Amazon DynamoDB のコアコンポーネント
DynamoDB では、テーブル、項目、および属性が、操作するコアコンポーネントです。テーブルは項目の集合であり、各項目は属性の集合です。DynamoDB は、テーブルの各項目を一意に識別するために、プライマリキーを使用します。DynamoDB Streams を使用して、DynamoDB テーブルのデータ変更イベントをキャプチャできます。
DynamoDB には制限があります。詳細については、「Amazon DynamoDB のクォータ」を参照してください。
次の動画では、テーブル、項目、および属性の概要を説明します。
テーブル、項目、属性
基本的な DynamoDB コンポーネントは以下のとおりです。
-
テーブル – 他のデータベースシステムと同様、DynamoDB はデータをテーブルに保存します。テーブルは、データのコレクションです。たとえば、テーブルの例 (People) を参照してください。このテーブルは、友人、家族、関心のある人に関する個人の連絡先情報を保存するのに使用できます。また、その人たちが運転する車に関する情報を保存する Cars テーブルを作成することもできます。
-
項目 – 各テーブルにはゼロ以上の項目が含まれています。項目は、他のすべての項目間で一意に識別可能な属性のグループです。People テーブルの各項目は、人を表します。Cars テーブルの各項目は 1 台の車を表します。DynamoDB の項目は、多くの点で他のデータベースシステムの行、レコード、またはタプルに似ています。DynamoDB では、テーブルに保存できる項目数に制限はありません。
-
属性 – 各項目は 1 つ以上の属性で構成されます。属性は、基盤となるデータ要素であり、それ以上分割する必要がないものです。例えば、People テーブルの項目には、PersonID、LastName、FirstName といった名前の属性が含まれます。Department テーブルでは、項目が DepartmentID、Name、Manager などの属性を設定することができます。DynamoDB 内の属性は、多くの点で他のデータベースシステムのフィールドや列に似ています。
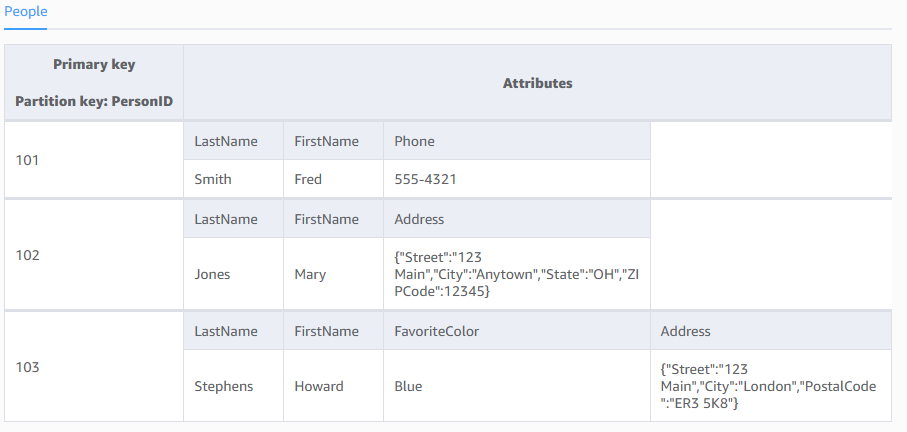
次の図は、いくつかの項目と属性の例を含む、People という名前のテーブルを示しています。
People
{
"PersonID": 101,
"LastName": "Smith",
"FirstName": "Fred",
"Phone": "555-4321"
}
{
"PersonID": 102,
"LastName": "Jones",
"FirstName": "Mary",
"Address": {
"Street": "123 Main",
"City": "Anytown",
"State": "OH",
"ZIPCode": 12345
}
}
{
"PersonID": 103,
"LastName": "Stephens",
"FirstName": "Howard",
"Address": {
"Street": "123 Main",
"City": "London",
"PostalCode": "ER3 5K8"
},
"FavoriteColor": "Blue"
}People テーブルについて、以下の点に注意してください。
-
テーブルの各項目には一意の識別子があります。これは、テーブルの他のすべての項目からその項目を区別するプライマリキーです。People テーブルで、プライマリキーは 1 つの属性 (PersonID) で構成されます。
-
プライマリキー以外、People テーブルはスキーマレスです。つまり、属性またはデータ型を事前に定義する必要はありません。各項目は、独自の固有の属性を持つことができます。
-
属性のほとんどはスカラーです。つまり、1 つの値のみを持つことができます。文字列と数値はスカラーの一般的な例です。
-
一部の項目には、ネストされた属性 (アドレス) があります。DynamoDB は深さが最大 32 レベルの入れ子の属性をサポートします。
以下は、音楽コレクションを追跡するために使用できる、Music という名前の別のサンプルテーブルです。
Music
{
"Artist": "No One You Know",
"SongTitle": "My Dog Spot",
"AlbumTitle": "Hey Now",
"Price": 1.98,
"Genre": "Country",
"CriticRating": 8.4
}
{
"Artist": "No One You Know",
"SongTitle": "Somewhere Down The Road",
"AlbumTitle": "Somewhat Famous",
"Genre": "Country",
"CriticRating": 8.4,
"Year": 1984
}
{
"Artist": "The Acme Band",
"SongTitle": "Still in Love",
"AlbumTitle": "The Buck Starts Here",
"Price": 2.47,
"Genre": "Rock",
"PromotionInfo": {
"RadioStationsPlaying": [
"KHCR",
"KQBX",
"WTNR",
"WJJH"
],
"TourDates": {
"Seattle": "20150622",
"Cleveland": "20150630"
},
"Rotation": "Heavy"
}
}
{
"Artist": "The Acme Band",
"SongTitle": "Look Out, World",
"AlbumTitle": "The Buck Starts Here",
"Price": 0.99,
"Genre": "Rock"
} Music テーブルについて、以下の点に注意してください。
-
Music のプライマリキーは 2 つの属性 (Artist および SongTitle) で構成されます。テーブルの各項目にはこれら 2 つの属性が必要です。Artist および SongTitle の組み合わせにより、テーブルの各項目が他のすべての項目から区別されます。
-
プライマリキー以外、Music テーブルはスキーマレスです。つまり、属性またはデータ型を事前に定義する必要はありません。各項目は、独自の固有の属性を持つことができます。
-
項目の 1 つに、入れ子の属性 (PromotionInfo) があります。これには、入れ子の他の属性が含まれます。DynamoDB は深さが最大 32 レベルの入れ子の属性をサポートします。
詳細については、「DynamoDB でのテーブルとデータの操作」を参照してください。
プライマリキー
テーブルを作成する場合には、テーブル名に加えて、テーブルのプライマリキーを指定する必要があります。プライマリキーはテーブルの各項目を一意に識別するため、テーブル内の 2 つの項目が同じキーを持つことはありません。
DynamoDB は 2 種類の異なるプライマリキーをサポートします。
-
パーティションキー – パーティションキーという 1 つの属性で構成されたシンプルなプライマリキー。
DynamoDB は、パーティションキーの値を内部ハッシュ関数への入力として使用します。ハッシュ関数からの出力により、項目が保存されるパーティション (DynamoDB 内部の物理ストレージ) が決まります。
パーティションキーのみを含むテーブルでは、2 つの項目が同じパーティションキー値を持つことはできません。
テーブル、項目、属性 で説明されている People テーブルは、単純なプライマリキー (PersonID) を持つテーブルの例です。People テーブル内の任意の項目に直接アクセスするには、その項目の PersonId 値を指定します。
-
パーティションとソートキー – 複合プライマリキーと呼ばれるこのキーのタイプは、2 つの属性で構成されます。最初の属性はパーティションキーであり、2 番目の属性はソートキーです。
DynamoDB は、パーティションキーバリューを内部ハッシュ関数への入力として使用します。ハッシュ関数からの出力により、項目が保存されるパーティション (DynamoDB 内部の物理ストレージ) が決まります。同じパーティションキー値を持つすべての項目は、ソートキー値でソートされてまとめて保存されます。
パーティションキーとソートキーが存在するテーブルでは、同じパーティションのキーバリューが複数の項目に割り当てられることがあります。ただし、ソートキー値は複数の項目で異なる必要があります。
テーブル、項目、属性 で説明されている Music テーブルは、複合プライマリキー (Artist および SongTitle) を持つテーブルの例です。その項目に Artist と SongTitle の値を指定すると、Music テーブルの任意の項目に直接アクセスできます。
複合プライマリキーは、データのクエリを実行するときに柔軟性を高めます。たとえば、Artist の値のみを指定した場合、DynamoDB はそのアーティストのすべての曲を取得します。特定のアーティストの曲のサブセットのみを取得するには、Artist の値と SongTitle の値範囲を指定します。
注記
項目のパーティションキーは、そのハッシュ属性とも呼ばれます。ハッシュ属性という用語は、DynamoDB が内部のハッシュ関数を使用し、パーティションキーバリューに基づいてパーティション間でデータ項目を均等に分散することに由来しています。
項目のソートキーは、範囲属性とも呼ばれます。範囲属性という用語は、ソートキーバリューで並べ替えられた順に、DynamoDB が同じパーティションキーを持つ項目同士を物理的に近くに保存する方法に由来しています。
各プライマリキー属性はスカラー値 (単一値のみを保持できる) である必要があります。プライマリキー属性に許可される唯一のデータ型は、文字列、数値、またはバイナリです。他のキー以外の属性では、このような制限はありません。
セカンダリインデックス
テーブルで 1 つ以上のセカンダリインデックスを作成できます。セカンダリインデックスでは、プライマリキーに対するクエリに加えて、代替キーを使用して、テーブル内のデータのクエリを行うことができます。DynamoDB では、インデックスを使用する必要はありませんが、インデックスを使用すると、データのクエリを行う際にアプリケーションの柔軟性が高まります。テーブルにグローバルセカンダリインデックスを作成すると、テーブルから行う場合とほぼ同じ方法でインデックスからデータを読み取ることができます。
DynamoDB では、次の 2 種類のインデックスをサポートしています。
-
グローバルセカンダリインデックス – パーティションキーおよびソートキーを持つインデックス。テーブルのものとは異なる場合があります。グローバルセカンダリインデックスのプライマリキーの値は一意である必要はありません。
-
ローカルセカンダリインデックス – パーティションキーはテーブルと同じですが、ソートキーが異なるインデックスです。
DynamoDB では、グローバルセカンダリインデックス (GSI) はテーブル全体にまたがるインデックスであり、すべてのパーティションキーをクエリできます。ローカルセカンダリインデックス (LSI)は、ベーステーブルとパーティションキーは同じで、ソートキーが異なるインデックスです。
DynamoDB の各テーブルには、20 個のグローバルセカンダリーインデックス (デフォルトのクォータ) と、5 個のローカルセカンダリーインデックスのクォータがあります。
前に示した Music サンプルテーブルでは、Artist (パーティションキー) または Artist および SongTitle (パーティションキーとソートキー) によってデータ項目にクエリを実行できます。Genre および AlbumTitle によってデータにクエリを実行する場合はどうでしょうか。これを行うには、Genre および AlbumTitle にインデックスを作成し、Music テーブルのクエリと同様に、インデックスにクエリを実行できます。
次の図表は、GenreAlbumTitle という新しいインデックスを持つ Music テーブルの例を示しています。このインデックスでは、Genre がパーティションキーで、AlbumTitle がソートキーです。
| Music テーブル | GenreAlbumTitle |
|---|---|
|
|
|
|
|
|
|
|
GenreAlbumTitle インデックスについて、以下の点に注意してください。
-
各インデックスはテーブルに属します。これをインデックスの基本テーブルと呼びます。前述の例では、Music が GenreAlbumTitle インデックスの基本テーブルです。
-
DynamoDB はインデックスを自動的に維持します。基本テーブルの項目を追加、更新、または削除すると、DynamoDB はそのテーブルに属するすべてのインデックスの対応する項目を追加、更新、または削除します。
-
インデックスを作成するときは、基本テーブルからインデックスにコピーまたは射影される属性を指定します。少なくとも、DynamoDB は基本テーブルからインデックスにキー属性を射影します。これは
GenreAlbumTitleのケースで、Musicテーブルのキー属性のみがインデックスに射影されます。
GenreAlbumTitle インデックスにクエリを実行し、特定のジャンルのすべてのアルバム (たとえば、すべての Rock アルバム) を検索できます。また、インデックスにクエリを実行して、特定のジャンル内のすべてのアルバムのうち、特定のアルバムタイトル (たとえば、タイトルが文字 H で始まるすべての Country アルバム) のみを検索することもできます。
詳細については、「DynamoDB でのセカンダリインデックスを使用したデータアクセス性の向上」を参照してください。
DynamoDB Streams
DynamoDB Streams は、DynamoDB テーブルのデータ変更イベントをキャプチャするオプションの特徴です。これらのイベントに関するデータは、ほとんどリアルタイムに、イベントの発生順にストリームに表示されます。
各イベントはストリームレコードによって表されます。テーブルでストリーミングを有効にすると、DynamoDB Streams は次のいずれかのイベントが発生するたびに、ストリーミングレコードを書き込みます。
-
新しい項目がテーブルに追加された場合: ストリームは、すべての属性を含む項目全体のイメージをキャプチャします。
-
項目が更新された場合: ストリームは、項目で変更された属性について、「前」と「後」のイメージをキャプチャします。
-
テーブルから項目が削除された場合: ストリームは、項目が削除される前に項目全体のイメージをキャプチャします。
各ストリームレコードには、テーブルの名前、イベントのタイムスタンプ、およびその他のメタデータも含まれます。ストリームレコードには 24 時間の有効期間があり、その後はストリームから自動的に削除されます。
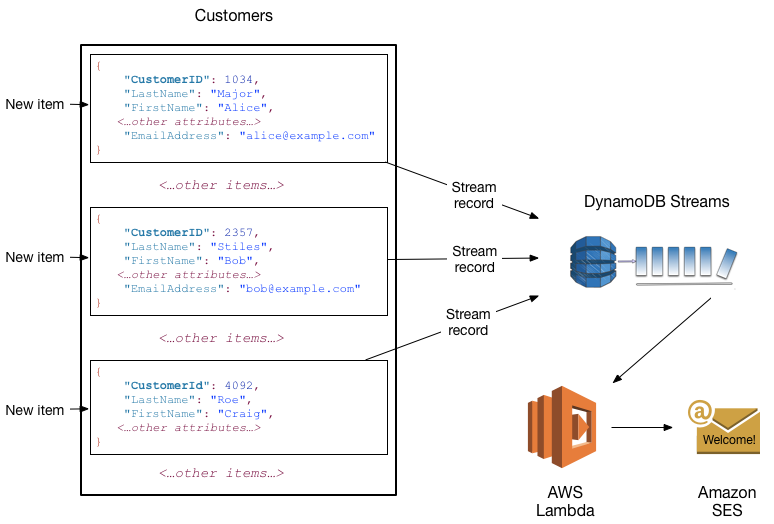
DynamoDB Streams を AWS Lambda と共に使用して、トリガーを作成できます。トリガーは、対象イベントがストリーミングに表示されるたびに自動的に実行されます。たとえば、会社の顧客情報を含む Customers テーブルがあるとします。新規の各顧客に、「ようこそ」 E メールを送信するとします。そのテーブルでストリーミングを有効にし、そのストリーミングを Lambda 関数に関連付けます。Lambda 関数は、新しいストリーミングレコードが表示されるたびに実行されますが、Customers テーブルに追加された新しい項目のみを処理します。EmailAddress 属性を持つ項目について、Lambda 関数は Amazon Simple Email Service (Amazon SES) をコールしてそのアドレスに E メールを送信します。
注記
この例で、最後の顧客 Craig Roe には EmailAddress がないため E メールを受信することはありません。
トリガーに加えて、DynamoDB Streams は AWS リージョン内全体のデータレプリケーション、DynamoDB テーブル内のデータのマテリアライズドビュー、Kinesis のマテリアライズドビューを使用したデータ分析など、数多くの強力なソリューションを可能にします。
詳細については、「DynamoDB Streams の変更データキャプチャ」を参照してください。
