Partitioning and aggregating data output from an Amazon AppFlow flow
When you use Amazon AppFlow to transfer data to Amazon S3 with a flow, you get the options to do the following:
-
Organize the output data into partitions
-
Aggregate the output records into files of a specified size
You can use these options to optimize query performance for applications that access the data.
Partitioning and aggregating flow output in Amazon AppFlow
To configure the partition and aggregation settings in the Amazon AppFlow console, perform the following steps.
Sign in to the AWS Management Console and open the Amazon AppFlow console at https://console.aws.amazon.com/appflow/
. -
To view the partition and aggregation settings, configure a flow that transfers data to Amazon S3. Do one of the following:
-
If you want to configure the output from a new flow, choose Create flow and step through the flow creation process.
When you get to the Configure flow page, under Destination details, set Destination name to Amazon S3.
Continue the flow creation process. You configure the partition and aggregation settings when you get to the Map data fields page.
-
If you want to configure the output from an existing flow, choose Flows in the navigation pane to view your flows. Then, select the flow and choose Edit.
On the Edit flow configuration page, under Destination details, ensure that Destination name is set to Amazon S3.
To configure the partition and aggregation settings, go to the Edit data fields page.
The console shows the settings under Partition and aggregation settings.

-
-
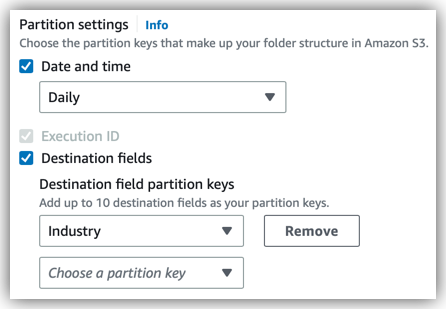
For Partition settings, choose any of the following partition keys:
-
Date and time – Represents the dates and times when your flow runs. You choose the precision (yearly, monthly, daily, and so on). The dates and times are shown in Coordinated Universal Time (UTC).
Each unit of time (such as the year, month, or day) becomes a folder in your output file path. This way, when you set the precision to daily, your path has folders for the years, months, and days when your flow runs. Those folders are nested in the path
year/month/day2022/11/28.If you choose the Date and time key, the Execution ID key is required and is selected automatically.
-
Execution ID – The ID that Amazon AppFlow assigns to the flow run. Your output file path in Amazon S3 includes a folder for the execution ID.
If you configured your flow to catalog the output, then the Data Catalog tables also include the execution ID in their names. For more information about cataloging flow output, see Cataloging the data output from an Amazon AppFlow flow.
-
Destination fields – The destination fields that you defined under Source to destination field mapping in the flow settings.
If you choose this option, you can then specify up to 10 fields as partition keys. For each field that you choose, output records that have matching field-value pairs (for example,
"BillingState" = "WA") are grouped together in the corresponding Amazon S3 folder.In your output file path, the destination field folders are nested in the order that you specify the partition keys. The folders have the path
partition key one=value/partition key two=value/partition key three=value
Tip
When you choose your partition keys, consider how they affect query performance for applications that access the data. For example, if you choose a granular partition key, such as
Account ID, you might create many folders, where each folder contains one or just a few records. In that case, you might experience processing delays that offset the benefit of partitioning. -
-
For Aggregation settings, choose how to aggregate your records into output files in each partition.
-
Don’t aggregate – Don't aggregate records into files of a specified size. The size of each output file is determined by one of the following:
-
The size of each input file
-
The page size of each API response in the data transfer operation
-
-
Aggregate all records into one file in each partition – Write your records to a single file.
-
Aggregate records into multiple files in each partition – Write your records to multiple files. For each file, Amazon AppFlow tries to achieve the target file size that you specify. The actual file sizes might differ from the target based on the number and size of the records that each file contains.
-
Example file paths for partitioned datasets
The following examples show how Amazon AppFlow imports source datasets and transfers them into partitioned datasets in Amazon S3.
Example file paths
In this example, Amazon AppFlow creates file paths in an S3 bucket when it runs a flow that you
configure with partition settings. The partitions in the following paths include schema versions,
a date, execution IDs, and the destination fields Account Rating and
Industry.
-
example-flow/-
schemaVersion_1/-
520225fa-0ffb-4c95-b5d1-a2a862081d27/-
Account Rating=Warm/ -
Account Rating=null/ -
Account Rating=Hot/ -
Account Rating=Cold/
-
-
-
schemaVersion_2/-
2022/-
11/-
10/-
267c0ad0-228f-4d25-96fe-0f975005fec6/-
Industry=Apparel/ -
Industry=Biotechnology/ -
Industry=Construction/ -
Industry=Consulting/ -
Industry=Education/ -
Industry=Electronics/ -
Industry=Energy/ -
Industry=Hospitality/ -
Industry=Transportation/
-
-
-
-
-
-
Example dataset
Amazon AppFlow creates the example file paths when a flow transfers a source dataset that resembles
the following example. The dataset contains customer account records from a Salesforce database.
Each record has fields called Account Rating and Industry.
Account Name |
Account Rating |
Industry |
|---|---|---|
Example1 |
Hot |
Apparel |
Example2 |
Warm |
Biotechnology |
Example3 |
Cold |
Construction |
Example4 |
Consulting |
|
Example5 |
Hot |
Education |
Example6 |
Warm |
Electronics |
Example7 |
Cold |
Energy |
Example8 |
Hospitality |
|
Example9 |
Hot |
Transportation |
Example flow configurations
The example file paths include two folders for schema version.
After
the flow is initially defined and run, Amazon AppFlow
creates
the folder schemaVersion_1/. The initial flow configuration includes the
following partition settings:
-
The Execution ID partition key is turned on.
-
The Destination fields partition key is turned on, and the field Account Rating is used as a key.

With this configuration, Amazon AppFlow organizes the output into datasets that contain records with
matching field-value pairs for the Account Rating field. Amazon AppFlow stores each of these
datasets in the corresponding folders, such as the folder Account
Rating=Warm/.
After the partition settings in the flow
are
edited and the flow is run again, Amazon AppFlow creates the folder
schemaVersion_2/. That revision set the following partition
settings:
-
The Date and time partition key is turned on, and the granularity is set to Daily.
-
The Destination fields partition key is turned on, and the field Industry is used as a key.
With this configuration, Amazon AppFlow organizes the output into filepaths for the year, month, and
day that the flow runs: 2022/11/10. Within that path, Amazon AppFlow organizes the
output into datasets that contain records with matching field-value pairs for the
Industry field. Amazon AppFlow stores each of these datasets in the corresponding folders,
such as the folder Industry=Apparel/.
