Amazon S3 Files の使用
トピック
S3 Files とは
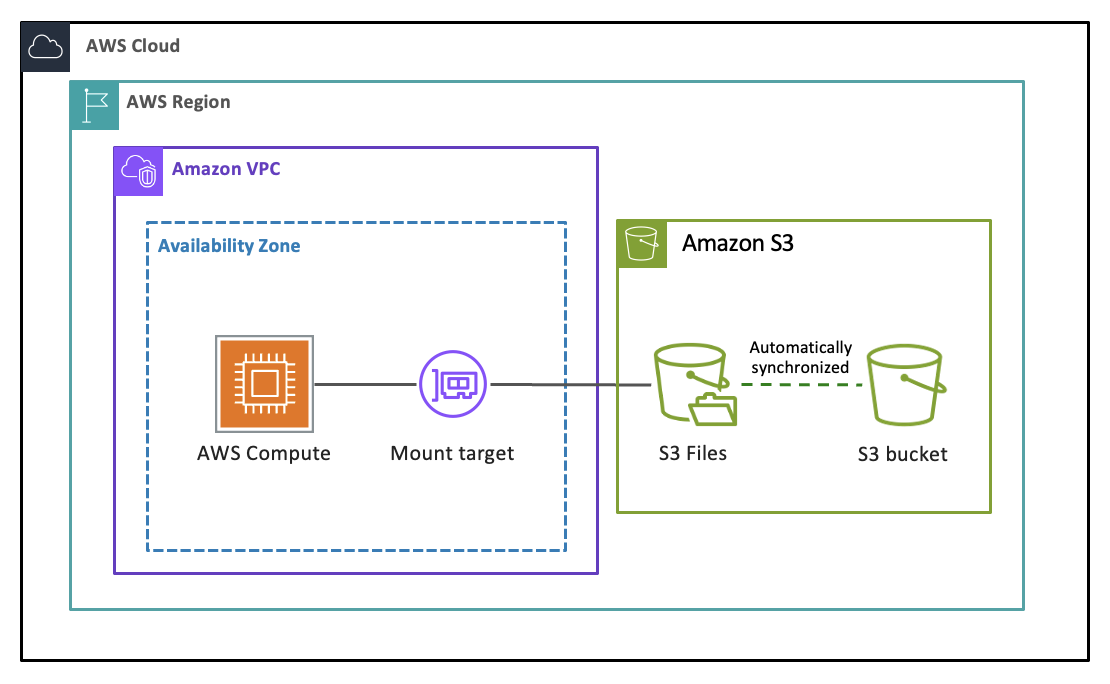
S3 Files は、任意の AWS コンピューティングリソースを Amazon S3 のデータに直接接続する共有ファイルシステムです。これにより、データが S3 を離れることなく、完全なファイルシステムのセマンティクスと低レイテンシーのパフォーマンスを備えたファイルとして、すべての S3 データにすばやく直接アクセスできます。すべてのファイルベースのアプリケーション、エージェント、チームは、既に依存しているツールを使用して、ファイルシステムとして S3 データにアクセスして操作できます。Amazon EFS を使用して構築された S3 Files は、ファイルシステムのパフォーマンスとシンプルさに加え、S3 のスケーラビリティ、耐久性、コスト効率を兼ね備えています。ファイルおよびディレクトリオペレーションを使用してデータの読み取り、書き込み、整理を行うことができ、S3 Files はバケットとファイルシステム間の変更の同期を管理します。
S3 Files の仕組み
S3 バケットまたは S3 バケット内のプレフィックスにリンクされた S3 ファイルシステムを作成し、それを EC2 インスタンスや Lambda 関数などのコンピューティングリソースにマウントすると、S3 Files はまずバケットのオブジェクトをファイルとして探索できるビューで表示します。ディレクトリを移動したりファイルを開いたりすると、関連するメタデータと内容がファイルシステムの高性能ストレージに配置されます。ファイルを読み取ると、S3 Files はデータセット全体を複製することなく、オンデマンドで高性能ストレージにファイルの内容をロードします。データを書き込むと、書き込みは高性能ストレージに送信され、S3 バケットに同期されます。S3 Files は、ファイルシステムのオペレーションを、ユーザーに代わって効率的な S3 リクエストにインテリジェントに変換します。多くの読み取りオペレーションはファイルシステムを完全にバイパスし、データは S3 から直接提供されます。
レイテンシーは小さなファイルにとって最も重要であるため、高性能ストレージにロードされるファイルサイズのしきい値 (デフォルトは 128 KiB 未満) を設定できます。S3 Files は、ファイルのデータがファイルシステムの高性能ストレージに保存されていない場合と、データがファイルシステムの高性能ストレージに存在していても 1 MiB 以上の大きな読み取りを行う場合の 2 つのケースで、S3 バケットからファイルの読み取りを直接ストリーミングします。S3 バケットは高スループット用に最適化され、ファイルシステムの高性能ストレージレイヤーは低レイテンシーアクセス用に最適化されています。S3 Files は、小さなファイル (デフォルトでは 128 KiB 未満) のデータをファイルシステムの高性能ストレージに非同期的にインポートし、後続の読み取り時に低レイテンシーアクセスを実現します。S3 にまだ同期されていない最近変更されたデータは、常にファイルシステムから提供されます。詳細については、「S3 Files の同期のカスタマイズ」を参照してください。
設定可能なウィンドウ (1~365 日、デフォルト 30) 内に読み取られなかったデータは、高性能ストレージから自動的に有効期限切れになります。信頼できるデータは常に S3 に残り、バックグラウンド同期によりファイルシステムとバケットの双方向の整合性が保たれます。詳細については、「同期の仕組みを理解する」を参照してください。
S3 ファイルシステムをマウントするためにサポートされているコンピューティングサービスは、Amazon EC2、AWS Lambda、Amazon EKS、Amazon ECS です。詳細については、「S3 バケットをコンピューティングリソースにマウントする」を参照してください。
S3 Files を初めてお使いになる方向けの情報
S3 Files を初めて使用する場合は、チュートリアル: S3 Files の開始方法 に従って S3 コンソールまたは AWS CLI を使用して最初の S3 ファイルシステムを作成します。
主要なコンセプト
S3 Files ドキュメントでは、次の用語が使用されます。
- ファイルシステム:
S3 バケットにリンクされた共有ファイルシステム。
- 高性能ストレージ
アクティブに使用されているファイルデータとメタデータが存在するファイルシステム内の低レイテンシーストレージレイヤー。S3 Files は自動的にこのストレージを管理し、ファイルにアクセスするとデータをコピーし、設定可能な有効期限内に読み取られなかったデータを削除します。高性能ストレージに存在するデータに対してストレージ料金が発生します。
- 同期
S3 Files がアクティブな作業データセットと変更をファイルシステムと S3 バケット間で一貫して維持するプロセス。インポートとは、S3 バケットからファイルシステムにデータをコピーすることです。エクスポートとは、ファイルシステム経由で行った変更を S3 バケットにコピーして書き戻すことです。S3 Files は、双方向で自動的に同期を実行します。
- マウントターゲット
マウントターゲットを使用すると、VPC 内の単一のアベイラビリティーゾーン内で、ファイルシステムへのネットワークアクセスが可能になります。コンピューティングリソースからファイルシステムにアクセスするには、少なくとも 1 つのマウントターゲットが必要であり、アベイラビリティーゾーンごとに最大 1 つのマウントターゲットを作成できます。
- アクセスポイント
アクセスポイントは、共有データセットのデータアクセスを大規模に管理することを簡素化する、ファイルシステムへのアプリケーション固有のエントリポイントです。アクセスポイントを使用すると、アクセスポイントを介したすべてのファイルシステムリクエストに対して、ユーザーの ID およびアクセス許可を適用できます。AWS マネジメントコンソールを使用してファイルシステムを作成すると、S3 Files はファイルシステムのアクセスポイントを 1 つ自動的に作成します。
機能
- フルデータレプリケーションなしでハイパフォーマンス
S3 Files は、アクティブなワーキングセットのみをデータセット全体ではなくファイルシステムの高性能ストレージにコピーすることで、低レイテンシーのファイルアクセスを実現します。頻繁にアクセスされる小さなファイルは、高性能ストレージから 1 ミリ秒未満のレイテンシーから 1 桁ミリ秒のレイテンシーで提供されます。大きな読み取りは、S3 から直接最大テラバイト/秒の集計スループットでストリーミングされます。つまり、インタラクティブなワークロードにはファイルシステムのパフォーマンスを、ストリーミングワークロードには S3 スループットを利用でき、使用していないデータや低レイテンシーの恩恵を受けないデータの保存やインポートに料金を支払う必要はありません。詳細については、「パフォーマンス仕様」を参照してください。
- インテリジェントな読み取りルーティング
S3 Files は、読み取りリクエストを最適なストレージレイヤー (S3 ファイルシステムまたは S3 バケット) に自動的にルーティングすると同時に、整合性、ロック、POSIX アクセス許可などの完全なファイルシステムのセマンティクスを維持します。低レイテンシーを実現するため、アクティブに使用されているファイルの小さなランダム読み取りは、高性能ストレージから提供されます。大規模なシーケンシャル読み取りやファイルシステム上にないデータの読み取りは、高スループットのために S3 バケットから直接提供され、ファイルシステムのデータ料金はかかりません。
- 自動同期
S3 Files は、ファイルシステムと S3 バケット間の整合性を双方向で自動的に維持します。ファイルシステムを通じて行った変更は S3 バケットにコピーされ、S3 バケットに直接行われた変更はファイルシステムのビューに反映されます。インポートされるデータやファイルシステムに保持される期間など、同期動作をカスタマイズできます。詳細については、「同期の仕組みを理解する」を参照してください。
- スケーラブルなパフォーマンス
S3 Files は、ワークロードのアクティビティに合わせてスループットと IOPS を自動的にスケーリングします。パフォーマンス容量のプロビジョニングや管理は不要で、使用分のみお支払いいただきます。
- リージョンの耐久性
高性能ストレージレイヤーに書き込まれるデータは、Amazon S3 と同等の耐久性を備えています。同じ AWS リージョン内の複数の地理的に分離されたアベイラビリティーゾーンにデータを冗長的に格納するため、データの耐久性と可用性が向上します。
- Encryption
S3 Files は、TLS を使用して転送中のすべてのデータを暗号化し、KMS AWS キーを使用して保管中のすべてのデータを暗号化します。AWS 所有キー (デフォルト) または独自のカスタマーマネージドキーを使用できます。詳細については、「暗号化」を参照してください。
- ファイルシステムのセマンティクス
S3 Files は、NFS バージョン 4.2 および 4.1 プロトコルをサポートしています。書き込み後読み取りデータ整合性、ファイルロック、POSIX アクセス許可などのファイルシステムアクセスのセマンティクスを提供します。
S3 Files に対する請求方法
高性能ストレージに保存されているアクティブなデータの割合に対してストレージ料金を支払い、ファイルシステムの高性能ストレージとの間で読み書きするためのファイルシステムアクセス料金を支払います。S3 Files は、ファイルのデータがファイルシステムの高性能ストレージに保存されていない場合と、データがファイルシステムの高性能ストレージに存在していても 1 MiB 以上の大きな読み取りを行う場合の 2 つのケースで、S3 バケットからファイルの読み取りを直接ストリーミングします。S3 バケットは高スループット用に最適化され、ファイルシステムの高性能ストレージレイヤーは低レイテンシーアクセス用に最適化されています。S3 Files は、小さなファイル (デフォルトでは 128 KiB 未満) のデータをファイルシステムの高性能ストレージに非同期的にインポートし、後続の読み取り時に低レイテンシーアクセスを実現します。これらの読み取りには、標準の S3 GET リクエストコストのみが発生し、ファイルシステムへのアクセス料金はかかりません。ファイルシステムアクセス料金は同期オペレーションに適用されます。ファイルシステムにデータをインポートすると書き込み料金が発生し、変更を S3 にエクスポートすると読み取り料金が発生します。詳細については、「S3 Files の計測方法」を参照してください。現在の料金については、「S3 Files の料金ページ
