# DynamoDB のマテリアライズされた集計クエリでグローバルセカンダリインデックスを使用する
急速に変化するデータ上で、ほぼリアルタイムの集約や主要メトリクスを維持することは、企業が意思決定を迅速に行う上で、ますます価値が高まりつつあります。例えば、音楽ライブラリでは最もダウンロードされた曲をほぼリアルタイムで紹介したい場合や、e コマースプラットフォームではトレンド商品をカテゴリ別に表示する必要がある場合があります。
DynamoDB は項目間の `SUM` や `COUNT` などの集計オペレーションをネイティブにサポートしていないため、読み取り時にこれらの値を計算するには、多数の項目をスキャンする必要があり、時間がかかり、コストがかかる場合があります。代わりに、データ変更時に集計を*事前計算*し、結果を通常の項目としてテーブルに保存できます。このパターンは*マテリアライズされた集計*と呼ばれます。
**Topics**
+ [シナリオとアクセスパターンの例](#bp-gsi-aggregation-scenario)
+ [事前計算された集計を行う理由](#bp-gsi-aggregation-why)
+ [テーブル設計](#bp-gsi-aggregation-table-design)
+ [Streams と AWS Lambda を使用した集約パイプライン](#bp-gsi-aggregation-pipeline)
+ [スパース GSI 設計](#bp-gsi-aggregation-sparse-gsi)
+ [GSI のクエリ](#bp-gsi-aggregation-querying)
+ [考慮事項](#bp-gsi-aggregation-considerations)
## シナリオとアクセスパターンの例
以下の要件を満たす音楽ライブラリアプリケーションを検討してください。
+ アプリケーションは、個々の曲のダウンロードを大容量 (1 秒あたり数千件) で記録します。
+ ユーザーは、特定の月の最もダウンロードされた曲を 1 桁ミリ秒のレイテンシーで確認する必要があります。
+ アプリケーションは、「今月の上位 10 曲」や「特定の月にダウンロードされたすべての曲」などのクエリもサポートする必要があります。
すべてのダウンロードレコードをスキャンして読み取り時にダウンロード数を計算すると、この規模ではコストがかかる場合があります。代わりに、ダウンロードが発生するたびに更新する実行中のカウントを維持し、効率的なクエリをサポートする方法で保存できます。
## 事前計算された集計を行う理由
集計を計算するには、いくつかのアプローチがあります。次の表は、一般的な代替案を比較し、DynamoDB でのマテリアライズされた集計がこのタイプのユースケースに最適であることが多い理由を示しています。
| アプローチ | トレードオフ | どのようなときに使うか |
| --- | --- | --- |
| 読み取り時のスキャンとカウント | クエリごとにすべてのダウンロードレコードを読み取る必要があります。レイテンシーはデータ量とともに増加し、大量の読み取り容量を消費します。 | レイテンシーが懸念されない非常に小さなデータセットにのみ適しています。 |
| 外部集約ストア (Amazon ElastiCache など) | 管理する別のサービスにより運用が複雑になります。DynamoDB とキャッシュ間の同期ロジックが必要です。 | 1 ミリ秒未満の読み取りや、単純なカウントを超えた複雑な集約ロジックが必要な場合。 |
| 書き込み時のアプリケーションレベルの集約 | 集約ロジックを書き込みパスに結合します。ダウンロードを記録した後、カウントを更新する前にアプリケーションが失敗すると、集約が不整合になります。 | 同期的で強力な整合性のある集約が必要であり、追加の書き込みレイテンシーを許容できる場合。 |
| Streams と Lambda を使用したマテリアライズされた集計 | 書き込みパスから集計を切り離します。集計は結果整合性があります (通常は数秒遅れます)。Lambda 呼び出しコストを追加します。 | 読み取りレイテンシーが低く、結果整合性を許容できるほぼリアルタイムの集計が必要な場合。これがこのページで説明されているアプローチです。 |
マテリアライズされた集計アプローチは、書き込みパスをシンプルに保ち (ダウンロードを記録するだけで)、集約を非同期プロセスにオフロードし、結果を DynamoDB に保存して、1 桁ミリ秒のレイテンシーでクエリできるようにします。
## テーブル設計
この設計では、同じパーティションキー (`songID`) を共有する 2 つの項目タイプを持つ単一のテーブルを使用しますが、異なるソートキーパターンを使用してそれらを区別します。
+ **ダウンロードレコード** – 個々のダウンロードイベント。ソートキーは `DownloadID` (ダウンロードごとに一意の識別子) です。
+ **毎月の集計項目** – 1 曲あたり 1 か月あたりのダウンロード数を事前計算します。ソートキーは、`YYYY-MM` 形式の月です (例: `2018-01`)。これらの項目には、累計を示す `DownloadCount` 属性も含まれます。
`Month` 属性を含むのは、毎月の集計項目のみです。この区別は、後で説明するスパース GSI 設計にとって重要です。
次の図は、両方の項目タイプを含むテーブルレイアウトを示しています。
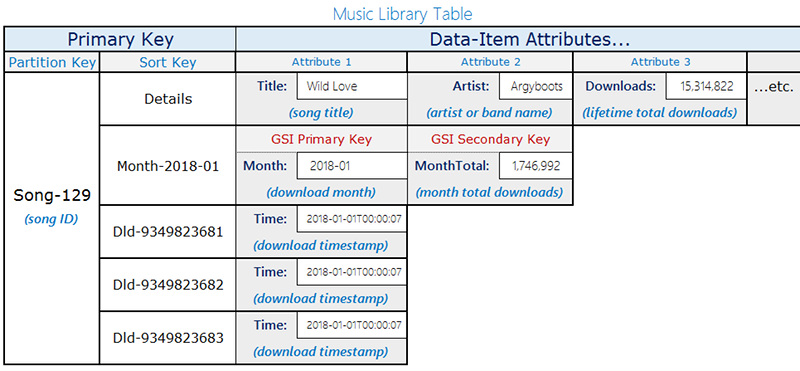
| 項目タイプ | パーティションキー (songID) | ソートキー | その他の属性 |
| --- | --- | --- | --- |
| ダウンロードレコード | song1 | download-abc123 | UserID, Timestamp |
| 毎月の集計 | song1 | 2018-01 | Month=2018-01, DownloadCount=1,746,992 |
## Streams と AWS Lambda を使用した集約パイプライン
集約パイプラインは次のように機能します。
1. 曲がダウンロードされると、アプリケーションは `Partition-Key=songID` と `Sort-Key=DownloadID` を使用してテーブルに新しい項目を書き込みます。
1. DynamoDB Streams は、この書き込みをストリームレコードとしてキャプチャします。
1. ストリームにアタッチされた Lambda 関数は、新しいレコードを処理します。`songID` と現在の月を識別し、`DownloadCount` 属性を増分して対応する毎月の集計項目を更新します。
1. 更新された集計項目は、スパース GSI を介したクエリに使用できます。
Lambda 関数は、`ADD` 式を使用した `UpdateItem` 呼び出しを使用して、ダウンロード数をアトミックに増分します。これにより、読み取り/変更/書き込みの競合状態を回避できます。
```
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('MusicLibrary')
def handler(event, context):
for record in event['Records']:
if record['eventName'] == 'INSERT':
new_image = record['dynamodb']['NewImage']
song_id = new_image['songID']['S']
# Derive the month from the download timestamp
timestamp = new_image['Timestamp']['S']
month = timestamp[:7] # Extract YYYY-MM
table.update_item(
Key={
'songID': song_id,
'SK': month
},
UpdateExpression='ADD DownloadCount :inc SET #m = :month',
ExpressionAttributeNames={
'#m': 'Month'
},
ExpressionAttributeValues={
':inc': 1,
':month': month
}
)
```
**注記**
更新された集計値を書き込んだ後に Lambda の実行が失敗した場合、ストリームレコードが再試行される可能性があります。`ADD` オペレーションを実行するたびにカウントが増分されるため、再試行すると同じダウンロードに対してカウントが複数回増分され、*おおよそ*の値が返されます。ほとんどの分析とリーダーボードのユースケースでは、このわずかな誤差は許容範囲です。正確なカウントが必要な場合は、べき等性ロジックを追加することを検討してください。例えば、特定の `DownloadID` が既に処理されているかどうかをチェックする条件式を使用します。
## スパース GSI 設計
集計結果を効率的にクエリするには、次のキースキーマを使用してグローバルセカンダリインデックスを作成します。
+ **GSI パーティションキー:** `Month` (文字列)
+ **GSI ソートキー:** `DownloadCount` (数値)
毎月の集計項目にのみ `Month` 属性が含まれているため、この GSI は*スパース*です。個々のダウンロードレコードにはこの属性がないため、自動的にインデックスから除外されます。つまり、GSI には事前に計算された集計項目のみが含まれます。これは、テーブル内の合計項目のごく一部です。
スパース GSI には 2 つの主な利点があります。
+ **コストの削減** – 集計項目のみがインデックスにレプリケートされるため、テーブル内のすべての項目を含むインデックスと比較して、書き込み容量とストレージの消費がはるかに少なくなります。
+ **クエリの高速化** – インデックスにはクエリが必要なデータのみが含まれているため、読み取りは効率的で、1 桁ミリ秒のレイテンシーで結果を返します。
スパースインデックスの動作の詳細については、「[スパースインデックスの利用](bp-indexes-general-sparse-indexes.md)」を参照してください。
## GSI のクエリ
スパース GSI を使用すると、いくつかのタイプのクエリに効率的に回答できます。
**特定の月に最もダウンロードされた曲を取得します。**
```
aws dynamodb query \
--table-name "MusicLibrary" \
--index-name "MonthDownloadsIndex" \
--key-condition-expression "#m = :month" \
--expression-attribute-names '{"#m": "Month"}' \
--expression-attribute-values '{":month": {"S": "2018-01"}}' \
--scan-index-forward false \
--limit 1
```
`ScanIndexForward` を `false` に設定すると、結果が `DownloadCount` で降順にソートされ、`Limit=1` は先頭の曲のみを返します。
**特定の月の上位 10 曲を取得します。**
```
aws dynamodb query \
--table-name "MusicLibrary" \
--index-name "MonthDownloadsIndex" \
--key-condition-expression "#m = :month" \
--expression-attribute-names '{"#m": "Month"}' \
--expression-attribute-values '{":month": {"S": "2018-01"}}' \
--scan-index-forward false \
--limit 10
```
**特定の月にダウンロードされたすべての曲を取得します** (ダウンロード数でソート)。
```
aws dynamodb query \
--table-name "MusicLibrary" \
--index-name "MonthDownloadsIndex" \
--key-condition-expression "#m = :month" \
--expression-attribute-names '{"#m": "Month"}' \
--expression-attribute-values '{":month": {"S": "2018-01"}}' \
--scan-index-forward false
```
## 考慮事項
このパターンを実装するときは、次の点に注意してください。
+ **結果整合性** – 集約値は DynamoDB Streams と Lambda を介して非同期的に更新されます。通常、ダウンロードが記録されてから集計が更新されるまでに数秒の遅延があります。つまり、GSI はリアルタイムデータではなく、ほぼリアルタイムのデータを反映します。
+ **Lambda の同時実行** – テーブルの書き込みボリュームが大きい場合、複数の Lambda 呼び出しが同じ集計項目を同時に更新しようとすることがあります。アトミック `ADD` オペレーションはこれを安全に処理しますが、関数がストリームに対応できることを確認するために、Lambda の同時実行性とスロットリングメトリクスをモニタリングする必要があります。
+ **GSI 書き込み容量** – スパース GSI には集計項目のみが含まれているため、必要な書き込み容量はベーステーブルよりも大幅に少なくなります。ただし、集約更新のレートを処理するのに十分な容量をプロビジョニング (またはオンデマンドモードを使用) する必要があります。
+ **おおよそのカウント** – 前述のように、Lambda の再試行により、カウントがわずかに多くカウントされる可能性があります。正確なカウントを必要とするユースケースの場合は、Lambda 関数にべき等性チェックを実装します。