di convergenza deriva dall'addestramento su una singola GPU, è probabile che ciò sia dovuto a impostazioni errate degli iperparametri o delle API. torch_xla
Controllare gli iperparametri
L'allenamento con SageMaker Training Compiler porta a modificare l'impronta di memoria di un modello. Il compilatore arbitra in modo intelligente tra riutilizzo e ricalcolo, determinando un corrispondente aumento o diminuzione del consumo di memoria. Per sfruttare questo vantaggio, è essenziale ottimizzare nuovamente la dimensione del batch e gli iperparametri associati durante la migrazione di un processo di formazione su Training Compiler. SageMaker Tuttavia, impostazioni errate degli iperparametri spesso causano oscillazioni nella perdita dell'addestramento e, di conseguenza, una convergenza più lenta. In rari casi, gli iperparametri aggressivi possono far sì che il modello non apprenda (la metrica della perdita di addestramento non diminuisce né restituisce NaN) Per identificare se il problema di convergenza è dovuto agli iperparametri, esegui un test fianco a fianco di due lavori di formazione con e senza SageMaker Training Compiler mantenendo tutti gli iperparametri uguali.
Verificare se le API sono configurate correttamente per l'addestramento su una singola GPU torch_xla
Se il problema di convergenza persiste con gli iperparametri di base, è necessario verificare se c'è un uso improprio delle API torch_xla, in particolare di quelle per l'aggiornamento del modello. Fondamentalmente, torch_xla continua ad accumulare istruzioni (posticipando l'esecuzione) sotto forma di grafico fino a quando non gli viene esplicitamente richiesto di eseguire il grafico accumulato. La funzione torch_xla.core.xla_model.mark_step() facilita l'esecuzione del grafico accumulato. L'esecuzione del grafico deve essere sincronizzata utilizzando questa funzione dopo ogni aggiornamento del modello e prima di stampare e registrare qualsiasi variabile . Se manca la fase di sincronizzazione, il modello potrebbe utilizzare valori obsoleti della memoria durante le stampe, i log e i successivi passaggi in avanti, invece di utilizzare i valori più recenti che devono essere sincronizzati dopo ogni iterazione e aggiornamento del modello.
Può essere più complicato quando si utilizza SageMaker Training Compiler con tecniche di ridimensionamento del gradiente (probabilmente grazie all'uso di AMP) o di gradient clipping. L'ordine appropriato per il calcolo del gradiente con AMP è il seguente.
-
Calcolo del gradiente con dimensionamento
-
Annullamento del dimensionamento del gradiente, ritaglio del gradiente e quindi dimensionamento
-
Aggiornamento del modello
-
Sincronizzazione dell'esecuzione del grafico con
mark_step()
Prendere in considerazione l'utilizzo di Automatic Model Tuning
Se il problema di convergenza si verifica quando si ottimizza nuovamente la dimensione del batch e gli iperparametri associati, come la frequenza di apprendimento, durante l'utilizzo di SageMaker Training Compiler, prendi in considerazione l'utilizzo di Automatic Model Tuning per ottimizzare gli iperparametri. Puoi fare riferimento al taccuino di esempio sull'ottimizzazione degli iperparametri con Training Compiler
Problemi di convergenza che si verificano nell'addestramento distribuito
Se il problema di convergenza persiste nell'addestramento distribuito, è probabilmente dovuto a impostazioni errate per l'inizializzazione del peso o le API torch_xla.
Controllare l'inizializzazione del peso tra i worker
Se si verifica un problema di convergenza quando si svolge un processo di addestramento distribuito con più worker, assicurarsi che vi sia un comportamento deterministico uniforme tra tutti i worker stabilendo un ritmo costante, ove applicabile. Fare attenzione a tecniche come l'inizializzazione del peso, che prevede la randomizzazione. Ogni worker potrebbe finire per addestrare un modello diverso in assenza di un seme costante.
Verificare se le API torch_xla sono configurate correttamente per l'addestramento su una singola GPU
Se il problema persiste, è probabile che ciò sia dovuto all'uso improprio delle API torch_xla per l'addestramento distribuito. Assicurati di aggiungere quanto segue nel tuo estimatore per configurare un cluster per la formazione distribuita con Training Compiler. SageMaker
distribution={'torchxla': {'enabled': True}}
Questo dovrebbe essere accompagnato da una funzione _mp_fn(index) nello script di addestramento, che viene richiamata una volta per worker. Senza la funzione mp_fn(index), si potrebbe finire per consentire a ciascuno dei worker di addestrare il modello in modo indipendente senza condividere gli aggiornamenti del modello.
Successivamente, assicurati di utilizzare l'torch_xla.distributed.parallel_loader.MpDeviceLoaderAPI insieme al campionatore di dati distribuiti, come indicato nella documentazione sulla migrazione dello script di formazione a SageMaker Training Compiler, come nell'esempio seguente.
torch.utils.data.distributed.DistributedSampler()
Ciò garantisce che i dati di input siano distribuiti correttamente tra tutti i worker.
Infine, per sincronizzare gli aggiornamenti dei modelli di tutti i worker, utilizzare torch_xla.core.xla_model._fetch_gradients per raccogliere i gradienti di tutti i worker e torch_xla.core.xla_model.all_reduce per combinare tutti i gradienti raccolti in un unico aggiornamento.
Può essere più complicato quando si utilizza SageMaker Training Compiler con tecniche di ridimensionamento del gradiente (probabilmente grazie all'uso di AMP) o di gradient clipping. L'ordine appropriato per il calcolo del gradiente con AMP è il seguente.
-
Calcolo del gradiente con dimensionamento
-
Sincronizzazione del gradiente tra tutti i worker
-
Annullamento del dimensionamento del gradiente, ritaglio del gradiente e quindi dimensionamento
-
Aggiornamento del modello
-
Sincronizzazione dell'esecuzione del grafico con
mark_step()
Notare che questa lista di controllo contiene un elemento aggiuntivo per la sincronizzazione di tutti i worker, rispetto alla lista di controllo per l'addestramento su una singola GPU.
Il processo PyTorch/XLA di formazione non riesce a causa di una configurazione mancante
Se un processo di addestramento fallisce con il messaggio di errore Missing XLA configuration, ciò potrebbe essere dovuto a un'errata configurazione del numero di GPU per istanza utilizzate.
XLA richiede variabili di ambiente aggiuntive per compilare il processo di addestramento. La variabile di ambiente mancante più comune è GPU_NUM_DEVICES. Affinché il compilatore funzioni correttamente, è necessario impostare questa variabile di ambiente uguale al numero di GPU per istanza.
Esistono tre approcci per impostare la variabile di ambiente GPU_NUM_DEVICES:
-
Approccio 1 — Usa l'
environmentargomento della classe SageMaker AI estimator. Ad esempio, se si utilizza un'istanzaml.p3.8xlargecon quattro GPU, procedere come segue:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... instance_type="ml.p3.8xlarge", hyperparameters={...}, environment={ ... "GPU_NUM_DEVICES": "4" # corresponds to number of GPUs on the specified instance }, ) -
Approccio 2: utilizza l'
hyperparametersargomento della classe SageMaker AI estimator e analizzalo nel tuo script di addestramento.-
Per specificare il numero di GPU, aggiungere una coppia chiave-valore all'argomento.
hyperparametersAd esempio, se si utilizza un'istanza
ml.p3.8xlargecon quattro GPU, procedere come segue:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... entry_point = "train.py" instance_type= "ml.p3.8xlarge", hyperparameters = { ... "n_gpus":4# corresponds to number of GPUs on specified instance } ) hf_estimator.fit() -
Nello script di addestramento, analizzare l'iperparametro
n_gpuse specificarlo come input per la variabile di ambienteGPU_NUM_DEVICES.# train.py import os, argparse if __name__ == "__main__": parser = argparse.ArgumentParser() ... # Data, model, and output directories parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"]) parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"]) parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"]) parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"]) parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"]) args, _ = parser.parse_known_args() os.environ["GPU_NUM_DEVICES"] = args.n_gpus
-
-
Approccio 3: Hard-code la variabile di
GPU_NUM_DEVICESambiente nello script di allenamento. Ad esempio, se si utilizza un'istanza con quattro GPU, aggiungere quanto segue allo script.# train.py import os os.environ["GPU_NUM_DEVICES"] =4
Suggerimento
Per trovare il numero di dispositivi GPU su istanze di machine learning che si desideri utilizzare, consultare Accelerated Computing
SageMaker Training Compiler non riduce il tempo totale di allenamento
Se il tempo totale di allenamento non diminuisce con SageMaker Training Compiler, ti consigliamo vivamente di consultare la SageMaker Buone pratiche e considerazioni su Training Compiler pagina per controllare la configurazione di allenamento, la strategia di riempimento per la forma del tensore di input e gli iperparametri.
