翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
を使用した Hadoop ワークロードの Amazon EMR への移行 AWS Schema Conversion Tool
Apache Hadoop クラスターを移行するには、 AWS SCT バージョン 1.0.670 以降を使用していることを確認してください。また、 AWS SCTのコマンドラインインターフェイス (CLI) についても理解しておいてください。詳細については、「の CLI リファレンス AWS Schema Conversion Tool」を参照してください。
トピック
移行の概要
以下の画像は、Apache Hadoop から Amazon EMR への移行のアーキテクチャ図を示しています。
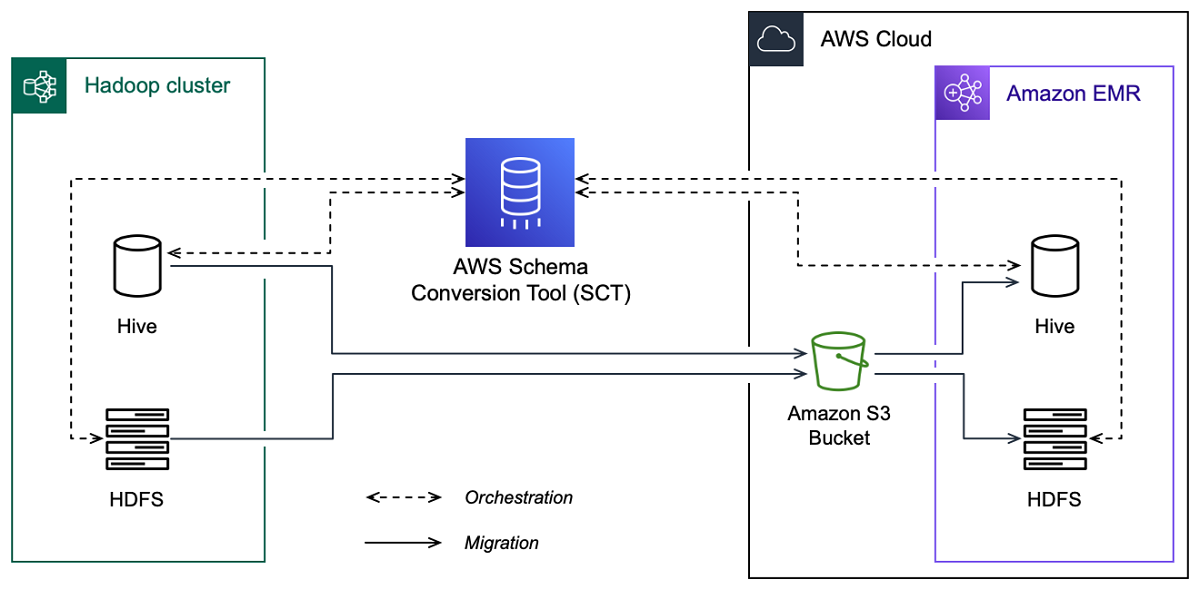
AWS SCT は、ソース Hadoop クラスターから Amazon S3 バケットにデータとメタデータを移行します。次に、 AWS SCT がソースの Hive メタデータを使用して、ターゲット Amazon EMR Hive サービスにデータベースオブジェクトを作成します。必要に応じて、 をメタストア AWS Glue Data Catalog として使用するように Hive を設定できます。この場合、 はソース Hive メタデータを AWS SCT に移行します AWS Glue Data Catalog。
次に、 AWS SCT を使用して Amazon S3 バケットからターゲットの Amazon EMR HDFS サービスにデータを移行できます。または、データを Amazon S3 バケットに残して、Hadoop ワークロードのデータリポジトリとして使用することもできます。
Hapood 移行を開始するには、CLI AWS SCT スクリプトを作成して実行します。このスクリプトには、移行を実行するためのコマンド一式が含まれています。Hadoop 移行スクリプトのテンプレートをダウンロードして編集できます。詳細については、「CLI シナリオの取得」を参照してください。
Apache Hadoop から Amazon S3 と Amazon EMR への移行を実行できるように、スクリプトに次のステップが含まれていることを確認してください。
ステップ 1: Hadoop クラスターに接続する
Apache Hadoop クラスターの移行を開始するには、新しい AWS SCT プロジェクトを作成します。次に、ソースクラスターとターゲットクラスターに接続します。移行を開始する前に、必ずターゲット AWS リソースを作成してプロビジョニングしてください。
このステップでは、次の AWS SCT CLI コマンドを使用します。
CreateProject– 新しい AWS SCT プロジェクトを作成します。AddSourceCluster– AWS SCT プロジェクト内のソース Hadoop クラスターに接続します。AddSourceClusterHive– プロジェクト内のソース Hive サービスに接続します。AddSourceClusterHDFS– プロジェクト内のソース HDFS サービスに接続します。AddTargetCluster– プロジェクト内のターゲット Amazon EMR クラスターに接続します。AddTargetClusterS3– Amazon S3 バケットをプロジェクトに追加します。AddTargetClusterHive– プロジェクト内のターゲット Hive サービスに接続します。AddTargetClusterHDFS– プロジェクト内のターゲット HDFS サービスに接続します。
これらの CLI コマンドを使用する例については、 AWS SCT 「」を参照してくださいApache Hadoop への接続。
ソースクラスターまたはターゲットクラスターに接続する コマンドを実行すると、 はこのクラスターへの接続を確立 AWS SCT しようとします。接続の試行が失敗すると、 は CLI スクリプトからのコマンドの実行 AWS SCT を停止し、エラーメッセージを表示します。
ステップ 2: マッピングルールを設定する
ソースクラスターとターゲットクラスターに接続したら、マッピングルールを設定します。マッピングルールは、ソースクラスターの移行ターゲットを定義します。 AWS SCT プロジェクトに追加したすべてのソースクラスターのマッピングルールを設定してください。テーブルマッピングの詳細については、「AWS Schema Conversion Tool でのデータ型のマッピング」を参照してください。
このステップでは、AddServerMapping コマンドを使用します。このコマンドは、ソースクラスターとターゲットクラスターを定義する 2 つのパラメータを使用します。この AddServerMapping コマンドは、データベースオブジェクトへの明示的なパスまたはオブジェクト名とともに使用できます。1 つ目のオプションには、オブジェクトのタイプと名前を指定します。2 つ目のオプションには、オブジェクト名のみを指定します。
-
sourceTreePath— ソースデータベースオブジェクトへの明示的なパス。targetTreePath— ターゲットデータベースオブジェクトへの明示的なパス。 -
sourceNamePath— ソースオブジェクトの名前のみを含むパス。targetNamePath— ターゲットオブジェクトの名前のみを含むパス。
次のコード例では、ソース testdb Hive データベースとターゲット EMR クラスターの明示的なパスを使用してマッピングルールを作成します。
AddServerMapping -sourceTreePath: 'Clusters.HADOOP_SOURCE.HIVE_SOURCE.Databases.testdb' -targetTreePath: 'Clusters.HADOOP_TARGET.HIVE_TARGET' /
Windows では、この例と以下の例を使用できます。Linux で CLI コマンドを実行するには、使用しているオペレーティングシステムに合わせてファイルパスを適切に更新してください。
次のコード例では、オブジェクト名のみを含むパスを使用してマッピングルールを作成します。
AddServerMapping -sourceNamePath: 'HADOOP_SOURCE.HIVE_SOURCE.testdb' -targetNamePath: 'HADOOP_TARGET.HIVE_TARGET' /
ソースオブジェクトのターゲットとして Amazon EMR または Amazon S3 を選択できます。ソースオブジェクトごとに、1 つの AWS SCT プロジェクトで選択できるターゲットは 1 つだけです。ソースオブジェクトの移行ターゲットを変更するには、既存のマッピングルールを削除し、新しいマッピングルールを作成します。マッピングルールを削除するには、DeleteServerMapping コマンドを使用します。このコマンドは、次の 2 つのパラメータのうちの 1 つを使用します。
sourceTreePath— ソースデータベースオブジェクトへの明示的なパス。sourceNamePath— ソースオブジェクトの名前のみを含むパス。
AddServerMapping および DeleteServerMapping コマンドの詳細については、『AWS Schema Conversion Tool CLI リファレンス
ステップ 3: 評価レポートを作成する
移行を開始する前に、評価レポートを作成することをお勧めします。このレポートには、すべての移行タスクがまとめられ、移行中に明らかになるアクションアイテムが詳しく説明されています。移行が失敗しないようにするには、このレポートを参照して、移行前のアクションアイテムに対処してください。詳細については、「評価レポート」を参照してください。
このステップでは、CreateMigrationReport コマンドを使用します。このコマンドは、2 つのパラメータを使用します。treePath パラメーターは必須で、forceMigrate パラメーターはオプションです。
treePath— 評価レポートのコピーを保存するソースデータベースオブジェクトへの明示的なパス。forceMigrate– に設定するとtrue、プロジェクトに同じオブジェクトを参照する HDFS フォルダと Hive テーブルが含まれている場合でも、 は移行 AWS SCT を続行します。デフォルト値はfalseです。
その後、評価レポートのコピーを PDF またはカンマ区切り (CSV) ファイルとして保存できます。これを行うには、SaveReportPDF コマンドまたは SaveReportCSV コマンドを使用します。
SaveReportPDF コマンドは、評価レポートのコピーを PDF ファイルとして保存します。このコマンドは、4 つのパラメータを使用します。file パラメータは必須です。他のパラメータはオプションです。
file— PDF ファイルへのパスとその名前。filter— 移行するソースオブジェクトの範囲を定義するために以前に作成したフィルタの名前。treePath— 評価レポートのコピーを保存するソースデータベースオブジェクトへの明示的なパス。namePath— 評価レポートのコピーを保存する対象オブジェクトの名前のみを含むパス。
SaveReportCSV コマンドは、評価レポートを 3 つの CSV ファイルに保存します。このコマンドは、4 つのパラメータを使用します。directory パラメータは必須です。他のパラメータはオプションです。
directory– が CSV ファイル AWS SCT を保存するフォルダへのパス。filter— 移行するソースオブジェクトの範囲を定義するために以前に作成したフィルタの名前。treePath— 評価レポートのコピーを保存するソースデータベースオブジェクトへの明示的なパス。namePath— 評価レポートのコピーを保存する対象オブジェクトの名前のみを含むパス。
次のコード例では、評価レポートのコピーを c:\sct\ar.pdf ファイルに保存しています。
SaveReportPDF -file:'c:\sct\ar.pdf' /
次のコード例では、評価レポートのコピーを CSV ファイルとして c:\sct フォルダに保存します。
SaveReportCSV -file:'c:\sct' /
SaveReportPDF および SaveReportCSV コマンドの詳細については、『AWS Schema Conversion Tool CLI リファレンス
ステップ 4: を使用して Apache Hadoop クラスターを Amazon EMR に移行する AWS SCT
AWS SCT プロジェクトを設定したら、オンプレミスの Apache Hadoop クラスターの への移行を開始します AWS クラウド。
このステップでは、Migrate、MigrationStatus、ResumeMigration コマンドを使用します。
Migrate コマンドは、ソースオブジェクトをターゲットクラスターに移行します。このコマンドは、4 つのパラメータを使用します。必ず filter または treePathパラメータを指定してください。その他のパラメータは省略可能です。
filter— 移行するソースオブジェクトの範囲を定義するために以前に作成したフィルタの名前。treePath— 評価レポートのコピーを保存するソースデータベースオブジェクトへの明示的なパス。forceLoad– に設定するとtrue、 は移行中にデータベースメタデータツリー AWS SCT を自動的にロードします。デフォルト値はfalseです。forceMigrate– に設定するとtrue、プロジェクトに同じオブジェクトを参照する HDFS フォルダと Hive テーブルが含まれている場合でも、 は移行 AWS SCT を続行します。デフォルト値はfalseです。
MigrationStatus コマンドは、移行の進捗に関する情報を返します。このコマンドを実行するには、name パラメータに移行プロジェクトの名前を入力します。この名前は CreateProject コマンドで指定しました。
ResumeMigration コマンドは、Migrate コマンドを使用して起動した中断された移行を再開します。ResumeMigration コマンドはパラメータを使用しません。移行を再開するには、ソースクラスターとターゲットクラスターに接続する必要があります。詳細については、「移行プロジェクトの管理」を参照してください。
次のコード例では、ソース HDFS サービスから Amazon EMR にデータを移行します。
Migrate -treePath: 'Clusters.HADOOP_SOURCE.HDFS_SOURCE' -forceMigrate: 'true' /
CLI スクリプトの実行
AWS SCT CLI スクリプトの編集が完了したら、.scts拡張子が付いたファイルとして保存します。これで、 AWS SCT インストールパスの appフォルダからスクリプトを実行できます。そのためには、次のコマンドを使用します。
RunSCTBatch.cmd --pathtoscts "C:\script_path\hadoop.scts"
前の例では、script_path を CLI スクリプトを含むファイルへのパスに置き換えます。で CLI スクリプトを実行する方法の詳細については AWS SCT、「」を参照してくださいスクリプトモード。
ビッグデータ移行プロジェクトの管理
移行が完了したら、今後の使用のために AWS SCT プロジェクトを保存および編集できます。
AWS SCT プロジェクトを保存するには、 SaveProject コマンドを使用します。このコマンドはパラメータを使用しません。
次のコード例では、 AWS SCT プロジェクトを保存します。
SaveProject /
AWS SCT プロジェクトを開くには、 OpenProject コマンドを使用します。このコマンドは必須パラメータを 1 つ使用します。file パラメータには、 AWS SCT プロジェクトファイルへのパスとその名前を入力します。CreateProject コマンドでプロジェクト名を指定しました。OpenProject コマンドを実行するには、.scts プロジェクトファイルの名前に拡張子を必ず追加してください。
次のコード例では、c:\sct フォルダから hadoop_emr プロジェクトを開きます。
OpenProject -file: 'c:\sct\hadoop_emr.scts' /
AWS SCT プロジェクトを開いた後は、ソースクラスターとターゲットクラスターをプロジェクトに追加済みであるため、追加する必要はありません。ソースクラスターとターゲットクラスターでの作業を開始するには、それらに接続する必要があります。これを行うには、ConnectSourceCluster および ConnectTargetCluster コマンドを使用します。これらのコマンドは、AddSourceCluster および AddTargetCluster コマンドと同じパラメータを使用します。CLI スクリプトを編集し、これらのコマンドの名前を置き換えてもパラメータのリストは変更されません。
次のコード例では、ソース Hadoop クラスターに接続します。
ConnectSourceCluster -name: 'HADOOP_SOURCE' -vendor: 'HADOOP' -host: 'hadoop_address' -port: '22' -user: 'hadoop_user' -password: 'hadoop_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: 'hadoop_passphrase' /
次のコード例では、ターゲットの Amazon EMR クラスターに接続します。
ConnectTargetCluster -name: 'HADOOP_TARGET' -vendor: 'AMAZON_EMR' -host: 'ec2-44-44-55-66.eu-west-1.EXAMPLE.amazonaws.com' -port: '22' -user: 'emr_user' -password: 'emr_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: '1234567890abcdef0!' -s3Name: 'S3_TARGET' -accessKey: 'AKIAIOSFODNN7EXAMPLE' -secretKey: 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY' -region: 'eu-west-1' -s3Path: 'doc-example-bucket/example-folder' /
前の例では、hadoop_address を Hadoop クラスターの IP アドレスに置き換えてください。必要に応じて、ポート変数の値を設定します。次に、hadoop_user と hadoop_password を、Hadoop ユーザーの名前とこのユーザーのパスワードに置き換えます。path\name には、ソース Hadoop クラスターの PEM ファイルの名前とパスを入力します。ソースクラスターとターゲットクラスターの追加の詳細情報については、「を使用した Apache Hadoop データベースへの接続 AWS Schema Conversion Tool」を参照してください。
ソースとターゲットの Hadoop クラスターに接続したら、Amazon S3 バケットだけでなく、Hive と HDFS サービスにも接続する必要があります。これを行うには、ConnectSourceClusterHive、ConnectSourceClusterHdfs、ConnectTargetClusterHive、ConnectTargetClusterHdfs、ConnectTargetClusterS3 コマンドを使用します。これらのコマンドは、Hive サービス、HDFS サービス、および Amazon S3 バケットをプロジェクトに追加する際に使用したコマンドと同じパラメータを使用します。CLI スクリプトを編集して、コマンド名の Add プレフィックスを Connect に置き換えます。
