リレーショナルデータベースから DynamoDB への移行
リレーショナルデータベースを DynamoDB に移行する際には、確実に成功させるための綿密な計画が必要です。このガイドでは、このプロセスの仕組み、利用できるツール、考えられる移行戦略を評価して要件に合うものを選択する方法を説明します。
トピック
DynamoDB に移行する理由
Amazon DynamoDB への移行は、企業や組織に幅広い魅力的なメリットをもたらします。データベースの移行先に DynamoDB を選択することで得られる主なメリットは次のとおりです。
-
スケーラビリティ: DynamoDB は、大量のワークロードを処理し、データ量とトラフィックの増加に合わせてシームレスにスケールできるように設計されています。DynamoDB を使用すると、需要に応じてデータベースを簡単にスケールアップまたはスケールダウンできるため、アプリケーションのパフォーマンスを損なうことなくトラフィックの急増に対応できます。
-
パフォーマンス: DynamoDB では低レイテンシーでのデータアクセスが可能であるため、並外れた速度でデータをアプリケーションに取得して処理できます。分散型アーキテクチャにより、読み取りと書き込みの操作が複数のノードに分散され、高いリクエストレートでも 1 桁ミリ秒単位の応答時間を一貫して実現できます。
-
フルマネージド: DynamoDB は、AWS が提供するフルマネージドサービスです。つまり、プロビジョニング、設定、パッチ適用、バックアップ、スケーリングなど、データベース管理の運用面は AWS が処理するということです。これにより、企業はデータベースの管理タスクよりもアプリケーションの開発に集中できます。
-
サーバーレスアーキテクチャ: DynamoDB は、DynamoDB オンデマンドと呼ばれるサーバーレスモデルをサポートしています。このモデルでは、事前にキャパシティをプロビジョニングすることなく、アプリケーションによって行われる実際の読み取りおよび書き込みリクエストに対してのみ料金が発生します。このリクエストベースの課金モデルでは、使用したリソースに対してのみ支払いを行うことになり、キャパシティのプロビジョニングや監視の必要がないため、コスト効率が向上し、運用上のオーバーヘッドも最小限に抑えられます。
-
NoSQL の柔軟性: 従来のリレーショナルデータベースとは異なり、DynamoDB は NoSQL データモデルを採用しているため、スキーマ設計に柔軟性があります。DynamoDB では、構造化データ、半構造化データ、非構造化データを保存でき、変化を続ける多様なデータ型の処理に最適です。この柔軟性により、開発サイクルが短縮され、変化するビジネス要件に容易に適応できます。
-
優れた可用性と耐久性: DynamoDB では、リージョン内の複数のアベイラビリティーゾーンにデータをレプリケーションして、優れた可用性とデータ耐久性を確保します。レプリケーション、フェイルオーバー、リカバリが自動的に処理されるため、データ損失やサービス中断のリスクが最小限に抑えられます。DynamoDB では、最大 99.999% の可用性 SLA が提供されています。
-
セキュリティとコンプライアンス: DynamoDB と AWS Identity and Access Management の統合によって、きめ細かいアクセスコントロールが実現します。保管中も転送中もデータを暗号化してセキュリティを確保します。また、DynamoDB は HIPAA、PCI DSS、GDPR などのさまざまなコンプライアンス標準に準拠しているため、規制要件も満たすことができます。
-
AWS エコシステムとの統合: DynamoDB は AWS エコシステムの一部として、AWS Lambda、CloudFormation、AWS AppSync などの他の AWS サービスとシームレスに統合します。この統合により、サーバーレスアーキテクチャの構築、Infrastructure as Code の活用、リアルタイムのデータ主導型アプリケーションの作成が可能になります。
リレーショナルデータベースを DynamoDB に移行する際の考慮事項
リレーショナルデータベースシステムと NoSQL データベースにはそれぞれ異なる長所と短所があります。これらの相違点により、2 つのシステム間でデータベース設計が異なるものになります。
| タスクの種類 | リレーショナルデータベース | NoSQL データベース |
|---|---|---|
| データベースのクエリ | リレーショナルデータベースでは、データは柔軟にクエリできますが、クエリは比較的コストが高く、トラフィックが多い状況ではスケールがうまくいかない場合があります (「DynamoDB でリレーショナルデータをモデル化するための最初のステップ」を参照)。リレーショナルデータベースアプリケーションでは、ストアドプロシージャ、SQL サブクエリ、一括更新クエリ、集計クエリにビジネスロジックを実装する場合があります。 | 一方、DynamoDB のような NoSQL データベースでは、データは限られた数の方法で効率的にクエリできますが、その範囲外では、クエリは高コストで低速になりがちです。DynamoDB への書き込みはシングルトンです。以前にストアドプロシージャで実行されていたアプリケーションのビジネスロジックは、Amazon EC2 や AWS Lambda などのホストで実行されるカスタムコードによって DynamoDB の外部で実行されるようにリファクタリングする必要があります。 |
| データベースの設計 | 実装の詳細やパフォーマンスを気にせずに柔軟に設計できます。クエリの最適化は一般的にスキーマ設計には影響しませんが、正規化は重要です。 | 最も一般的で重要なクエリをできるだけ速く、安価にするために、具体的にスキーマを設計します。データ構造は、ビジネスユースケースの特定の要件に合わせて調整されています。 |
NoSQL データベースの設計には、リレーショナルデータベース管理システム (RDBMS) の設計とは異なる考え方が必要です。RDBMS の場合は、アクセスパターンを考慮せずに正規化されたデータモデルを作成できます。その後、新しい課題とクエリの要件が発生したら、そのデータモデルを拡張することができます。各タイプのデータを独自のテーブルに整理できます。
NoSQL の設計では、回答すべき質問が判明したら、DynamoDB のスキーマを設計できます。ビジネス上の問題とアプリケーションの読み取り/書き込みパターンを理解することが不可欠です。さらに、DynamoDB アプリケーションで維持するテーブルをできるだけ少なくする必要もあります。テーブルの数が少なくなると、スケーラビリティが向上し、必要なアクセス権限の管理が少なくなり、DynamoDB アプリケーションのオーバーヘッドが削減されます。また、バックアップコストを全体的に低く抑えるのにも役立ちます。
DynamoDB のリレーショナルデータをモデル化し、フロントエンドアプリケーションの新しいバージョンを構築するタスクについては、別のトピックで説明します。このガイドは、DynamoDB を使用するために構築された新しいバージョンのアプリケーションがあることを前提としていますが、カットオーバー中に履歴データを移行して同期する最適な方法を決定する必要はあります。
サイズに関する考慮事項
DynamoDB テーブルに格納する各項目 (行) の最大サイズは 400 KB です。詳細については、「Amazon DynamoDB のクォータ」を参照してください。項目のサイズは、項目のすべての属性名と属性値の合計サイズによって決まります。詳細については、「DynamoDB 項目のサイズと形式」を参照してください。
アプリケーションで DynamoDB のサイズ制限よりも多くのデータを格納する必要がある場合は、項目を項目コレクションに分割するか、項目データを圧縮するか、項目をオブジェクトとして Amazon Simple Storage Service (Amazon S3) に格納して Amazon S3 オブジェクト識別子を DynamoDB 項目に格納します。「DynamoDB で大きな項目と属性を格納するベストプラクティス」を参照してください。項目の更新にかかるコストは、項目のフルサイズに基づいて決まります。既存の項目を頻繁に更新する必要があるワークロードでは、1 ~ 2 KB の小さい項目の方が、大きい項目よりも更新にかかるコストが低くなります。項目コレクションの詳細については、「項目コレクション - DynamoDB で一対多リレーションシップをモデル化する方法」を参照してください。
パーティションとソートキーの属性、その他のテーブル設定、項目のサイズと構造、およびセカンダリインデックスを作成するかどうかを選択するときは、必ず DynamoDB のモデリングに関するドキュメントと「DynamoDB テーブルのコストの最適化」のガイドを確認してください。DynamoDB の機能と制限の範囲内でコスト効率よく DynamoDB ソリューションを運用できるように、移行計画を必ずテストしてください。
DynamoDB への移行の仕組みを理解する
利用可能な移行ツールを確認する前に、DynamoDB による書き込みの処理方法を検討してください。
デフォルトの最も一般的な書き込み操作は、単一の PutItem API オペレーションです。ループ内で PutItem オペレーションを実行してデータセットを処理できます。DynamoDB は実質的に無制限の同時接続をサポートしているため、MapReduce や Spark などの大規模なマルチスレッドのロードルーチンを設定して実行できると仮定すると、書き込み速度はターゲットテーブルのキャパシティ (これも通常は無制限) によってのみ制限されます。
DynamoDB にデータをロードするときは、ローダーの書き込み速度を把握することが重要です。ロードする項目 (行) のサイズが 1 KB 以下の場合、この速度は単に 1 秒あたりの項目数となります。これで、この速度を処理するのに十分な WCU (書き込みキャパシティユニット) をターゲットテーブルにプロビジョニングできます。ローダーがプロビジョニングされたキャパシティを 1 秒でも超えた場合、追加のリクエストはスロットリングされるか、完全に拒否される可能性があります。スロットリングは、DynamoDB コンソールの [モニタリング] タブにある CloudWatch チャートで確認できます。
2 つ目のオペレーションは、BatchWriteItem という関連 API を使用して実行できます。BatchWriteItem では、最大 25 件の書き込みリクエストを 1 つの API コールにまとめることができます。これらはサービスによって受信され、テーブルへの個別の PutItem リクエストとして処理されます。現在、BatchWriteItem を選択すると、PutItem によるシングルトン呼び出し時に、AWS SDK に備わっている自動再試行のメリットを享受できません。そのため、エラー (スロットリング例外など) が発生した場合は、BatchWriteItem への応答呼び出しで失敗した書き込みのリストを探す必要があります。CloudWatch スロットリングチャートで警告が検出された場合のスロットリング警告の処理については、「Amazon DynamoDB でのスロットリングのトラブルシューティング」を参照してください。
3 つ目のタイプのデータインポートには、DynamoDB の S3 からのインポート機能PutItem と同様に、アップストリームプロセスが必要であり、選択した形式でデータを Amazon S3 バケットに書き込みます。
DynamoDB への移行に役立つツール
データを DynamoDB に移行するために使用できる一般的な移行ツールと ETL ツールがいくつかあります。
Amazon は、AWS Database Migration Service (DMS)、AWS Glue、Amazon EMR、Amazon Managed Streaming for Apache Kafka など、移行に使用できるデータツールを多数提供しています。これらのツールはすべてダウンタイム移行に使用可能であり、リレーショナルデータベースの変更データキャプチャ (CDC) 機能を活用してオンライン移行をサポートできます。ツールを選択する場合は、組織が各ツールに関して持っているスキルセットと経験と共に、各ツールの機能、パフォーマンス、コストを考慮することが役立ちます。
多くのお客様は、移行プロセス用のカスタムデータ変換を構築するために、独自の移行スクリプトとジョブを作成することを選択しています。大量の書き込みトラフィックや定期的な大規模一括ロードジョブを伴う大容量の DynamoDB テーブルを運用する予定がある場合は、書き込みトラフィックが多いときの DynamoDB の動作に詳しくなるために、移行コードを自分で書くこともできます。スロットリング処理や効率的なテーブルプロビジョニングなどのシナリオは、プロジェクトの早い段階で実際に移行を行う際に経験できます。
DynamoDB に移行するための適切な戦略の選択
大規模なリレーショナルデータベースアプリケーションは、100 以上のテーブルを使用し、複数の異なるアプリケーション機能をサポートしている場合があります。大規模な移行を行う場合は、アプリケーションを小さなコンポーネントまたはマイクロサービスに分割して、テーブルの小さなセットを一度に移行することを検討してください。その後、追加のコンポーネントを段階的に DynamoDB に移行できます。
移行戦略を選択する際、さまざまな要因に基づいて 1 つのソリューションを決定する場合があります。以下のオプションをデシジョンツリーで表すことで、組織の要件とリソースに応じて利用可能なオプションを簡単に示すことができます。ここでは、概念について簡単に説明します (詳細はこのガイドの後半で説明します)。
| If | And | THEN |
|---|---|---|
| データ移行を実行するために、メンテナンスウィンドウ中にアプリケーションをしばらく停止してもかまわない場合。これはオフライン移行です。 |
AWS DMS でフルロードタスクを使用してオフライン移行を実行してください。必要に応じて、SQL の |
|
| 移行時に、アプリケーションを読み取り専用モードで実行できればよいという場合。これはハイブリッド移行です。 | アプリケーションまたはソースデータベース内での書き込みを無効にします。AWS DMS でフルロードタスクを使用してオフライン移行を実行してください。 | |
| 移行時に、アプリケーションで更新や削除ができなくても、読み取りや新規レコードの挿入ができればよいという場合。これはハイブリッド移行です。 | アプリケーション開発スキルがあり、すべての新しいレコードについて DynamoDB への書き込みを含む二重書き込みを実行するために、既存のリレーショナルアプリを更新できる場合。 | AWS DMS でフルロードタスクを使用してオフライン移行を実行してください。同時に、既存のアプリを読み取りと二重書き込みが可能なバージョンにしてデプロイします。 |
| ダウンタイムを最小限に抑えて移行する必要がある場合。これはオンライン移行です。 |
|
AWS DMS でオンラインデータ移行を実行してください。一括ロードタスクを実行し、続いて CDC 同期タスクを実行します。 |
| ダウンタイムを最小限に抑えて移行する必要がある場合。これはオンライン移行です。 |
|
SQL データベース内に NoSQL 対応テーブルを作成してください。JOIN、UNION、VIEW、トリガー、ストアドプロシージャを使用してデータの入力と同期を行います。 |
| ダウンタイムを最小限に抑えて移行する必要がある場合。これはオンライン移行です。 |
|
ハイブリッドまたはオフラインの移行アプローチを検討してください。 |
| ダウンタイムを最小限に抑えて移行する必要がある場合。これはオンライン移行です。 | 過去のトランザクションデータの移行は省略しても問題ない、または移行の代わりに Amazon S3 にアーカイブしてもよい場合。いくつかの小さな静的テーブルを移行するだけでよい場合。 | スクリプトを記述するか、任意の ETL ツールを使用してテーブルを移行してください。必要に応じて、SQL の VIEW でソースデータを事前に形成します。 |
DynamoDB へのオフライン移行を実行する
オフライン移行は、移行時にダウンタイムを許容できる場合に適しています。リレーショナルデータベースは通常、メンテナンスとパッチ適用のために毎月少なくともある程度のダウンタイムを必要とし、ハードウェアのアップグレードやメジャーリリースのアップグレードではダウンタイムがさらに長くなることもあります。
Amazon S3 は移行時のステージングエリアとして使用できます。CSV (カンマ区切り値) または DynamoDB JSON 形式で保存されたデータは、DynamoDB の S3 からのインポート機能を使用して新しい DynamoDB テーブルに自動的にインポートできます。
独自の NoSQL アクセスパターンを活用するために複数のテーブルを結合することが望ましい場合があります (4 つのレガシーテーブルを 1 つの DynamoDB テーブルに変換するなど)。通常、単一のキーと値のドキュメントに対するリクエスト、または事前にグループ化された項目コレクションに対するクエリは、複数テーブルの結合を実行する SQL データベースよりもレイテンシーが短くなります。ただし、これによって移行タスクはより困難になります。SQL ビューを使ってソースデータベース内で処理を行い、4 つのテーブルすべてを 1 つにまとめた単一のデータセットを作成することもできます。
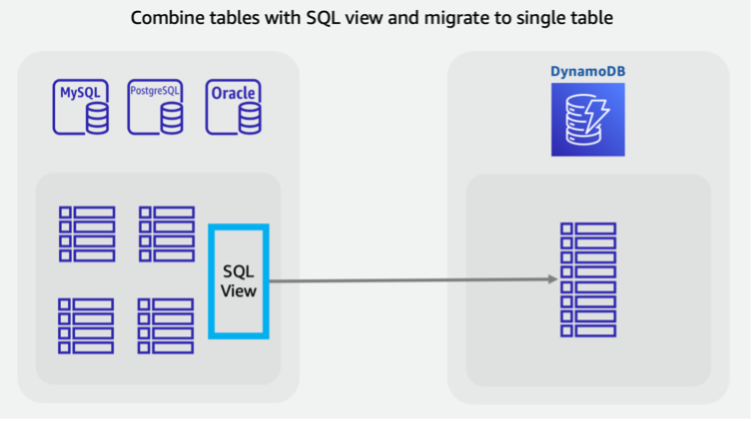
このビューでは、テーブルを非正規化されたテーブルに JOIN することも、SQL の UNION を使用してエンティティを正規化されたままでテーブルをスタックすることもできます。リレーショナルデータの再形成に関する重要な決定事項については、こちらのビデオ
プラン
Amazon S3 を使用してオフライン移行を実行する
ツール
-
SQL データを抽出して変換し、そのデータを S3 バケットに保存する次のような ETL ジョブ
-
AWS Database Migration Service は、履歴データを一括ロードし、変更データキャプチャ (CDC) レコードを処理してソーステーブルとターゲットテーブルを同期できるサービスです。
-
AWS Glue
-
Amazon EMR
-
独自のカスタムコード
-
-
DynamoDB の S3 からのインポート機能
オフライン移行ステップ
-
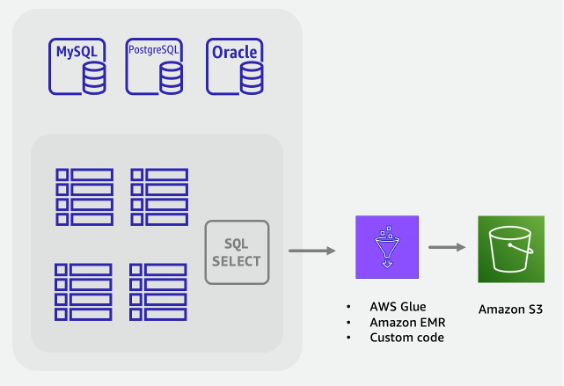
SQL データベースにクエリを実行し、テーブルデータを DynamoDB JSON または CSV 形式に変換して、S3 バケットに保存する ETL ジョブを構築します。
-
DynamoDB の S3 からのインポート機能が呼び出され、新しいテーブルを作成して、S3 バケットからデータを自動的にロードします。
完全なオフライン移行はシンプルで簡単ですが、アプリケーションの所有者やユーザーにはおそらくあまり好まれません。移行時にアプリケーションのサービスがまったく提供されないのではなく、提供するサービスのレベルが下がるだけであれば、ユーザーも助かるでしょう。
オフライン移行時に書き込みだけを無効にして、読み取りは通常どおり継続できるようにする機能を追加できます。こうすることで、アプリケーションのユーザーは、リレーショナルデータの移行中でも既存のデータを安全に参照してクエリを実行できます。この方法が適している場合は、引き続きハイブリッド移行についてお読みください。
DynamoDB へのハイブリッド移行を実行する
読み取りおよび書き込み操作はどのデータベースアプリケーションでも実行されますが、ハイブリッド移行またはオンライン移行を計画する際には、実行される書き込み操作の種類を考慮する必要があります。データベースへの書き込みは、挿入、更新、削除の 3 つのバケットに分類できます。アプリケーションによっては、削除をすぐに処理する必要がない場合があります。これらのアプリケーションは、削除を月末などの一括クリーンアッププロセスに延期できます。こうした種類のアプリケーションは、部分的な稼働時間を確保しながら、より簡単に移行できます。
計画
アプリケーションの二重書き込みによるオンライン/オフラインのハイブリッド移行を実行する
ツール
-
SQL データを抽出して変換し、そのデータを S3 バケットに保存する次のような ETL ジョブ
-
AWS DMS
-
AWS Glue
-
Amazon EMR
-
独自のカスタムコード
-
ハイブリッド移行ステップ
-
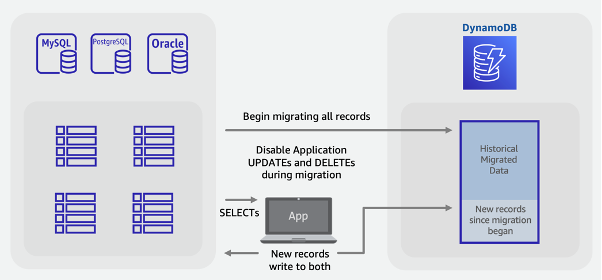
ターゲットの DynamoDB テーブルを作成します。このテーブルには、過去のバルクデータと新しいライブデータの両方が格納されます。
-
レガシーアプリケーションで削除と更新を無効にし、すべての挿入が SQL データベースと DynamoDB の両方への二重書き込みとして実行されるようにして、新しいバージョンのアプリケーションを作成します。
-
ETL ジョブまたは AWS DMS タスクを開始して、既存のデータをバックフィルすると同時に、新しいバージョンのアプリケーションをデプロイします。
-
バックフィルジョブが完了すると、DynamoDB には既存のレコードと新しいレコードがすべて揃い、アプリケーションのカットオーバーの準備が整います。
注記
バックフィルジョブでは SQL から DynamoDB に直接書き込みが行われます。オフライン移行の例のように S3 インポート機能を使用することはできません。この機能で作成される新しいテーブルは、DynamoDB がデータをロードするまで有効にならないためです。
各テーブルを 1 対 1 で移行して DynamoDB へのオンライン移行を実行する
多くのリレーショナルデータベースには、変更データキャプチャ (CDC) と呼ばれる機能があり、ユーザーは特定の時点より前または後にテーブルに加えられた変更のリストをリクエストできます。CDC は内部ログを使用してこの機能を有効にするため、テーブルにタイムスタンプ列がなくても動作します。
SQL テーブルのスキーマを NoSQL データベースに移行する際、データを結合して再形成し、テーブルの数を減らすことができます。そうすることで、データを 1 か所に集めることができ、複数ステップの読み取り操作において関連データを手動で結合する必要がなくなります。ただし、単一テーブルのデータ形成は必ずしも必要ではなく、テーブルを 1 対 1 で DynamoDB に移行することもあります。こうした 1 対 1 のテーブル移行は、この種の移行をサポートする一般的な ETL ツールを使ってソースデータベースの CDC 機能を活用すれば、それほど複雑ではありません。各行のデータは新しい形式に変換することも可能ですが、各テーブルの範囲は変わりません。
SQL テーブルを 1 対 1 で DynamoDB に移行することを検討する場合は、DynamoDB がサーバー側の結合をサポートしないという点に注意してください。複数のテーブルのデータを組み合わせるには、アプリケーションにロジックを追加する必要があります。
計画
AWS DMS を使用して各テーブルの DynamoDB へのオンライン移行を実行する
ツール
オンライン移行ステップ
-
ソーススキーマ内の移行するテーブルを特定します。
-
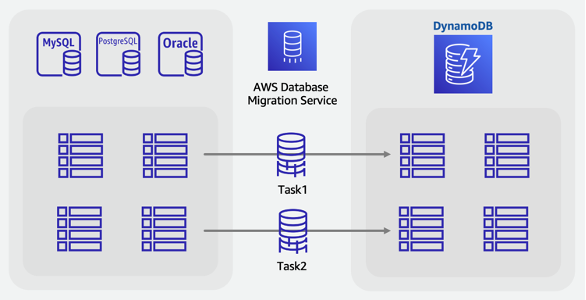
ソースと同じキー構造で同数のテーブルを DynamoDB で作成します。
-
AWS DMS にレプリケーションサーバーを作成し、ソースとターゲットのエンドポイントを設定します。
-
行ごとの必要な変換 (連結列、日付の ISO-8601 文字列形式への変換など) を定義します。
-
[フルロードと変更データキャプチャ (CDC)] で、テーブルごとに移行タスクを作成します。
-
レプリケーションフェーズの処理が始まるまで、これらのタスクを監視します。
-
この時点で、検証監査をすべて実行すれば、DynamoDB へ読み取りと書き込みを行うアプリケーションにユーザーを切り替えることができます。
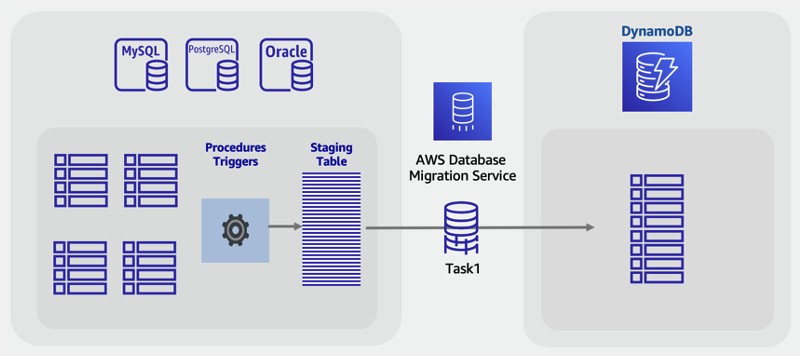
カスタムステージングテーブルを使用して DynamoDB へのオンライン移行を実行する
上のオフライン移行シナリオと同様に、独自の NoSQL アクセスパターンを活用するためにテーブルを結合することを選択できます (4 つのレガシーテーブルを 1 つの DynamoDB テーブルに変換するなど)。SQL の VIEW を使ってソースデータベース内で処理を行い、4 つのテーブルすべてを 1 つにまとめた単一のデータセットを作成することもできます。
ただし、変化するライブデータを伴うオンライン移行では、CDC 機能は活用できません。VIEW 内ではサポートされないためです。テーブルに最終更新日時のタイムスタンプ列があり、その列が VIEW に組み込まれている場合は、その列を使用して同期による一括ロードを実行するカスタム ETL ジョブを構築できます。
この課題に対する新しいアプローチとしては、ビュー、ストアドプロシージャ、トリガーといった標準の SQL 機能を使用して、最終的に必要な DynamoDB NoSQL 形式で新しい SQL テーブルを作成します。
データベースサーバーに予備の容量がある場合は、移行の開始前に、この単一のステージングテーブルを作成できます。そのためには、既存のテーブルからの読み取り、必要に応じたデータ変換、新しいステージングテーブルへの書き込みを行うストアドプロシージャを作成します。テーブルの変更をステージングテーブルにリアルタイムで複製するための一連のトリガーを追加できます。会社のポリシーでトリガーが許可されていない場合は、ストアドプロシージャを変更しても同様の結果が得られる可能性があります。データを書き込むプロシージャに数行のコードを加え、同じ変更をステージングテーブルに追加で書き込みます。
このステージングテーブルをレガシーアプリケーションテーブルと完全に同期された場所に置いておくと、ライブ移行の出発点として最適です。このテーブルでは、AWS DMS など、データベース CDC を使ってライブ移行を実行するツールが使用できるようになっています。この方法のメリットは、リレーショナルデータベースエンジンで利用可能なよく知られた SQL スキルと機能を使用できることです。
計画
AWS DMS と SQL ステージングテーブルを使用してオンライン移行を実行する
ツール
-
カスタム SQL ストアドプロシージャまたはトリガー
オンライン移行ステップ
-
ソースのリレーショナルデータベースエンジン内に、予備のディスク容量と処理容量がある程度あることを確認します。
-
タイムスタンプまたは CDC 機能を有効にして、SQL データベースに新しいステージングテーブルを作成します。
-
ストアドプロシージャを記述して実行し、既存のリレーショナルテーブルデータをステージングテーブルにコピーします。
-
トリガーをデプロイするか、既存のプロシージャを変更して、既存のテーブルに通常の書き込みを実行しながら新しいステージングテーブルに二重書き込みが行われるようにします。
-
AWS DMS を実行して、このソーステーブルをターゲットの DynamoDB テーブルに移行して同期します。
このガイドでは、ダウンタイムを最小限に抑えることと、一般的なデータベースツールや手法を使用することに重点を置いて、リレーショナルデータベースのデータを DynamoDB に移行する際の考慮事項とアプローチをいくつか紹介しました。詳細については次を参照してください:
