Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di un modello linguistico personalizzato
Prima di poter creare il tuo modello linguistico personalizzato, devi:
-
Preparare i tuoi dati. I dati devono essere salvati in formato di testo semplice e non possono contenere caratteri speciali.
-
Carica i tuoi dati in un Amazon S3 bucket. Si consiglia di creare cartelle separate per i dati di addestramento e di ottimizzazione.
-
Assicurati di Amazon Transcribe avere accesso al tuo Amazon S3 bucket. Devi specificare un IAM ruolo con autorizzazioni di accesso per utilizzare i tuoi dati.
Preparazione dei dati
Puoi compilare tutti i tuoi dati in un unico file o salvarli in più file. Tieni presente che se scegli di includere i dati di ottimizzazione, questi devono essere salvati in un file separato dai dati di addestramento.
Non importa quanti file di testo utilizzi per i dati di addestramento o di ottimizzazione. Il caricamento di un file con 100.000 parole produce lo stesso risultato del caricamento di 10 file con 10.000 parole. Prepara i dati di testo nel modo più comodo per te.
Accertati che tutti i tuoi file di dati soddisfino i seguenti criteri:
-
Sono tutti nella stessa lingua del modello che desideri creare. Ad esempio, se desideri creare un modello linguistico personalizzato che trascriva l'audio in inglese americano (
en-US), tutti i dati di testo devono essere in inglese americano. -
Sono in formato di testo semplice con UTF-8 codifica.
-
Non contengono caratteri o formattazioni speciali, come i tag HTML.
-
Ammontano a un totale massimo di 2 GB per i dati di addestramento e 200 MB per i dati di ottimizzazione.
Se uno di questi criteri non viene soddisfatto, il modello non funziona.
Caricamento dei dati
Prima di caricare i dati, crea una nuova cartella per i dati di addestramento. Se utilizzi i dati di ottimizzazione, crea un'altra cartella separata.
Gli URI per i tuoi bucket potrebbero essere simili a:
-
s3://amzn-s3-demo-bucket/my-model-training-data/ -
s3://amzn-s3-demo-bucket/my-model-tuning-data/
Carica i dati di addestramento e ottimizzazione nei bucket appropriati.
Puoi aggiungere altri dati a questi bucket in un secondo momento. Tuttavia, in tal caso, è necessario ricreare il modello con i nuovi dati. I modelli esistenti non possono essere aggiornati con nuovi dati.
Consentire l'accesso ai dati
Per creare un modello linguistico personalizzato, devi specificare un IAM ruolo con le autorizzazioni per accedere al tuo Amazon S3 bucket. Se non disponi già di un ruolo con accesso al Amazon S3 bucket in cui hai inserito i dati di allenamento, devi crearne uno. Dopo aver creato un ruolo, puoi allegare una policy per concedere le autorizzazioni a quel ruolo. Non collegare una policy a un utente.
Per esempi di policy, consulta Amazon Transcribe esempi di politiche basate sull'identità.
Per informazioni su come creare una nuova IAM identità, consulta IAM Identità (utenti, gruppi di utenti e ruoli).
Per ulteriori informazioni sulle policy, consulta:
Creazione del modello linguistico personalizzato
Quando crei il tuo modello linguistico personalizzato, devi scegliere un modello base. Sono disponibili due opzioni del modello base:
-
NarrowBand: utilizza questa opzione per l'audio con una frequenza di campionamento inferiore a 16.000 Hz. Questo tipo di modello viene in genere utilizzato per conversazioni telefoniche registrate a 8.000 Hz. -
WideBand: utilizza questa opzione per l'audio con una frequenza di campionamento maggiore o uguale a 16.000 Hz.
Puoi creare modelli linguistici personalizzati utilizzando Console di gestione AWS AWS CLI, o AWS SDK. Vedi i seguenti esempi:
-
Accedi alla Console di gestione AWS
. -
Nel pannello di navigazione, scegli Modello linguistico personalizzato. Si aprirà la pagina Modelli linguistici personalizzati in cui è possibile visualizzare i modelli linguistici personalizzati esistenti o addestrare un nuovo modello linguistico personalizzato.
-
Per addestrare un nuovo modello, seleziona Modello di addestramento.
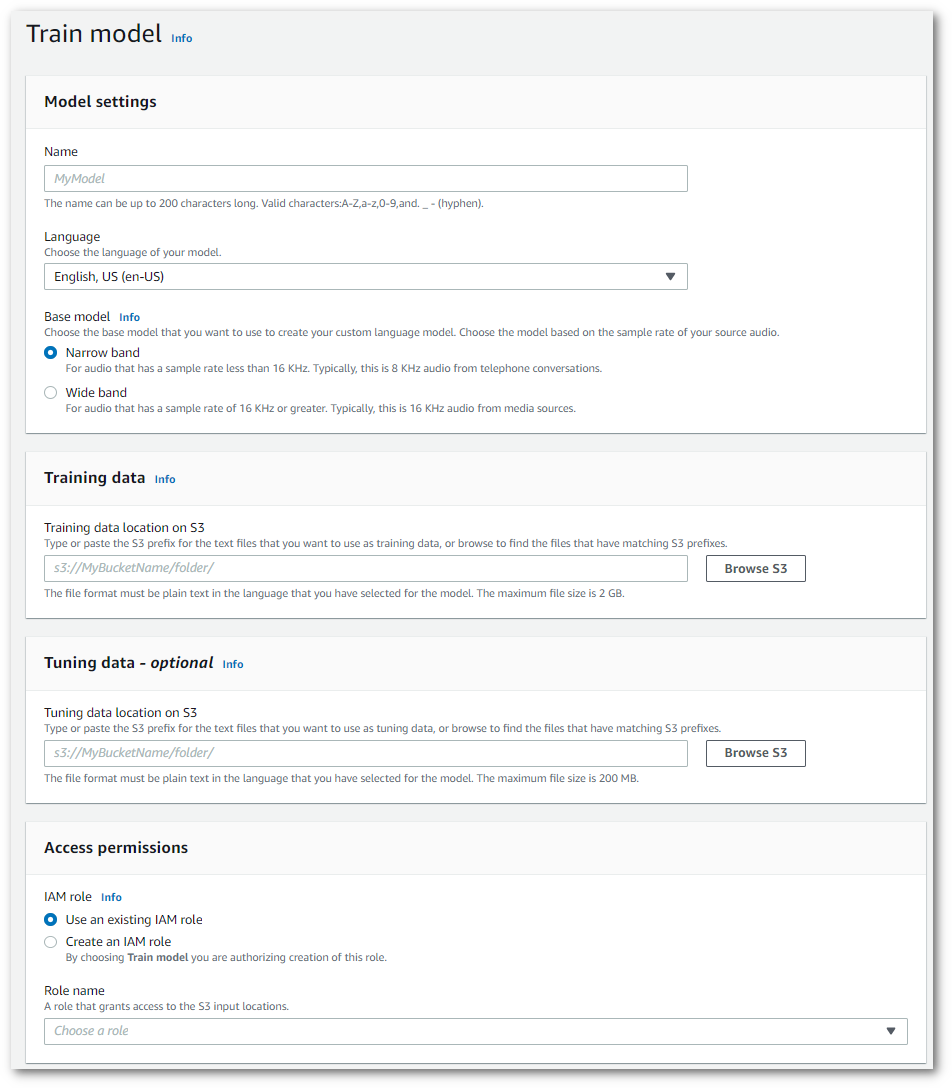
In questo modo si accede alla pagina del Modello di addestramento. Aggiungi un nome, specifica la lingua e scegli il modello base che desideri per il tuo modello. Quindi, aggiungi il percorso ai dati di addestramento e, facoltativamente, a quelli di ottimizzazione. Devi includere un IAM ruolo che disponga delle autorizzazioni per accedere ai tuoi dati.
-
Una volta completati tutti i campi, seleziona Modello di addestramento nella parte inferiore della pagina.
Questo esempio utilizza il comando crea modello linguisticoCreateLanguageModel e LanguageModel.
aws transcribe create-language-model \ --base-model-nameNarrowBand\ --model-namemy-first-language-model\ --input-data-config S3Uri=s3://amzn-s3-demo-bucket/my-clm-training-data/,TuningDataS3Uri=s3://amzn-s3-demo-bucket/my-clm-tuning-data/,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole\ --language-codeen-US
Ecco un altro esempio che utilizza il comando crea modello linguistico
aws transcribe create-language-model \ --cli-input-json file://filepath/my-first-language-model.json
Il file my-first-language-model.json contiene il seguente corpo della richiesta.
{ "BaseModelName": "NarrowBand", "ModelName": "my-first-language-model", "InputDataConfig": { "S3Uri": "s3://amzn-s3-demo-bucket/my-clm-training-data/", "TuningDataS3Uri"="s3://amzn-s3-demo-bucket/my-clm-tuning-data/", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" }, "LanguageCode": "en-US" }
Questo esempio utilizza AWS SDK per Python (Boto3) per creare un CLM utilizzando il metodo create_language_model.CreateLanguageModel e LanguageModel.
Per ulteriori esempi di utilizzo degli AWS SDK, inclusi esempi relativi a funzionalità specifiche, scenari e cross-service, consultate il capitolo. Esempi di codice per l'utilizzo di Amazon Transcribe AWS SDK
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') model_name = 'my-first-language-model', transcribe.create_language_model( LanguageCode = 'en-US', BaseModelName = 'NarrowBand', ModelName = model_name, InputDataConfig = { 'S3Uri':'s3://amzn-s3-demo-bucket/my-clm-training-data/', 'TuningDataS3Uri':'s3://amzn-s3-demo-bucket/my-clm-tuning-data/', 'DataAccessRoleArn':'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_language_model(ModelName = model_name) if status['LanguageModel']['ModelStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Aggiornamento del modello linguistico personalizzato
Amazon Transcribe aggiorna continuamente i modelli di base disponibili per i modelli linguistici personalizzati. Per trarre vantaggio da questi aggiornamenti, consigliamo di addestrare nuovi modelli linguistici personalizzati ogni 6-12 mesi.
Per verificare se il tuo modello linguistico personalizzato utilizza il modello di base più recente, esegui una DescribeLanguageModelrichiesta utilizzando il AWS CLI o un AWS SDK, quindi individua il UpgradeAvailability campo nella risposta.
In caso UpgradeAvailability sia true, sul modello non è in esecuzione la versione più recente del modello base. Per utilizzare il modello base più recente in un modello linguistico personalizzato, è necessario creare un nuovo modello linguistico personalizzato. I modelli linguistici personalizzati non possono essere aggiornati.
