翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
のターゲットとしての Babelfish の使用 AWS Database Migration Service
を使用して、Microsoft SQL Server ソースデータベースから Babelfish ターゲットにデータを移行できます AWS Database Migration Service。
Aurora 用の Babelfish PostgreSQL は、Microsoft SQL Server クライアントからデータベース接続を受け入れる機能を使用して Amazon Aurora PostgreSQL 互換エディションデータベースを拡張します。これにより、SQL Server 向けに構築されたアプリケーションは、従来の移行と比較してほとんどコードを変更することなく、データベースドライバーを変更せずに、Aurora PostgreSQL と直接連携できるようになります。
がターゲットとして AWS DMS サポートする Babelfish のバージョンについては、「」を参照してくださいのターゲット AWS DMS。Aurora PostgreSQL 上の Babelfish の以前のバージョンの場合は、 Babelfish エンドポイントを使用する前にアップグレードする必要があります。
注記
データを Babelfish に移行するには、Aurora PostgreSQL ターゲットエンドポイントの使用をお勧めします。詳細については、「ターゲットとしての Babelfish for Aurora PostgreSQL の使用」を参照してください。
Babelfish をデータベースエンドポイントとして使用する方法の詳細については、「Amazon Aurora のユーザーガイド」の「Babelfish for Aurora PostgreSQL」を参照してください。
のターゲットとして Babelfish を使用するための前提条件 AWS DMS
が適切なデータ型とテーブルメタデータ AWS DMS を使用していることを確認するには、データを移行する前にテーブルを作成する必要があります。移行を実行する前にターゲットにテーブルを作成しない場合は、誤ったデータ型とアクセス許可を持つテーブルを作成する AWS DMS 可能性があります。たとえば、 は代わりにタイムスタンプ列を binary(8) として AWS DMS 作成し、予想されるタイムスタンプ/ローバージョン機能を提供しません。
移行前にテーブルを準備して作成するには
-
一意の制約、プライマリキー、またはデフォルト制約を含む create table DDL ステートメントを実行します。
外部キー制約、ビュー、ストアドプロシージャ、関数、トリガーなどのオブジェクトの DDL ステートメントは含めないでください。上記はソースデータベースを移行した後に適用できます。
-
テーブルのアイデンティティ列、計算列、または rowversion や timestamp などのデータ型を含む列を特定します。次に、移行タスクを実行する際の既知の問題に対処するために必要な変換ルールを作成します。詳細については、「変換ルールおよび変換アクション」を参照してください。
-
Babelfish がサポートしていないデータ型の列を特定します。次に、サポートされているデータ型を使用するようにターゲットテーブル内の影響を受ける列を変更するか、移行タスク中にこのような列を削除する変換ルールを作成します。詳細については、「変換ルールおよび変換アクション」を参照してください。
次の表は、Babelfish でサポートされていないソースデータ型と、それに対して使用することが推奨されるターゲットでのデータ型を示しています。
ソースデータ型
Babelfish の推奨データ型
HEIRARCHYID
NVARCHAR(250)
GEOMETRY
VARCHAR(MAX)
GEOGRAPHY
VARCHAR(MAX)
ソースの Aurora PostgreSQL Serverless V2 データベースの Aurora キャパシティユニット (ACU) レベルを設定するには
最小 ACU 値を設定することで、 AWS DMS 移行タスクを実行する前にパフォーマンスを向上させることができます。
-
[Severless v2 キャパシティ設定] ウィンドウで、[最小 ACU] を
2、または Aurora DB クラスターに適切なレベルに設定します。詳細については、「Amazon Aurora ユーザーガイド」の「Aurora クラスターの Aurora Serverless v2 での容量範囲の選択」を参照してください。
AWS DMS 移行タスクを実行した後、ACUs の最小値を Aurora PostgreSQL Serverless V2 ソースデータベースの妥当なレベルにリセットできます。
のターゲットとして Babelfish を使用する場合のセキュリティ要件 AWS Database Migration Service
以下では、Babelfish ターゲット AWS DMS で を使用するためのセキュリティ要件について説明します。
-
データベースの作成に使用される管理者ユーザー名 (Admin ユーザー)
-
PSQL ログインと、十分な SELECT、INSERT、UPDATE、DELETE、および REFERENCES アクセス権限を持つユーザー
のターゲットとして Babelfish を使用するためのユーザーアクセス許可 AWS DMS
重要
セキュリティ上の理由から、データ移行に使用するユーザーアカウントは、ターゲットとして使用する Babelfish データベースに登録されているユーザーである必要があります。
Babelfish ターゲットエンドポイントでは、 AWS DMS 移行を実行するための最低限のユーザーのアクセス権限が必要です。
ログインと低特権の Transact-SQL (T-SQL) ユーザーを作成するには
-
サーバーに接続する際に使用するログイン名とパスワードを作成します。
CREATE LOGIN dms_user WITH PASSWORD ='password'; GO -
Babelfish クラスターの仮想データベースを作成します。
CREATE DATABASE my_database; GO -
ターゲットデータベースの T-SQL ユーザーを作成します。
USE my_database GO CREATE USER dms_user FOR LOGIN dms_user; GO -
Babelfish データベース内の各テーブルごとにテーブルに対するアクセス権限を付与します。
GRANT SELECT, DELETE, INSERT, REFERENCES, UPDATE ON [dbo].[Categories] TO dms_user;
のターゲットとしての Babelfish の使用に関する制限 AWS Database Migration Service
Babelfish データベースを AWS DMSのターゲットとして使用する場合、次の制限が適用されます。
-
テーブル作成モードについては、[何もしない] のみがサポートされています。
-
ROWVERSION データ型には、移行タスク中にテーブルから列名を削除するテーブルマッピングルールが必要です。
-
sql_variant データ型はサポートされていません。
-
完全 LOB モードはサポートされています。SQL Server をソースエンドポイントとして使用する場合、LOB をターゲットエンドポイントに移行するために SQL Server エンドポイント接続属性設定
ForceFullLob=Trueを設定する必要があります。 -
レプリケーションタスクの設定には次の制限があります。
{ "FullLoadSettings": { "TargetTablePrepMode": "DO_NOTHING", "CreatePkAfterFullLoad": false, }. } -
Babelfish の TIME (7)、DATETIME2 (7)、DATETIMEOFFSET (7) のデータ型では、時刻の秒部分の精度値が 6 桁に制限されます。上記のデータ型を使用する際は、ターゲットテーブルの精度値を 6 に設定することを検討します。Babelfish バージョン 2.2.0 以降では、TIME (7) と DATETIME2 (7) を使用すると、精度の 7 桁目は常にゼロになります。
-
DO_NOTHING モードでは、DMS はテーブルが既に存在するかどうかを確認します。テーブルがターゲットスキーマに存在しない場合、DMS はソースのテーブル定義に基づいてテーブルを作成し、ユーザー定義のデータ型を基本データ型にマップします。
-
Babelfish ターゲットへの移行 AWS DMS タスクは、ROWVERSION または TIMESTAMP データ型を使用する列を持つテーブルをサポートしていません。転送プロセス中にテーブルから列名を削除するテーブルマッピングルールを使用できます。次の変換ルールの例では、ソースの
Actorという名前のテーブルを変換して、ターゲットのActorテーブル内の先頭文字がcolであるすべての列を削除します。{ "rules": [{ "rule-type": "selection",is "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "remove-column", "rule-target": "column", "object-locator": { "schema-name": "test", "table-name": "Actor", "column-name": "col%" } }] } -
アイデンティティ列または計算列を含むテーブルの場合、ターゲットテーブルで Categories などの大文字と小文字が混合した名前が使用されている場合、DMS タスクのためにテーブル名を小文字に変換する変換ルールアクションを作成する必要があります。次の例は、変換ルールアクションを作成する方法を示しています。 AWS DMS コンソールを使用して小文字にします。詳細については、「変換ルールおよび変換アクション」を参照してください。
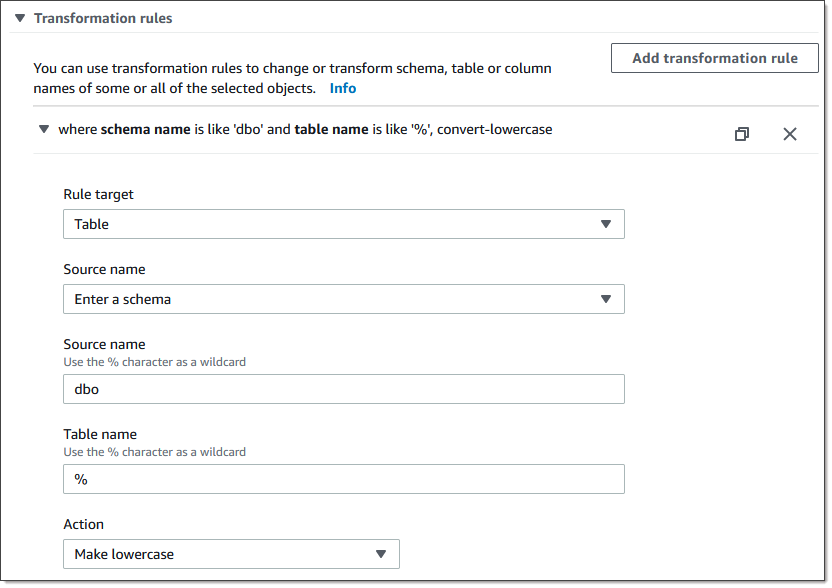
-
Babelfish バージョン 2.2.0 以前のバージョンの場合、DMS では Babelfish ターゲットエンドポイントにレプリケートできる列の数が 20 列に制限されていました。Babelfish 2.2.0 では、この制限は 100 列に引き上げられています。ただし、Babelfish バージョン 2.4.0 以降では、レプリケートできる列の数がさらに増大しています。SQL Server データベースに対して次のコードサンプルを実行すると、長すぎるテーブルを特定できます。
USE myDB; GO DECLARE @Babelfish_version_string_limit INT = 8000; -- Use 380 for Babelfish versions before 2.2.0 WITH bfendpoint AS ( SELECT [TABLE_SCHEMA] ,[TABLE_NAME] , COUNT( [COLUMN_NAME] ) AS NumberColumns , ( SUM( LEN( [COLUMN_NAME] ) + 3) + SUM( LEN( FORMAT(ORDINAL_POSITION, 'N0') ) + 3 ) + LEN( TABLE_SCHEMA ) + 3 + 12 -- INSERT INTO string + 12) AS InsertIntoCommandLength -- values string , CASE WHEN ( SUM( LEN( [COLUMN_NAME] ) + 3) + SUM( LEN( FORMAT(ORDINAL_POSITION, 'N0') ) + 3 ) + LEN( TABLE_SCHEMA ) + 3 + 12 -- INSERT INTO string + 12) -- values string >= @Babelfish_version_string_limit THEN 1 ELSE 0 END AS IsTooLong FROM [INFORMATION_SCHEMA].[COLUMNS] GROUP BY [TABLE_SCHEMA], [TABLE_NAME] ) SELECT * FROM bfendpoint WHERE IsTooLong = 1 ORDER BY TABLE_SCHEMA, InsertIntoCommandLength DESC, TABLE_NAME ;
ターゲットの Babelfish のデータ型
次の表は、 の使用時にサポートされる Babelfish ターゲットデータ型 AWS DMS と AWS DMS 、データ型からのデフォルトのマッピングを示しています。
AWS DMS データ型の詳細については、「」を参照してくださいAWS Database Migration Service のデータ型。
|
AWS DMS データ型 |
Babelfish のデータ型 |
|---|---|
|
BOOLEAN |
TINYINT |
|
BYTES |
VARBINARY(長さ) |
|
DATE |
DATE |
|
TIME |
TIME |
|
INT1 |
SMALLINT |
|
INT2 |
SMALLINT |
|
INT4 |
INT |
|
INT8 |
BIGINT |
|
NUMERIC |
NUMERIC(p,s) |
|
REAL4 |
REAL |
|
REAL8 |
FLOAT |
|
STRING |
列が日付または時刻列の場合、次の操作を行います。
列が日付または時刻列ではない場合、VARCHAR (長さ) を使用します。 |
|
UINT1 |
TINYINT |
|
UINT2 |
SMALLINT |
|
UINT4 |
INT |
|
UINT8 |
BIGINT |
|
WSTRING |
NVARCHAR(長さ) |
|
BLOB |
VARBINARY(最大) DMS でこのデータ型を使用するには、特定のタスク用に BLOB の使用を有効にする必要がある。DMS は、プライマリキーがあるテーブルでのみ BLOB データ型をサポートする。 |
|
CLOB |
VARCHAR(max) DMS でこのデータ型を使用するには、特定のタスクで CLOB の使用を有効にする必要がある。 |
|
NCLOB |
NVARCHAR(最大) DMS でこのデータ型を使用するには、特定のタスクで NCLOB の使用を有効にする必要がある。CDC 中に、DMS はプライマリキーがあるテーブルでのみ NCLOB データ型をサポートする。 |
