翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Valkey クラスターと Redis OSS クラスターの自動スケーリング
前提条件
ElastiCache の自動スケーリングは、以下に制限されています。
-
Valkey 7.2 以降または Redis OSS 6.0 以降を実行している、Valkey または Redis OSS (クラスターモードが有効) クラスター
-
Valkey 7.2 以降または Redis OSS 7.0.7 以降を実行している、データ階層化 (クラスターモードが有効) クラスター
-
インスタンスサイズ - Large、XLarge、2XLarge
-
インスタンスタイプファミリー – R7g、R6g、R6gd、R5、M7g、M6g、M5、C7gn
-
ElastiCache の自動スケーリングは、グローバルデータストア、Outposts、または Local Zones で実行しているクラスターではサポートされません。
Valkey または Redis OSS 対応 ElastiCache の自動スケーリングを用いた容量の自動管理
Valkey または Redis OSS 対応 ElastiCache の自動スケーリングは、ElastiCache サービスで必要なシャードまたはレプリカを自動的に増減する機能です。ElastiCache は Application Auto Scaling サービスを活用してこの機能を提供します。詳細については、Application Auto Scaling を参照してください。自動スケーリングを使用するには、割り当てた CloudWatch メトリクスとターゲット値を使用するスケーリングポリシーを定義して適用します。ElastiCache の自動スケーリングでは、ポリシーを使用し、実際のワークロードに応じてインスタンス数を増減します。
を使用して、事前定義されたメトリクスに基づいてスケーリングポリシー AWS マネジメントコンソール を適用できます。predefined metric は列挙型で定義されるため、それをコード内に名前で指定するか、 AWS マネジメントコンソールで使用できます。カスタムのメトリクスは、 AWS マネジメントコンソールを使用した選択には使用できません。または、 AWS CLI または Application Auto Scaling API を使用して、事前定義されたメトリクスまたはカスタムメトリクスに基づいてスケーリングポリシーを適用することもできます。
ElastiCache for Valkey と ElastiCache for Redis OSS は、次のディメンションのスケーリングをサポートします。
-
[シャード] — 手動オンラインリシャーディングと同様に、クラスター内のシャードを自動的に追加/削除します。この場合、ElastiCache の自動スケーリングはユーザーに代わってスケーリングをトリガーします。
-
[レプリカ] – 手動によるレプリカの増加/減少オペレーションと同様に、クラスター内のレプリカを自動的に追加/削除します。ElastiCache for Valkey と ElastiCache for Redis OSS の 自動スケーリングは、クラスター内のすべてのシャードにわたって均一にレプリカを追加/削除します。
ElastiCache for Valkey と ElastiCache for Redis OSS は、次のタイプの自動スケーリングポリシーをサポートします。
-
ターゲット追跡スケーリングポリシー – 特定のメトリクスのターゲット値に基づいて、サービスが実行するシャード/レプリカの数を増減させます。これはサーモスタットが家の温度を維持する方法に似ています。温度を選択すれば、後はサーモスタットがすべてを実行します。
-
アプリケーションのスケジュールされたスケーリング。 – ElastiCache for Valkey と ElastiCache for Redis OSS の自動スケーリングでは、日付と時刻に基づいて、サービスが実行するシャード/レプリカの数を増減させることができます。
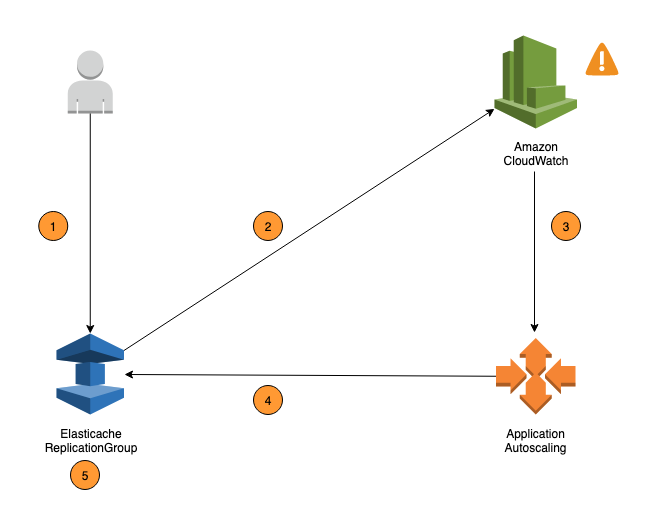
次のステップは、前の図に示された ElastiCache for Valkey と ElastiCache for Redis OSS の自動スケーリングのプロセスをまとめたものです。
-
レプリケーショングループ用の ElastiCache の Auto Scaling ポリシーを作成します。
-
ElastiCache の自動スケーリングは、ユーザーに代わって CloudWatch アラームのペアを作成します。各ペアはメトリクスの上限と下限を示します。CloudWatch アラームは、クラスターの実際の使用率が一定期間ターゲット使用率を逸脱したときにトリガーされます。コンソールでアラームを表示できます。
-
設定したメトリクスの値が特定の期間にターゲット使用率を超える (または下回る) と、CloudWatch は、自動スケーリング呼び出してスケーリングポリシーを評価するアラームをトリガーします。
-
ElastiCache の自動スケーリングは、クラスター容量を調整するための変更リクエストを発行します。
-
ElastiCache は変更リクエストを処理してクラスターのシャード/レプリカの容量を動的に増減し、ターゲット使用率に近づけます。
ElastiCache の自動スケーリングの仕組みを理解するため、UsersCluster という名前のクラスターがあると仮定します。UsersCluster の CloudWatch メトリックスをモニタリングすることで、トラフィックがピークのときにクラスターが必要とする最大シャードを決定し、トラフィックが最小ポイントにあるときに最小シャードを決定します。また、UsersCluster クラスターの CPU 使用率のターゲット値を決定します。ElastiCache の自動スケーリングは、ターゲット追跡アルゴリズムを使用して、UsersCluster のプロビジョンされたシャードが必要に応じて調整され、使用率がターゲット値またはその近くに留まるようにします。
注記
スケーリングにはかなりの時間がかかることがあり、シャードを再調整するために余分なクラスターリソースが必要になります。ElastiCache の自動スケーリングは、実際のワークロードの増減が数分間維持された場合にのみ、リソース設定を変更します。自動スケーリングターゲット追跡アルゴリズムは、長期にわたってターゲット使用率を選択した値の付近に維持しようとします。
自動スケーリングに必要な IAM のアクセス許可
ElastiCache for Valkey と ElastiCache for Redis OSS の自動スケーリングは、ElastiCache、CloudWatch、および Application Auto Scaling API を組み合わせることで可能になります。クラスターは ElastiCache で作成および更新され、アラームは CloudWatch で作成され、スケーリングポリシーは Application Auto Scaling で作成されます。クラスターの作成および更新のための標準の IAM アクセス許可に加えて、ElastiCache の自動スケーリング設定にアクセスする IAM ユーザーは、動的スケーリングをサポートするサービスに対する適切なアクセス許可が必要です。この最新のポリシーでは、アクション elasticache:ModifyCacheCluster による Memcached 垂直スケーリングのサポートが追加されました。IAM ユーザーには、次のポリシー例に示すアクションを使用するためのアクセス許可が必要です。
サービスにリンクされたロール
ElastiCache for Valkey と ElastiCache for Redis OSS の自動スケーリングサービスでは、クラスターと CloudWatch のアラームを記述するためのアクセス許可と、ユーザーに代わって ElastiCache のターゲット容量を変更するためのアクセス許可も必要です。クラスターの自動スケーリングを有効にすると、AWSServiceRoleForApplicationAutoScaling_ElastiCacheRG という名前のサービスリンクロールが作成されます。このサービスリンクロールは、ElastiCache の自動スケーリングに対して、ポリシーのアラームの記述、フリートの現容量のモニタリング、およびフリートの容量変更を行うためのアクセス許可を付与します。サービスリンクロールは、ElastiCache の自動スケーリングのデフォルトロールです。詳細については、「Application Auto Scaling ユーザーガイド」の「ElastiCache for Redis OSS の自動スケーリングのサービスにリンクされたロール」を参照してください。
Auto Scaling のベストプラクティス
Auto Scaling に登録する前に、以下のことをお勧めします。
-
追跡メトリクスを 1 つだけ使用 — クラスターに CPU 負荷の高いワークロードまたはデータ集約型のワークロードがあるかどうかを識別し、対応する定義済みメトリックを使用してスケーリングポリシーを定義します。
-
エンジン CPU:
ElastiCachePrimaryEngineCPUUtilization(シャードディメンション) またはElastiCacheReplicaEngineCPUUtilization(レプリカディメンション) -
データベースの使用状況:
ElastiCacheDatabaseCapacityUsageCountedForEvictPercentageこのスケーリングポリシーは、クラスターで maxmemory-policy が noeviction に設定されている場合に最適です。
クラスターの 1 つのディメンションでポリシーが複数にならないようお勧めします。ElastiCache for Valkey と ElastiCache for Redis OSS の自動スケーリングでは、ターゲット追跡ポリシーのいずれかでスケールアウトする準備ができると、スケーラブルなターゲットがスケールアウトされますが、すべてのターゲット追跡ポリシー (スケールイン部分が有効) でスケールインする準備ができている場合のみスケールインされます。複数のポリシーによって、スケーラブルなターゲットが同時にスケールアウトまたはスケールインするように指示される場合、Auto Scaling は、スケールインとスケールアウトの両方で最大の容量を提供するポリシーに基づいてスケールします。
-
-
ターゲット追跡のカスタマイズされたメトリクス — Target Tracking 用にカスタマイズされたメトリクスを使用する場合は注意が必要です。Auto Scaling は、ポリシー用に選択されたメトリクスの変更に比例してスケールアウトするのに最適です。スケーリングアクションに比例して変更されないメトリクスがポリシーの作成に使用されると、可用性やコストに影響する可能性のあるスケールアウトまたはスケールインアクションが継続する可能性があります。
データ階層化クラスター (r6gd ファミリーのインスタンスタイプ) では、スケーリングにメモリベースのメトリクスを使用しないでください。
-
スケジュールに基づくスケーリング — ワークロードが確定的 (特定の時点で高/低に達する) であることが判明した場合は、スケジュールされたスケーリングを使用し、必要に応じてターゲット容量を設定することをお勧めします。ターゲット追跡は、非決定的なワークロードや、必要なターゲットメトリクスでクラスターを操作する場合に最適です。これにより、より多くのリソースが必要な場合はスケールアウトし、必要な場合はスケールインします。
-
スケールインを無効化する — ターゲット追跡での Auto Scaling は、ワークロードが徐々に増減するクラスターに最適です。メトリクスのスパイク/ディップが連続するスケールアウト/イン振動を引き起こす可能性があるためです。このような振動を避けるために、スケールインを無効にして開始し、後でいつでも必要に応じて手動でスケールインすることができます。
-
アプリケーションをテスト — 可用性の問題を回避するために、スケーリングポリシーを作成しながら、クラスターに必要な最小/最大シャード/レプリカの絶対値を決定するために、最小/最大ワークロードを推定してアプリケーションをテストすることをお勧めします。Auto Scaling は Max にスケールアウトし、ターゲットに設定された最小しきい値にスケールインできます。
-
ターゲット値の定義 — 4 週間のクラスター使用率の対応する CloudWatch メトリクスを分析し、目標値のしきい値を決定できます。選択する値が不明な場合は、サポートされる最小定義メトリクス値から開始することをお勧めします。
-
ターゲット追跡での AutoScaling は、シャード/レプリカのディメンション間でワークロードが均一に分散されるクラスターに最適です。不均一な分布を持つと、次のことが可能になります。
-
いくつかのホットシャード/レプリカでワークロードの急増/減少が原因で、必要のない場合のスケーリング。
-
ホットシャード/レプリカがあるにもかかわらず、全体的な平均ターゲットに近いために必要なときにスケーリングされません。
-
注記
クラスターをスケールアウトすると、ElastiCache は (ランダムに選択された) 既存のノードのいずれかにロードされた関数を新しいノードに自動的にレプリケートします。クラスターに Valkey または Redis OSS 7.0 以上があり、アプリケーションで関数
AutoScaling に登録したら、以下の点に注意してください。
-
Auto Scaling でサポートされる設定には制限があるため、Auto Scaling に登録されているレプリケーショングループの設定を変更しないことをお勧めします。次に例を示します。
-
インスタンスタイプをサポートされていないタイプに手動で変更します。
-
レプリケーショングループをグローバルデータストアに関連付けます。
-
ReservedMemoryPercentパラメータの変更。 -
ポリシーの作成時に設定された Min/Max 容量を超えるシャード/レプリカを手動で増減します。
-
