Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Guasti grigi
I guasti grigi sono definiti dalla caratteristica diosservabilità differenziale
Osservabilità differenziale
I carichi di lavoro che gestisci in genere hanno delle dipendenze. Ad esempio, questi possono essereAWSservizi cloud che usi per creare il tuo carico di lavoro o un provider di identità (IdP) di terze parti che usi per la federazione. Queste dipendenze implementano quasi sempre la propria osservabilità, registrando metriche su errori, disponibilità e latenza, tra le altre cose generate dall'utilizzo dei clienti. Quando viene superata una soglia per una di queste metriche, la dipendenza di solito interviene per correggerla.
Queste dipendenze di solito hanno più utenti dei loro servizi. I consumatori implementano anche la propria osservabilità e registrano metriche e registri sulle loro interazioni con le loro dipendenze, registrando elementi come la latenza presente nelle letture su disco, il numero di richieste API non riuscite o il tempo impiegato per una query sul database.
Queste interazioni e misurazioni sono illustrate in un modello astratto nella figura seguente.
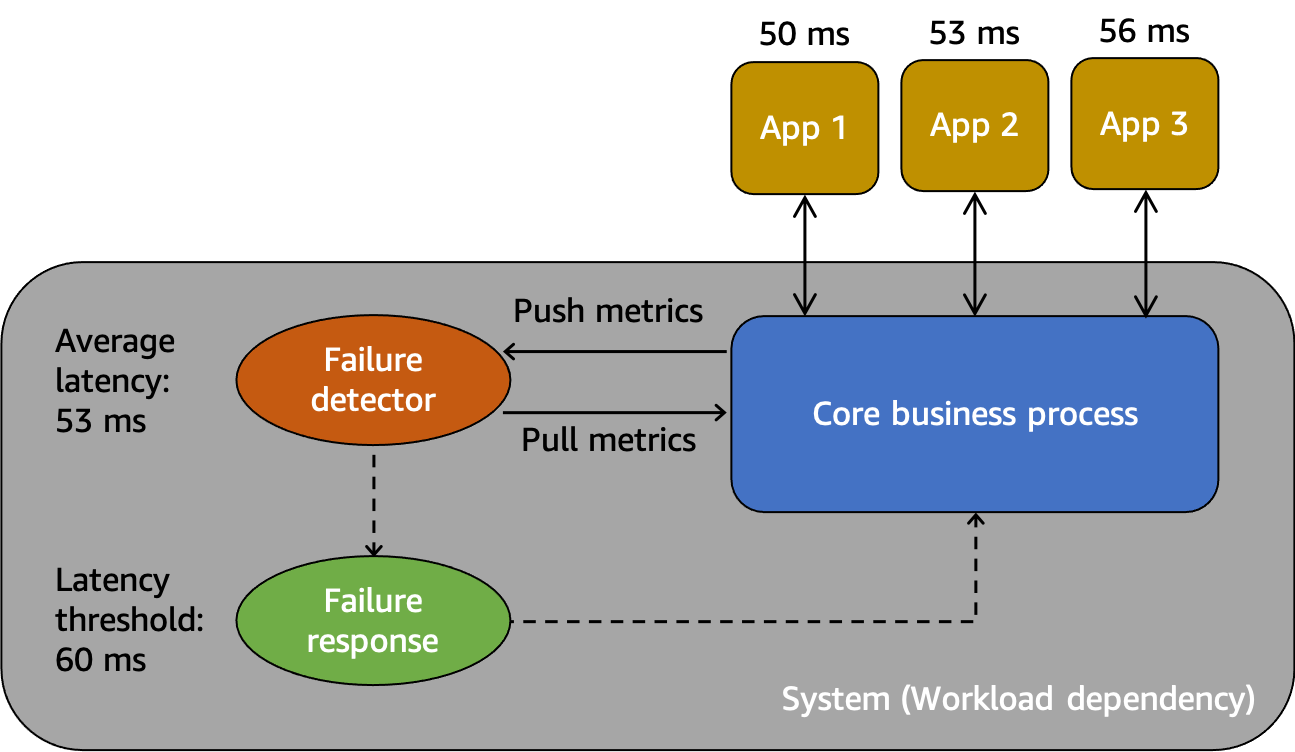
Un modello astratto per comprendere i fallimenti grigi
Innanzitutto, abbiamosistema, che in questo scenario è una dipendenza per i consumatori App 1, App 2 e App 3. Il sistema è dotato di un rilevatore di guasti che esamina le metriche create dal processo aziendale principale. Dispone inoltre di un meccanismo di risposta ai guasti per mitigare o correggere i problemi osservati dal rilevatore di guasti. Il sistema registra una latenza media complessiva di 53 ms e ha impostato una soglia per richiamare il meccanismo di risposta ai guasti quando la latenza media supera i 60 ms. Anche l'App 1, l'App 2 e l'App 3 stanno facendo le proprie osservazioni sulla loro interazione con il sistema, registrando una latenza media rispettivamente di 50 ms, 53 ms e 56 ms.
L'osservabilità differenziale è la situazione in cui uno degli utenti del sistema rileva che il sistema non è sano, ma il monitoraggio del sistema non rileva il problema o l'impatto non supera una soglia di allarme. Immaginiamo che App 1 inizi a registrare una latenza media di 70 ms anziché 50 ms. L'App 2 e l'App 3 non registrano alcuna variazione nelle loro latenze medie. Ciò aumenta la latenza media del sistema sottostante a 59,66 ms, ma non supera la soglia di latenza per attivare il meccanismo di risposta ai guasti. Tuttavia, l'App 1 registra un aumento del 40% della latenza. Ciò potrebbe influire sulla sua disponibilità superando il timeout del client configurato per l'App 1, oppure potrebbe causare impatti a cascata in una catena di interazioni più lunga. Dal punto di vista dell'App 1, il sistema sottostante da cui dipende non è sano, ma dal punto di vista del sistema stesso, anche dell'App 2 e dell'App 3, il sistema è integro. La figura seguente riassume queste diverse prospettive.
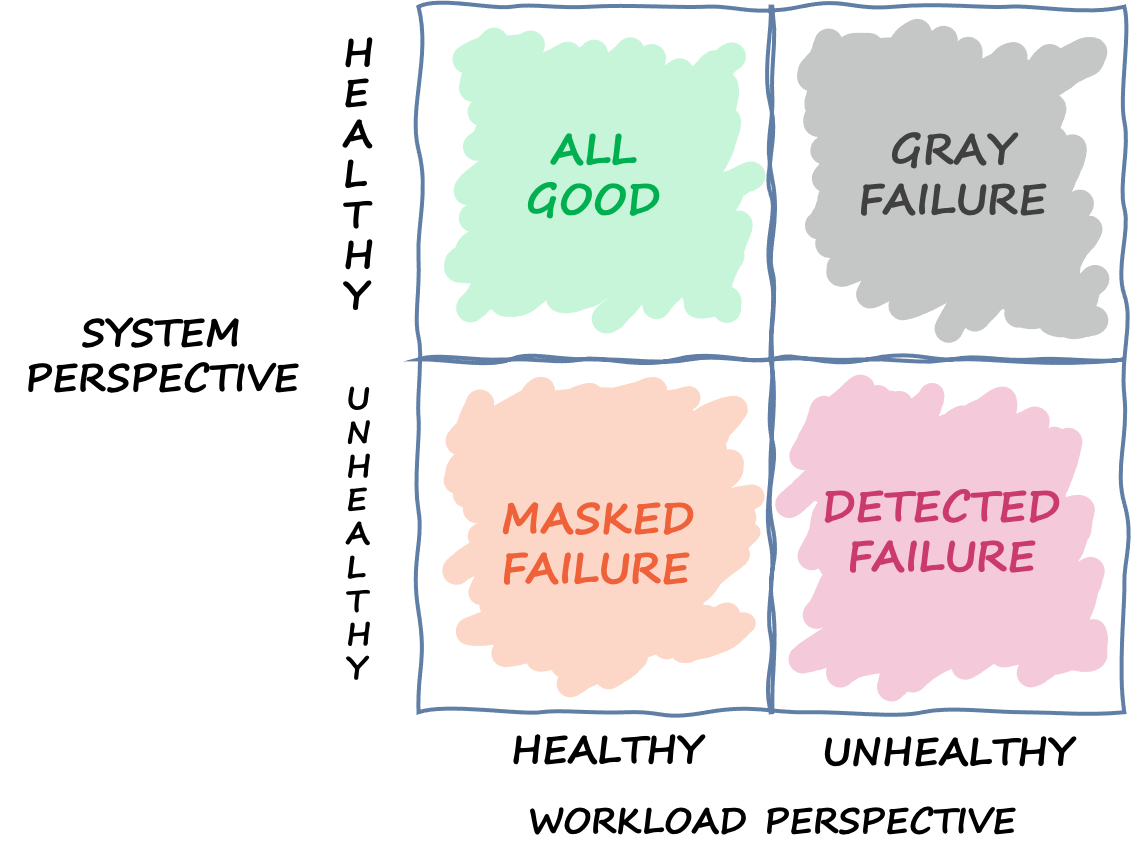
Un quadrante che definisce i diversi stati in cui può trovarsi un sistema in base a diverse prospettive
L'errore può anche attraversare questo quadrante. Un evento può iniziare come un errore grigio, quindi diventare un errore rilevato, quindi passare a un errore mascherato e quindi forse tornare a un errore grigio. Non esiste un ciclo definito e c'è quasi sempre la possibilità che il fallimento si ripresenti finché non ne viene risolta la causa principale.
La conclusione che ne traiamo è che i carichi di lavoro non possono sempre fare affidamento sul sistema sottostante per rilevare e mitigare l'errore. Non importa quanto sia sofisticato e resistente il sistema sottostante, ci sarà sempre la possibilità che un guasto possa passare inosservato o rimanere al di sotto della soglia di reazione. Gli utenti di quel sistema, come App 1, devono essere attrezzati per rilevare e mitigare rapidamente l'impatto causato da un guasto grigio. Ciò richiede la creazione di meccanismi di osservabilità e recupero per queste situazioni.
Esempio di guasto grigio
I guasti grigi possono avere un impatto sui sistemi Multi-AZ inAWS. Prendiamo ad esempio una flotta diAmazon EC2
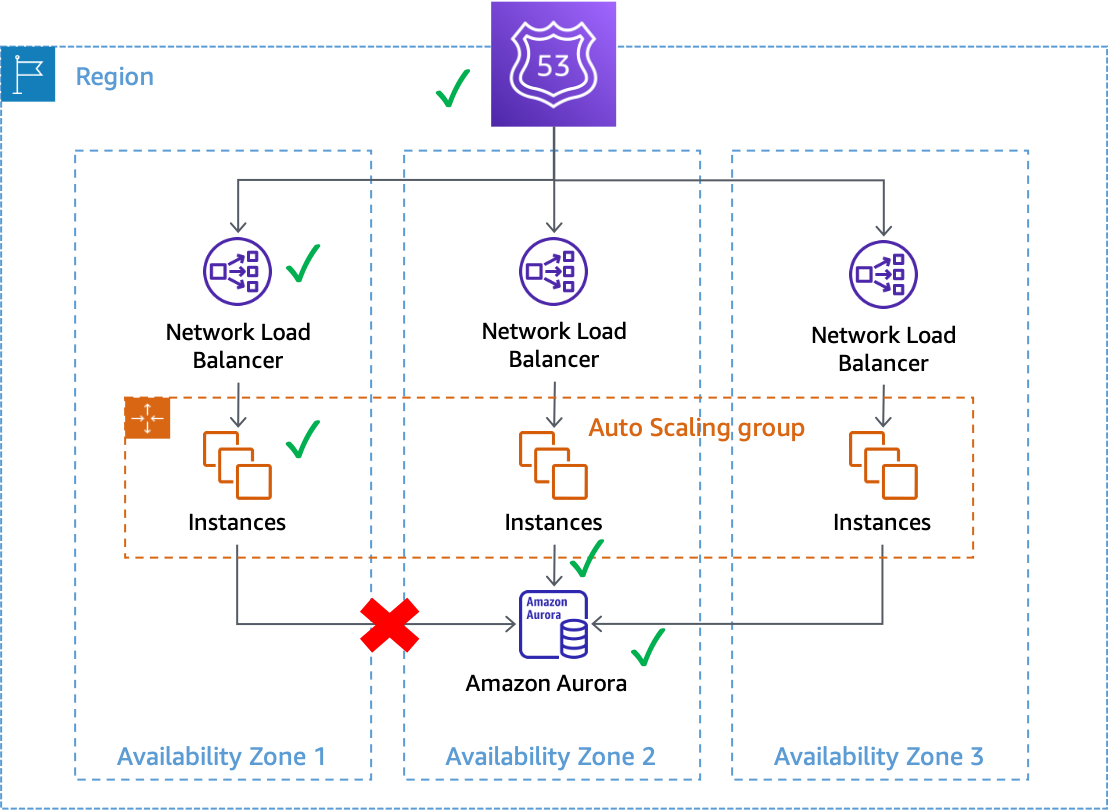
Un errore grigio che influisce sulle connessioni al database dalle istanze nella zona di disponibilità 1
In questo esempio, Amazon EC2 ritiene che le istanze nella zona di disponibilità 1 siano integre perché continuano a passarecontrolli dello stato del sistema e dell'istanza. Inoltre, Amazon EC2 Auto Scaling non rileva l'impatto diretto su alcuna zona di disponibilità e continua acapacità di avvio nelle zone di disponibilità configurate. Il Network Load Balancer (NLB) ritiene inoltre che le istanze che lo supportano siano integre, così come i controlli di integrità della Route 53 eseguiti sull'endpoint NLB. Analogamente, Amazon Relational Database Service (Amazon RDS) considera il cluster di database integro e non lo faattivare un failover automatico. Abbiamo molti servizi diversi che considerano tutti buoni i propri servizi e le proprie risorse, ma il carico di lavoro rileva un guasto che ne influisce sulla disponibilità. Questo è un grigio fallimento.
Risposta ai guasti grigi
Quando riscontri un errore grigio nel tuoAWSambiente, in genere sono disponibili tre opzioni:
-
Non fate nulla e aspettate che la menomazione finisca.
-
Se il danno è isolato in un'unica zona di disponibilità, evacuare quella zona di disponibilità.
-
Failover su un altroRegione AWSe sfrutta i vantaggi diAWSIsolamento regionale per mitigare l'impatto.
MoltiAWSi clienti sono soddisfatti della prima opzione per la maggior parte dei loro carichi di lavoro. Accettano di avere un'eventuale prorogaObiettivo del tempo di ripristino (RTO)con il compromesso di non aver dovuto creare soluzioni aggiuntive di osservabilità o resilienza. Altri clienti scelgono di implementare la terza opzione,Disaster Recovery multiregionale
Innanzitutto, la creazione e la gestione di un'architettura multiregionale può essere un'impresa impegnativa, complessa e potenzialmente costosa. Le architetture multiregionali richiedono un'attenta considerazione di qualiStrategia DRtu selezioni. Potrebbe non essere fiscalmente fattibile implementare una soluzione di ripristino di emergenza attiva in più regioni solo per gestire le disfunzioni zonali, mentre una strategia di backup e ripristino potrebbe non soddisfare i requisiti di resilienza. Inoltre, i failover multiregionali devono essere continuamente utilizzati in fase di produzione, in modo da essere certi che funzioneranno quando necessario. Tutto ciò richiede molto tempo e risorse dedicati per costruire, utilizzare e testare.
In secondo luogo, la replica dei dati suRegioni AWSutilizzandoAWSi servizi oggi vengono eseguiti tutti in modo asincrono. La replica asincrona può causare la perdita di dati. Ciò significa che durante un failover regionale, è possibile che si verifichino perdite e incongruenze di dati. La tua tolleranza alla quantità di perdita di dati è definita comeObiettivo del punto di ripristino (RPO). I clienti, per i quali è richiesta una forte coerenza dei dati, devono creare sistemi di riconciliazione per risolvere questi problemi di coerenza quando la regione principale sarà nuovamente disponibile. In alternativa, devono creare i propri sistemi di replica sincrona o a doppia scrittura, che possono avere un impatto significativo sulla latenza, sui costi e sulla complessità della risposta. Inoltre, rendono la regione secondaria una forte dipendenza per ogni transazione, il che può potenzialmente ridurre la disponibilità dell'intero sistema.
Infine, per molti carichi di lavoro che utilizzano un approccio attivo/standby, è necessario un periodo di tempo diverso da zero per eseguire il failover in un'altra regione. Potrebbe essere necessario ridurre il tuo portafoglio di carichi di lavoro nella regione principale in un ordine specifico, svuotare le connessioni o interrompere processi specifici. Quindi, potrebbe essere necessario ripristinare i servizi in un ordine specifico. Potrebbe anche essere necessario fornire nuove risorse o richiedere tempo per superare i controlli sanitari richiesti prima di essere messe in servizio. Questo processo di failover può essere vissuto come un periodo di completa indisponibilità. Questo è ciò di cui si occupano gli RTO.
All'interno di una regione, moltiAWSi servizi offrono una persistenza dei dati fortemente coerente. Utilizzo delle implementazioni Amazon RDS Multi-AZreplica sincrona. Servizio Amazon Simple Storage
L'evacuazione di una zona di disponibilità può comportare un RTO inferiore rispetto a una strategia multiregionale, poiché l'infrastruttura e le risorse sono già distribuite tra zone di disponibilità. Invece di dover ordinare con attenzione la disattivazione e il backup dei servizi o di esaurire le connessioni, le architetture Multi-AZ possono continuare a funzionare in modo statico quando una zona di disponibilità è compromessa. Invece di un periodo di completa indisponibilità che può verificarsi durante un failover regionale, durante l'evacuazione di una zona di disponibilità, molti sistemi potrebbero subire solo un leggero degrado, poiché il lavoro viene spostato nelle zone di disponibilità rimanenti. Se il sistema è stato progettato perstaticamente stabile
È possibile che la riduzione di una singola zona di disponibilità influenzi una o piùAWS Servizi regionalioltre al tuo carico di lavoro. Se osservi un impatto regionale, dovresti considerare l'evento come un problema del servizio regionale, sebbene l'origine di tale impatto provenga da un'unica zona di disponibilità. L'evacuazione di una zona di disponibilità non mitigherà questo tipo di problema. Utilizza i piani di risposta che hai a disposizione per rispondere a un'interruzione del servizio regionale quando ciò si verifica.
Il resto di questo documento si concentra sulla seconda opzione, l'evacuazione della zona di disponibilità, come metodo per ottenere RTO e RPO inferiori in caso di guasti grigi Single-AZ. Questi modelli possono contribuire a migliorare il valore e l'efficienza delle architetture Multi-AZ e, per la maggior parte delle classi di carichi di lavoro, possono ridurre la necessità di creare architetture multiregionali per gestire questi tipi di eventi.
