# ソース Aurora DB クラスターへのデータの追加とクエリ
Amazon Aurora から Amazon Redshift にデータをレプリケートするゼロ ETL 統合の作成を終了するには、ターゲット送信先にデータベースを作成する必要があります。
Amazon Redshift と接続するため、Amazon Redshift クラスターまたはワークグループに接続し、統合識別子を参照してデータベースを作成します。これで、ソースの Aurora DB クラスターにデータを追加でき、Amazon Redshift または Amazon SageMaker で複製されることが確認できます。
**Topics**
+ [ターゲットデータベースの作成](#zero-etl.create-db)
+ [ソースDB クラスターへのデータの追加](#zero-etl.add-data-rds)
+ [Amazon Redshift での Aurora データのクエリ](#zero-etl.query-data-redshift)
+ [Aurora データベースと Amazon Redshift データベース間のデータタイプの相違点](#zero-etl.data-type-mapping)
+ [Aurora PostgreSQL の DDL オペレーション](#zero-etl.ddl-postgres)
## ターゲットデータベースの作成
Amazon Redshift へのデータの複製を開始する前に、統合を作成後、データベースをターゲットのデータウェアハウスに作成する必要があります。このデータベースには、統合識別子への参照が含まれている必要があります。Amazon Redshift コンソールまたはクエリエディタ v2 を使用して、データベースを作成することができます。
デスティネーションデータベースを作成する手順については、「[Amazon Redshift にデスティネーションデータベースを作成する](https://docs.aws.amazon.com/redshift/latest/mgmt/zero-etl-using.creating-db.html#zero-etl-using.create-db)」を参照してください。
## ソースDB クラスターへのデータの追加
統合を設定した後で、データウェアハウスにレプリケートするデータを、ソースの Aurora DB クラスターに入力できます。
**注記**
Amazon Aurora のデータ型とターゲット分析ウェアハウスには違いがあります。データ型マッピングの表については、「[Aurora データベースと Amazon Redshift データベース間のデータタイプの相違点](#zero-etl.data-type-mapping)」を参照してください。
まず、任意の MySQL または PostgreSQL クライアントを使用して、ソース DB クラスターに接続します。手順については、「[Amazon Aurora DB クラスターへの接続](Aurora.Connecting.md)」を参照してください。
次に、テーブルを作成し、1 行のサンプルデータを挿入します。
**重要**
テーブルにプライマリキーがあることを確認してください。そうしないと、ターゲットのデータウェアハウスに複製できません。
pg\_dump および pg\_restore PostgreSQL ユーティリティは、最初にプライマリキーなしでテーブルを作成し、後で追加します。これらのユーティリティのいずれかを使用している場合は、まずスキーマを作成し、次に別のコマンドでデータをロードすることをお勧めします。
**MySQL**
次の例では、[MySQL Workbench ユーティリティ](https://dev.mysql.com/downloads/workbench/)を使用しています。
```
CREATE DATABASE {{my_db}};
USE {{my_db}};
CREATE TABLE {{books_table}} (ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL,
Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID));
INSERT INTO {{books_table}} VALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
```
**PostgreSQL**
次の例では、`[psql](https://www.postgresql.org/docs/current/app-psql.html)` PostgreSQL インタラクティブターミナルを使用しています。クラスターに接続するときは、統合の作成時に指定した名前付きデータベースを含めます。
```
psql -h {{mycluster}}.cluster-{{123456789012}}.us-east-2.rds.amazonaws.com -p 5432 -U {{username}} -d {{named_db}};
named_db=> CREATE TABLE {{books_table}} (ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL,
Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID));
named_db=> INSERT INTO {{books_table}} VALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
```
## Amazon Redshift での Aurora データのクエリ
Aurora DB クラスターにデータを追加すると、送信先データベースにレプリケートされ、クエリを実行できるようになります。
**複製されたデータをクエリするには**
1. Amazon Redshift コンソールに移動し、左側のナビゲーションペインから **[クエリエディタ v2]** を選択します。
1. クラスターまたはワークグループに接続し、ドロップダウンメニュー (この例では **destination\_database**) から送信先データベース (統合から作成したもの) を選択します。デスティネーションデータベースを作成する手順については、「[Amazon Redshift にデスティネーションデータベースを作成する](https://docs.aws.amazon.com/redshift/latest/mgmt/zero-etl-using.creating-db.html#zero-etl-using.create-db)」を参照してください。
1. SELECT ステートメントを使用してデータをクエリします。この例では、次のコマンドを実行して、ソースの Aurora DB クラスターで作成したテーブルからすべてのデータを選択します。
```
SELECT * from {{my_db}}."{{books_table}}";
```
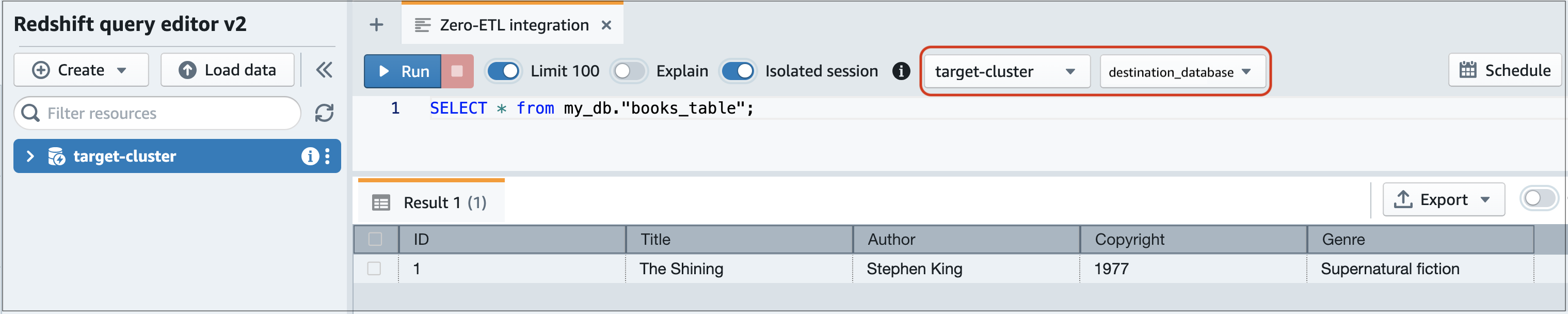
+ `{{my_db}}` は Aurora データベーススキーマ名です。このオプションは MySQL データベースにのみ必要です。
+ `{{books_table}}` は Aurora テーブル名です。
コマンドラインクライアントを使用してデータをクエリすることもできます。例えば、次のようになります。
```
destination_database=# select * from {{my_db}}."{{books_table}}";
ID | Title | Author | Copyright | Genre | txn_seq | txn_id
----+–------------+---------------+-------------+------------------------+----------+--------+
1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
```
**注記**
大文字と小文字を区別するには、スキーマ、テーブル、および列の名前を二重引用符 (" ") で囲みます。詳細については、「[enable\_case\_sensitive\_identifier](https://docs.aws.amazon.com/redshift/latest/dg/r_enable_case_sensitive_identifier.html)」を参照してください。
## Aurora データベースと Amazon Redshift データベース間のデータタイプの相違点
以下の表は、Aurora MySQL と Aurora PostgreSQL のデータタイプおよび対応する送信先のデータタイプのマッピングを示しています。*Amazon Aurora は現在、ゼロ ETL 統合ではこれらのデータ型のみをサポートしています。*
ソースDB クラスターのテーブルにサポートされていないデータ型が含まれている場合、そのテーブルは同期されず、送信先ターゲットで使用できなくなります。ソースからターゲットへのストリーミングは継続されますが、サポートされていないデータ型のテーブルは使用できません。テーブルを修正してターゲット送信先で使用できるようにするには、変更内容を手動で元に戻し、`[ALTER DATABASE...INTEGRATION REFRESH](https://docs.aws.amazon.com/redshift/latest/dg/r_ALTER_DATABASE.html)` を実行して統合を更新する必要があります。
**注記**
Amazon SageMaker Lakehouse とのゼロ ETL 統合を更新することはできません。代わりに、統合を削除して再度作成してみてください。
**Topics**
+ [Aurora MySQL](#zero-etl.data-type-mapping-mysql)
+ [Aurora PostgreSQL](#zero-etl.data-type-mapping-postgres)
### Aurora MySQL
| Aurora MySQL データ型 | ターゲットのデータ型 | 説明 | 制限事項 |
| --- | --- | --- | --- |
| INT | INTEGER | 符号付き 4 バイト整数 | なし |
| SMALLINT | SMALLINT | 符号付き 2 バイト整数 | なし |
| TINYINT | SMALLINT | 符号付き 2 バイト整数 | なし |
| MEDIUMINT | INTEGER | 符号付き 4 バイト整数 | なし |
| BIGINT | BIGINT | 符号付き 8 バイト整数 | なし |
| INT UNSIGNED | BIGINT | 符号付き 8 バイト整数 | なし |
| TINYINT UNSIGNED | SMALLINT | 符号付き 2 バイト整数 | なし |
| MEDIUMINT UNSIGNED | INTEGER | 符号付き 4 バイト整数 | なし |
| BIGINT UNSIGNED | DECIMAL(20,0) | 精度の選択が可能な真数 | なし |
| DECIMAL(p,s) = NUMERIC(p,s) | DECIMAL(p,s) | 精度の選択が可能な真数 | 精度が 38 より大きく、スケールが 37 より大きい場合、サポートされない |
| DECIMAL(p,s) UNSIGNED = NUMERIC(p,s) UNSIGNED | DECIMAL(p,s) | 精度の選択が可能な真数 | 精度が 38 より大きく、スケールが 37 より大きい場合、サポートされない |
| FLOAT4/REAL | REAL | 単精度浮動小数点数 | なし |
| FLOAT4/REAL UNSIGNED | REAL | 単精度浮動小数点数 | なし |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | 倍精度浮動小数点数 | なし |
| DOUBLE/REAL/FLOAT8 UNSIGNED | DOUBLE PRECISION | 倍精度浮動小数点数 | なし |
| BIT(n) | VARBYTE(8) | 可変長バイナリ値 | なし |
| BINARY(n) | VARBYTE(n) | 可変長バイナリ値 | なし |
| VARBINARY (n) | VARBYTE(n) | 可変長バイナリ値 | なし |
| CHAR(n) | VARCHAR(n) | 可変長文字列値 | なし |
| VARCHAR(n) | VARCHAR(n) | 可変長文字列値 | なし |
| TEXT | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| TINYTEXT | VARCHAR(255) | 最大 255 文字の可変長文字列値 | なし |
| MEDIUMTEXT | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| LONGTEXT | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| ENUM | VARCHAR(1,020) | 最大 1,020 文字の可変長文字列値 | なし |
| SET | VARCHAR(1,020) | 最大 1,020 文字の可変長文字列値 | なし |
| DATE | DATE | カレンダー日付 (年、月、日) | なし |
| DATETIME | TIMESTAMP | 日付と時刻 (タイムゾーンなし) | なし |
| TIMESTAMP(p) | TIMESTAMP | 日付と時刻 (タイムゾーンなし) | なし |
| TIME | VARCHAR(18) | 最大 18 文字の可変長文字列値 | なし |
| YEAR | VARCHAR(4) | 最大 4 文字の可変長文字列値 | なし |
| JSON | SUPER | 値としての半構造化データまたは文書 | なし |
### Aurora PostgreSQL
Aurora PostgreSQL のゼロ ETL 統合は、カスタムデータタイプ、または拡張機能で作成したデータタイプをサポートしていません。
| Aurora PostgreSQL データタイプ | Amazon Redshift データタイプ | 説明 | 制限事項 |
| --- | --- | --- | --- |
| array | SUPER | 値としての半構造化データまたは文書 | なし |
| bigint | BIGINT | 符号付き 8 バイト整数 | なし |
| bigserial | BIGINT | 符号付き 8 バイト整数 | なし |
| bit varying(n) | VARBYTE(n) | 最大 16,777,216 バイトの可変長バイナリ値 | なし |
| bit(n) | VARBYTE(n) | 最大 16,777,216 バイトの可変長バイナリ値 | なし |
| BIT、BIT VARYING | VARBYTE(16777216) | 最大 16,777,216 バイトの可変長バイナリ値 | なし |
| boolean | BOOLEAN | 論理ブール演算型 (true/false) | なし |
| bytea | VARBYTE(16777216) | 最大 16,777,216 バイトの可変長バイナリ値 | なし |
| char(n) | CHAR(n) | 最大 65,535 バイトの固定長文字列値 | なし |
| char varying(n) | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| cid | BIGINT | 符号付き 8 バイト整数 | なし |
| cidr | VARCHAR(19) | 最大 19 文字の可変長文字列値 | なし |
| date | DATE | カレンダー日付 (年、月、日) | 294,276 A.D. より大きい値はサポートされません |
| double precision | DOUBLE PRECISION | 倍精度浮動小数点数 | 非正規値は完全にはサポートされません |
| gtsvector | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| inet | VARCHAR(19) | 最大 19 文字の可変長文字列値 | なし |
| integer | INTEGER | 符号付き 4 バイト整数 | なし |
| int2vector | SUPER | 値としての半構造化データまたはドキュメント。 | なし |
| interval | INTERVAL | 期間 | year to month 修飾子または day to second 修飾子を指定する INTERVAL タイプのみがサポートされます。 |
| json | SUPER | 値としての半構造化データまたは文書 | なし |
| JSONB | SUPER | 値としての半構造化データまたは文書 | なし |
| jsonpath | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| macaddr | VARCHAR(17) | 最大 17 文字の可変長文字列値 | なし |
| macaddr8 | VARCHAR(23) | 最大 23 文字の可変長文字列値 | なし |
| money | DECIMAL(20,3) | 通貨額 | なし |
| 名前 | VARCHAR(64) | 最大 64 文字の可変長文字列値 | なし |
| numeric(p,s) | DECIMAL(p,s) | ユーザー定義の固定精度値 | [See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/zero-etl.querying.html) |
| oid | BIGINT | 符号付き 8 バイト整数 | なし |
| oidvector | SUPER | 値としての半構造化データまたはドキュメント。 | なし |
| pg\_brin\_bloom\_summary | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| pg\_dependencies | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| pg\_lsn | VARCHAR(17) | 最大 17 文字の可変長文字列値 | なし |
| pg\_mcv\_list | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| pg\_ndistinct | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| pg\_node\_tree | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| pg\_snapshot | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| real | REAL | 単精度浮動小数点数 | 非正規値は完全にはサポートされません |
| refcursor | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| smallint | SMALLINT | 符号付き 2 バイト整数 | なし |
| smallserial | SMALLINT | 符号付き 2 バイト整数 | なし |
| シリアル | INTEGER | 符号付き 4 バイト整数 | なし |
| text | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| tid | VARCHAR(23) | 最大 23 文字の可変長文字列値 | なし |
| time [(p)] without time zone | VARCHAR(19) | 最大 19 文字の可変長文字列値 | Infinity および -Infinity 値はサポートされていません |
| time [(p)] with time zone | VARCHAR(22) | 最大 22 文字の可変長文字列値 | Infinity および -Infinity 値はサポートされていません |
| timestamp [(p)] without time zone | TIMESTAMP | 日付と時刻 (タイムゾーンなし) | [See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/zero-etl.querying.html) |
| timestamp [(p)] with time zone | TIMESTAMPTZ | 日付と時刻 (タイムゾーンあり) | [See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/zero-etl.querying.html) |
| tsquery | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| tsvector | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| txid\_snapshot | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
| uuid | VARCHAR(36) | 可変長 36 文字の文字列 | なし |
| xid | BIGINT | 符号付き 8 バイト整数 | なし |
| xid8 | DECIMAL(20, 0) | 固定精度 10 進数 | なし |
| xml | VARCHAR(65,535) | 最大 65,535 文字の可変長文字列値 | なし |
## Aurora PostgreSQL の DDL オペレーション
Amazon Redshift は PostgreSQL から派生しているため、共通の PostgreSQL アーキテクチャに基づくいくつかの機能を Aurora PostgreSQL と共有しています。ゼロ ETL 統合は、これらの類似点を活用して、Aurora PostgreSQL から Amazon Redshift へのデータレプリケーションを合理化し、データベースを名前でマッピングして、共有のデータベース、スキーマ、テーブル構造を利用します。
Aurora PostgreSQL ゼロ ETL 統合を管理するときは、以下の点を考慮してください。
+ 分離はデータベースレベルで管理されます。
+ レプリケーションはデータベースレベルで行われます。
+ Aurora PostgreSQL データベースは Amazon Redshift データベースに名前でマッピングされるため、元の名前を変更すると、名前を変更した後の Redshift データベースにデータが流れます。
Amazon Redshift と Aurora PostgreSQL は類似していますが、重要な違いがあります。以下のセクションでは、一般的な DDL オペレーションに対する Amazon Redshift のシステムレスポンスについて概説します。
**Topics**
+ [データベースのオペレーション](#zero-etl.ddl-postgres-database)
+ [スキーマオペレーション](#zero-etl.ddl-postgres-schema)
+ [テーブルの操作](#zero-etl.ddl-postgres-table)
### データベースのオペレーション
次の表は、データベース DDL オペレーションのシステムレスポンスを示しています。
| DDL オペレーション | Redshift システムレスポンス |
| --- | --- |
| CREATE DATABASE | オペレーションなし |
| DROP DATABASE | Amazon Redshift は、ターゲット Redshift データベース内のすべてのデータを削除します。 |
| RENAME DATABASE | Amazon Redshift は、元のターゲットデータベース内のすべてのデータを削除し、新しいターゲットデータベース内のデータを再同期します。新しいデータベースが存在しない場合は、手動で作成する必要があります。手順については、「[Amazon Redshift でのデスティネーションデータベースの作成](https://docs.aws.amazon.com/redshift/latest/mgmt/zero-etl-using.creating-db.html#zero-etl-using.create-db)」を参照してください。 |
### スキーマオペレーション
次の表は、スキーマ DDL オペレーションのシステムレスポンスを示しています。
| DDL オペレーション | Redshift システムレスポンス |
| --- | --- |
| CREATE SCHEMA | オペレーションなし |
| DROP SCHEMA | Amazon Redshift は元のスキーマを削除します。 |
| RENAME SCHEMA | Amazon Redshift は元のスキーマを削除し、新しいスキーマ内のデータを再同期します。 |
### テーブルの操作
次の表は、テーブル DDL オペレーションのシステムレスポンスを示しています。
| DDL オペレーション | Redshift システムレスポンス |
| --- | --- |
| CREATE TABLE | Amazon Redshift はテーブルを作成します。
プライマリキーなしでテーブルを作成したり、宣言的パーティショニングを実行したりするなど、一部のオペレーションではテーブルの作成が失敗します。詳細については、「[制限事項](zero-etl.md#zero-etl.reqs-lims)」および「[Aurora ゼロ ETL 統合のトラブルシューティング](zero-etl.troubleshooting.md)」を参照してください。 |
| DROP TABLE | Amazon Redshift はテーブルを削除します。 |
| TRUNCATE TABLE | Amazon Redshift はテーブルを切り捨てます。 |
| ALTER TABLE (RENAME...) | Amazon Redshift はテーブルまたは列の名前を変更します。 |
| ALTER TABLE (SET SCHEMA) | Amazon Redshift は元のスキーマのテーブルを削除し、新しいスキーマのテーブルを再同期します。 |
| ALTER TABLE (ADD PRIMARY KEY) | Amazon Redshift はプライマリキーを追加し、テーブルを再同期します。 |
| ALTER TABLE (ADD COLUMN) | Amazon Redshift はテーブルに列を追加します。 |
| ALTER TABLE (DROP COLUMN) | Amazon Redshift は、プライマリキー列でない列を削除します。それ以外の場合は、テーブルを再同期します。 |
| ALTER TABLE (SET LOGGED/UNLOGGED) | テーブルをログ記録するように変更すると、Amazon Redshift はテーブルを再同期します。テーブルをログ記録しないように変更すると、Amazon Redshift はテーブルを削除します。 |