翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
リゾルバー
前のセクションでは、スキーマとデータソースのコンポーネントについて学びました。次に、スキーマとデータソースがどのように相互作用するかを説明する必要があります。すべてはリゾルバーから始まります。
リゾルバーは、サービスにリクエストが送信されたときに、そのフィールドのデータをどのように解決するかを処理するコード単位です。リゾルバーは、スキーマのタイプ内の特定のフィールドにアタッチされます。クエリ、ミューテーション、サブスクリプションフィールド操作の状態変更操作を実装するために最もよく使用されます。リゾルバーはクライアントのリクエストを処理し、結果を返します。結果はオブジェクトやスカラーのような出力タイプのグループでもかまいません。

リゾルバーランタイム
では AWS AppSync、まずリゾルバーのランタイムを指定する必要があります。リゾルバーランタイムは、リゾルバーが実行される環境を示します。また、リゾルバーが書き込まれる言語も指定します。 AWS AppSync 現在、 は APPSYNC_JS for JavaScript and Velocity Template Language (VTL) をサポートしています。JavaScript については「リゾルバーおよび関数の JavaScript runtime 機能」または VTL については「リゾルバーのマッピングテンプレートユーティリティーリファレンス」を参照してください。
リゾルバーの構造
コード的には、リゾルバーはいくつかの方法で構造化できます。ユニット リゾルバーと パイプライン リゾルバーがあります。
ユニットリゾルバー
ユニットリゾルバーは、データソースに対して実行される単一のリクエストハンドラーとレスポンスハンドラーを定義するコードで構成されています。リクエストハンドラーはコンテキストオブジェクトを引数として受け取り、データソースの呼び出しに使用されたリクエストペイロードを返します。レスポンスハンドラーは、実行されたリクエストの結果を含むペイロードをデータソースから受け取ります。レスポンスハンドラーは、ペイロードを GraphQL レスポンスに変換して GraphQL フィールドを解決します。

パイプラインリゾルバー
パイプラインリゾルバーを実装する場合、以下のような一般的な構造があります。
-
before step: クライアントからリクエストが送信されると、使用されているスキーマフィールド (通常はクエリ、ミューテーション、サブスクリプション) のリゾルバーにリクエストデータが渡されます。リゾルバーは before step ハンドラーを使用してリクエストデータの処理を開始します。これにより、データがリゾルバーを通過する前に一部の前処理操作を実行できます。
-
関数: before ステップが実行されると、リクエストは関数リストに渡されます。リストの最初の関数がデータソースに対して実行されます。関数は、独自のリクエストハンドラーとレスポンスハンドラーを含むリゾルバーのコードのサブセットです。リクエストハンドラーは、リクエストデータを取得し、データソースに対して操作を実行します。レスポンスハンドラーは、データソースのレスポンスを処理してからリストに戻します。関数が複数ある場合、リクエストデータはリスト内の次に実行される関数に送信されます。リスト内の関数は、開発者が定義した順序で連続して実行されます。すべての関数が実行されると、最終結果は後のステップに渡されます。
-
after step: after step は、GraphQL レスポンスに渡す前に、最終関数のレスポンスに対していくつかの最終オペレーションを実行できるハンドラー関数です。
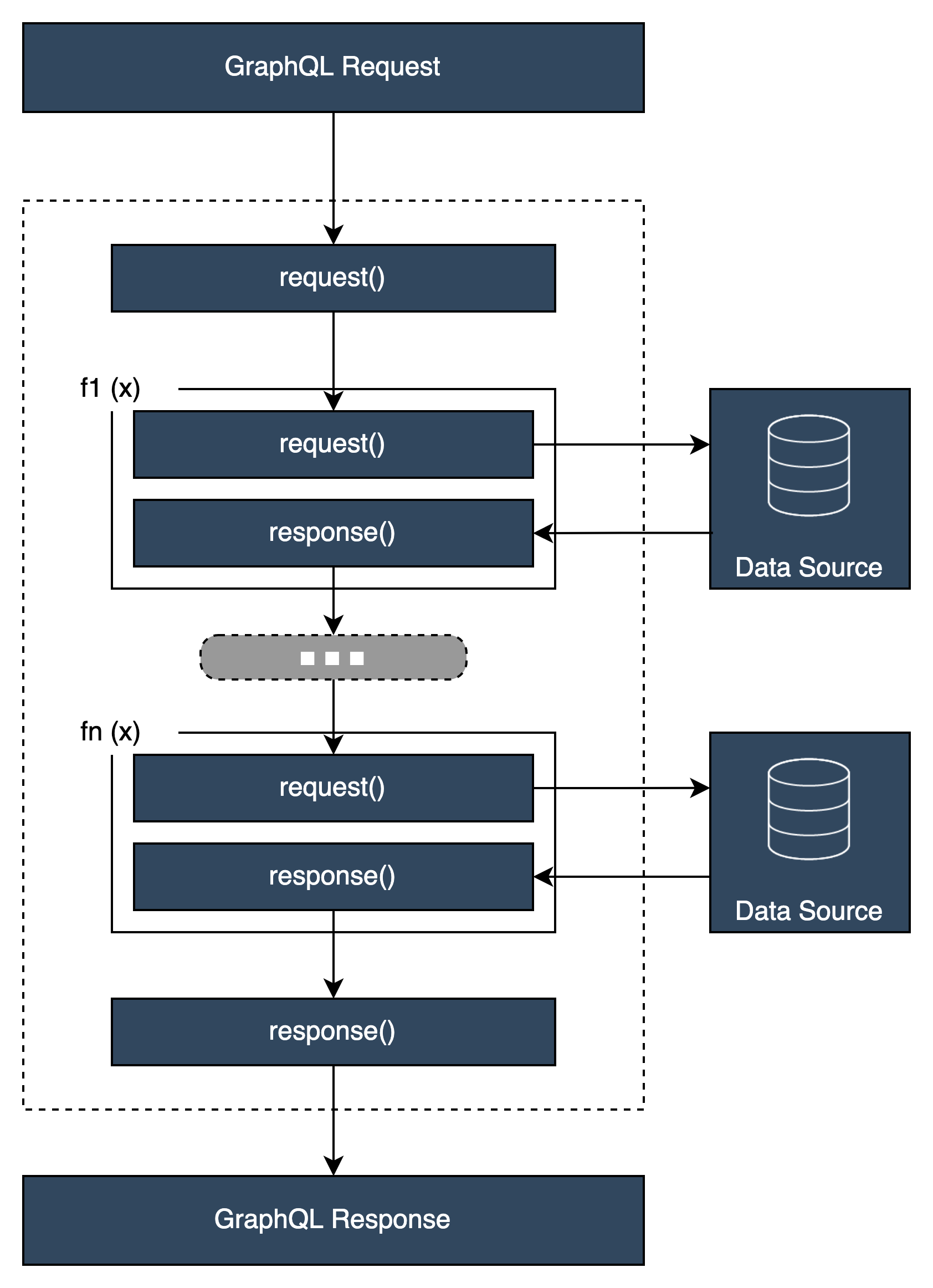
リゾルバーハンドラーの構造
ハンドラーは通常、Request および Response と呼ばれる関数です。
export function request(ctx) { // Code goes here } export function response(ctx) { // Code goes here }
ユニットリゾルバーには、これらの関数のセットは 1 つしかありません。パイプラインリゾルバーには、処理前と処理後のステップ用にこれらのセットが 1 つあり、関数ごとに追加のセットがあります。これがどのようになるかを視覚化するために、単純な Query タイプを見てみましょう。
type Query { helloWorld: String! }
これは String タイプの helloWorld というフィールドが 1 つある単純なクエリです。このフィールドには常に「Hello World」という文字列を返したいと仮定しましょう。この動作を実装するには、このフィールドにリゾルバーを追加する必要があります。ユニットリゾルバーには、次のようなものを追加できます。
export function request(ctx) { return {} } export function response(ctx) { return "Hello World" }
データをリクエストしたり処理したりしていないので、request は空欄のままでも構いません。データソースは None だと仮定することもできます。つまり、このコードでは呼び出しを実行する必要がないということです。レスポンスは単に「Hello World」を返します。このリゾルバーをテストするには、次のクエリータイプを使用してリクエストを行う必要があります。
query helloWorldTest { helloWorld }
これは helloWorld フィールドを返す helloWorldTest というクエリです。実行すると、helloWorld フィールドリゾルバーも実行され、レスポンスが返されます。
{ "data": { "helloWorld": "Hello World" } }
このような定数を返すのは一番簡単なことです。実際には、入力やリストなどを返すことになります。より複雑な例を次に示します。
type Book { id: ID! title: String } type Query { getBooks: [Book] }
ここでは、Books のリストを返しています。本のデータの保存に DynamoDB テーブルを使用していると仮定しましょう。ハンドラーは以下のようになります。
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
このリクエストでは、組み込みのスキャン操作を使用してテーブル内のすべてのエントリを検索し、結果をコンテキストに保存して、レスポンスに渡しました。レスポンスは結果項目を受け取り、レスポンスとして返しました。
{ "data": { "getBooks": { "items": [ { "id": "abcdefgh-1234-1234-1234-abcdefghijkl", "title": "book1" }, { "id": "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee", "title": "book2" }, ... ] } } }
リゾルバーのコンテキスト
リゾルバーでは、ハンドラーチェーンの各ステップが前のステップのデータの状態を認識している必要があります。あるハンドラーの結果を保存して、引数として別のハンドラーに渡すことができます。GraphQL は 4 つの基本的なリゾルバー引数を定義しています。
| リゾルバーベース引数 | 説明 |
|---|---|
obj root、parent、など |
親の結果です。 |
args |
GraphQL クエリのフィールドに提供される引数。 |
context |
すべてのリゾルバーに提供される値で、現在ログインしているユーザーやデータベースへのアクセスなどの重要なコンテキスト情報を保持します。 |
info |
スキーマの詳細だけでなく、現在のクエリに関連するフィールド固有の情報を保持する値です。 |
では AWS AppSync、 context (ctx) 引数は上記のすべてのデータを保持できます。これはリクエストごとに作成されるオブジェクトで、認可情報、結果データ、エラー、リクエストメタデータなどのデータを含みます。コンテキストを使うと、プログラマーはリクエストの他の部分からのデータを簡単に操作できます。このスニペットをもう一度見てみましょう。
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
リクエストにはコンテキスト (ctx) が引数として渡されます。これがリクエストの状態です。テーブル内のすべての項目をスキャンし、その結果を resultのコンテキスト内の結果を格納します。次に、コンテキストが応答引数に渡され、応答引数が result にアクセスしてその内容を返します。
リクエストとパーシング
GraphQL サービスにクエリを行う場合、実行前に解析と検証のプロセスを実行する必要があります。リクエストは解析され、抽象構文ツリーに変換されます。ツリーの内容は、スキーマに対して複数の検証アルゴリズムを実行することによって検証されます。検証ステップの後、ツリーのノードがトラバースされ、処理されます。リゾルバーが呼び出され、結果がコンテキストに保存され、レスポンスが返されます。例えば、次のクエリを指定するとします。
query { Person { //object type name //scalar age //scalar } }
戻り値は name および age フィールドとともに Person を返します。このクエリを実行すると、ツリーは次のようになります。

ツリーから見ると、このリクエストはスキーマ内の Query をルートで検索しているようです。クエリの内部では、Person フィールドが解決されます。前の例から、これはユーザーからの入力であったり、値のリストなどが、必要なフィールド (name と age) を保持するオブジェクトタイプに関連付けられている可能性が高いことがわかっています。Personこの 2 つの子フィールドが見つかると、指定された順序 (name の後に age が続く) で解決されます。ツリーが完全に解決されると、リクエストは完了し、クライアントに返送されます。
