Amazon Athena Timestream コネクタ
Amazon Athena Timestream コネクタにより、Amazon Athena で Amazon Timestream
Amazon Timestream は、高速でスケーラブルなフルマネージド型の専用時系列データベースで、1 日あたり何兆もの時系列データポイントの保存と分析を容易にします。Timestream は、最新のデータをメモリに保持し、履歴データをユーザー定義のポリシーに基づいてコスト最適化ストレージ階層に移動することで、時系列データのライフサイクル管理にかかる時間とコストを節約します。
アカウントで Lake Formation を有効にしている場合、AWS Serverless Application Repository でデプロイした Athena フェデレーション Lambda コネクタの IAM ロールには、Lake Formation での AWS Glue Data Catalog への読み取りアクセス権が必要です。
前提条件
Athena コンソールまたは AWS Serverless Application Repository を使用して AWS アカウント にコネクタをデプロイします。詳細については、「データソースコネクタをデプロイする」または「AWS Serverless Application Repository を使用してデータソースコネクタをデプロイする」を参照してください。
パラメータ
このセクションの Lambda 環境変数を使用して Timestream コネクタを設定します。
-
spill_bucket – Lambda 関数の上限を超えたデータに対して、Amazon S3 バケットを指定します。
-
spill_prefix – (オプション) 指定された
athena-federation-spillというspill_bucketの、デフォルトのサブフォルダに設定します。このロケーションで、Amazon S3 のストレージライフサイクルを設定し、あらかじめ決められた日数または時間数以上経過したスピルを削除することをお勧めします。 -
spill_put_request_headers – (オプション) スピリングに使用されるAmazon S3 の
putObjectリクエスト (例:{"x-amz-server-side-encryption" : "AES256"}) に関する、 JSON でエンコードされたリクエストヘッダーと値のマッピング。利用可能な他のヘッダーについては、「Amazon Simple Storage Service API リファレンス」の「PutObject」を参照してください。 -
kms_key_id – (オプション) デフォルトでは、Amazon S3 に送信されるすべてのデータは、AES-GCM で認証された暗号化モードとランダムに生成されたキーを使用して暗号化されます。KMS が生成したより強力な暗号化キー (たとえば
a7e63k4b-8loc-40db-a2a1-4d0en2cd8331) を Lambda 関数に使用させる場合は、KMS キー ID を指定します。 -
disable_spill_encryption – (オプション)
Trueに設定されている場合、スピルに対する暗号化を無効にします。デフォルト値はFalseです。この場合、S3 にスピルされたデータは、AES-GCM を使用して (ランダムに生成されたキー、または KMS により生成したキーにより) 暗号化されます。スピル暗号化を無効にすると、特にスピルされる先でサーバー側の暗号化を使用している場合に、パフォーマンスが向上します。 -
glue_catalog – (オプション) クロスアカウントの AWS Glue カタログを指定するために、このオプションを使用します。デフォルトでは、コネクタは自身の AWS Glue アカウントからメタデータを取得しようとします。
でのデータベースとテーブルのセットアップAWS Glue
オプションで、AWS Glue Data Catalog を補足メタデータのソースとして使用できます。Timestream での使用のために AWS Glue テーブルを有効にするには、補足メタデータを供給する Timestream データベースに一致する名前の AWS Glue データベースとテーブルが必要です。
注記
最高のパフォーマンスを得るには、 データベース名とテーブル名には小文字のみを使用してください。大文字と小文字が混在すると、コネクタは大文字と小文字を区別しない検索を実行するため、計算量が多くなります。
Timestream での使用のために AWS Glue テーブルを設定するには、AWS Glue でそのテーブルのプロパティを設定する必要があります。
補足メタデータのために AWS Glue を使用するには
-
AWS Glue コンソールでテーブルを編集して、次のテーブルプロパティを追加します。
timestream-metadata-flag — このプロパティは、補足メタデータのテーブルをコネクタが使用できることを Timestream コネクタに示します。
timestream-metadata-flagプロパティがテーブルプロパティのリスト内に存在するのであれば、このtimestream-metadata-flagに任意の値を指定することが可能です。-
_view_template — 補足メタデータに AWS Glue を使用する場合は、このテーブルプロパティを使用して、任意の Timestream SQL をビューとして指定できます。Athena Timestream コネクタは、ビューからの SQL と Athena の SQL を使用してクエリを実行します。これは、Athena では利用できない Timestream SQL の機能を使用する場合に便利です。
-
このドキュメントに記載されているとおりに、AWS Glue 用として適切なデータ型を使用しているか確認してください。
データ型
現在、Timestream コネクタは Timestream で使用可能なデータ型のサブセット (具体的にはスカラー値 varchar、double、および timestamp) のみをサポートしています。
timeseries データ型をクエリするには、Timestream CREATE_TIME_SERIES 関数を使用する AWS Glue テーブルプロパティでビューを設定する必要があります。また、任意の時系列の列のタイプとして構文 ARRAY<STRUCT<time:timestamp,measure_value::double:double>> を使用するビューのスキーマを提供する必要があります。double をテーブルに適したスカラータイプに必ず置き換えてください。
次のイメージは、時系列でビューをセットアップするように設定された AWS Glue テーブルプロパティの例を示しています。
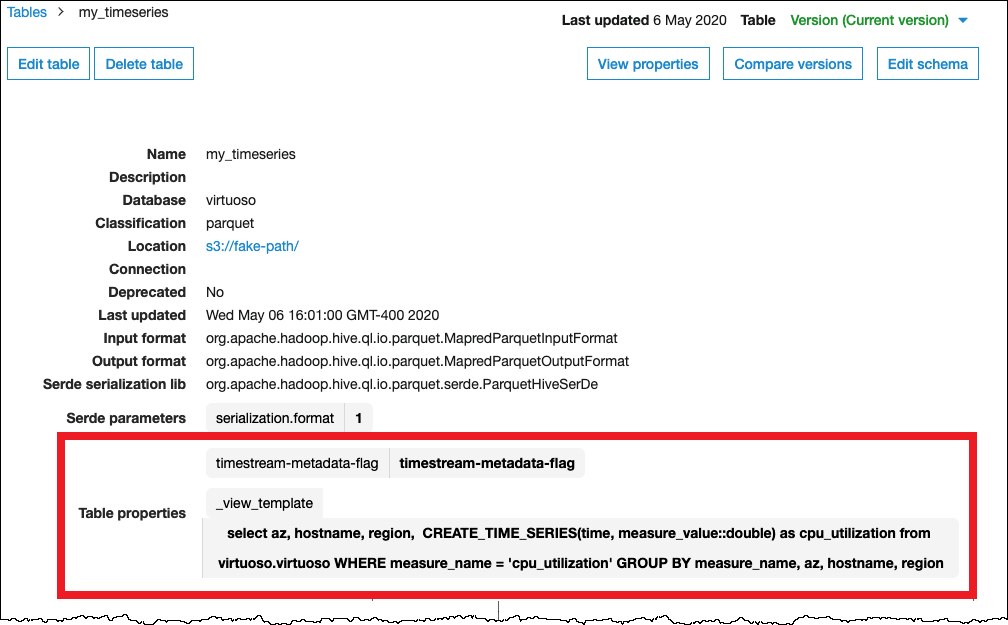
必要な許可
このコネクタが必要とする IAM ポリシーの完全な詳細については、athena-timestream.yamlPolicies セクションを参照してください。次のリストは、必要なアクセス権限をまとめたものです。
-
Amazon S3 への書き込みアクセス – 大規模なクエリからの結果をスピルするために、コネクタは Amazon S3 内のロケーションへの書き込みアクセス権限を必要とします。
-
Athena GetQueryExecution – コネクタはこの権限を使用して、アップストリームの Athena クエリが終了した際に fast-fail を実行します。
-
AWS Glue Data Catalog — Timestream コネクタには、スキーマ情報を取得するために AWS Glue Data Catalog への読み込み専用アクセス権が必要です。
-
CloudWatch Logs – コネクタは、ログを保存するために CloudWatch Logs にアクセスする必要があります。
-
Timestream Access — Timestream クエリの実行用です。
パフォーマンス
LIMIT 句を使用して、インタラクティブなクエリのパフォーマンスを確保するために、返されるデータ (スキャンされたデータではない) を 256 MB 未満に制限することをお勧めします。
Athena Timestream コネクタは、クエリがスキャンするデータを減少させるために述語のプッシュダウンを実行します。LIMIT 句はスキャンされるデータ量を減少させますが、述語を提供しない場合、LIMIT 句を含む SELECT クエリは少なくとも 16 MB のデータをスキャンすることを想定する必要があります。列のサブセットを選択すると、クエリランタイムが大幅に短縮され、スキャンされるデータが減ります。Timestream コネクタは、同時実行によるスロットリングに強いです。
パススルークエリ
Timestream コネクタは、パススルークエリをサポートします。パススルークエリは、テーブル関数を使用して、実行のためにクエリ全体をデータソースにプッシュダウンします。
Timestream でパススルークエリを使用するには、以下の構文を使用できます。
SELECT * FROM TABLE( system.query( query => 'query string' ))
次のクエリ例は、Timestream 内のデータソースにクエリをプッシュダウンします。クエリは customer テーブル内のすべての列を選択し、結果を 10 個に制限します。
SELECT * FROM TABLE( system.query( query => 'SELECT * FROM customer LIMIT 10' ))
ライセンス情報
Amazon Athena Timestream コネクタプロジェクトは、Apache-2.0 License
追加リソース
このコネクタに関するその他の情報については、GitHub.com で対応するサイト
