**このページの改善にご協力ください**
このユーザーガイドに貢献するには、すべてのページの右側のペインにある「**GitHub でこのページを編集する**」リンクを選択してください。
# Kubernetes の概念
Amazon Elastic Kubernetes Service (Amazon EKS) はオープンソースの [Kubernetes](https://kubernetes.io/) プロジェクトをベースとした AWS マネージドサービスです。Amazon EKS サービスが AWS クラウドとどのように統合するのかについて理解しておくべき点がいくつかあります (特に Amazon EKS クラスターを初めて作成する場合) が、Amazon EKS クラスターを一度起動して実行した後の使用方法は他の Kubernetes クラスターを使う場合とほぼ変わりません。そのため、Kubernetes クラスターの管理とワークロードのデプロイを開始するには、少なくとも Kubernetes の概念の基本について理解しておく必要があります。
このページでは、Kubernetes の概念を [Kubernetes が選ばれる理由](#why-kubernetes)、[クラスター](#concepts-clusters)、[ワークロード](#workloads) の 3 つのセクションに分けています。1 つめのセクションでは、Kubernetes サービスを、特に Amazon EKS のようなマネージドサービスとして実行する場合の利点について説明します。ワークロードのセクションでは、Kubernetes アプリケーションの構築、保存、実行、管理の方法について説明します。クラスターのセクションでは、Kubernetes クラスターを構成しているさまざまなコンポーネントと、Kubernetes クラスターを作成して管理するときのユーザーの責務について説明します。
**Topics**
+ [Kubernetes が選ばれる理由](#why-kubernetes)
+ [クラスター](#concepts-clusters)
+ [ワークロード](#workloads)
+ [次のステップ](#next-steps)
このコンテンツに含まれているリンクをクリックすると、Amazon EKS と Kubernetes の両方のドキュメントに記載されている Kubernetes の概念について解説したページが開き、ここで取り上げたトピックをさらに深く掘り下げることができます。Amazon EKS がどのように Kubernetes コントロールプレーンとコンピューティング機能を実装するかの詳細については、[Amazon EKS アーキテクチャ](eks-architecture.md) を参照してください。
## Kubernetes が選ばれる理由
Kubernetes は、ミッションクリティカルで本番稼働品質のコンテナ化アプリケーションを実行するときの可用性とスケーラビリティを高めることを目的に設計されました。1 台のマシン上で Kubernetes を実行するのではなく (実行可能ではありますが)、需要に応じて拡張または縮小する複数のコンピュータを横断してアプリケーションを実行できるようにすれば、Kubernetes は上記の目標を達成できます。Kubernetes が備える機能により、次のことが簡単に行えます。
+ アプリケーションを複数のマシンにデプロイする (ポッドにデプロイされたコンテナを使用)
+ コンテナの状態をモニタリングし、障害が発生したコンテナを再起動する
+ 負荷に基づいてコンテナをスケールアップ/スケールダウンする
+ コンテナを新しいバージョンで更新する
+ コンテナ間でリソースを割り当てる
+ マシン間でトラフィックを分散する
Kubernetes でこのタイプの複雑なタスクを自動化すれば、アプリケーションデベロッパーはインフラストラクチャのことを気にすることなく、アプリケーションワークロードの構築と改善に専念できます。デベロッパーは通常、YAML 形式の設定ファイルを作成し、そこにアプリケーションの望ましい状態を記述します。これには実行するコンテナ、リソースの上限、ポッドレプリカの数、CPU/メモリの割り当て、アフィニティールールなどが含まれます。
### Kubernetes の属性
上記の目標を達成するため、Kubernetes は次の属性を使用します。
+ **コンテナ化** - Kubernetes はコンテナオーケストレーションツールです。Kubernetes を使用するには、まずアプリケーションをコンテナ化する必要があります。アプリケーションの種類に応じて、これは *マイクロサービスのセット*、バッチジョブ、その他形式のいずれかになります。それにより、アプリケーションで、ツールの巨大なエコシステムを含む Kubernetes ワークフローを利用することができます。そこではコンテナを [イメージとしてコンテナレジストリ](https://kubernetes.io/docs/concepts/containers/images/#multi-architecture-images-with-image-indexes) に保存したり、Kubernetes [クラスター](https://kubernetes.io/docs/concepts/architecture/) にデプロイしたり、利用可能な [ノード](https://kubernetes.io/docs/concepts/architecture/nodes/) 上で実行したりすることができます。個々のコンテナを Kubernetes クラスターにデプロイする前に、Docker または別の [コンテナランタイム](https://kubernetes.io/docs/setup/production-environment/container-runtimes/) を使用してローカルのコンピュータ上で構築しテストすることができます。
+ **スケーラブル** - アプリケーションを実行しているインスタンスのキャパシティーを超えてアプリケーションの需要が拡大した場合は、Kubernetes をスケールアップすることができます。必要に応じて、Kubernetes はアプリケーションに追加の CPU やメモリが必要かどうかを判断し、自動的に利用可能な容量を拡張するか、既存の容量を追加で利用します。アプリケーションでより多くのインスタンスを実行するための十分なコンピューティングがある場合はポッドレベルでスケーリングを実行することができます ([水平ポッド自動スケーリング](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/))。あるいは容量の増加に対応するためにより多くのノードを起動する必要がある場合はノードレベルでスケーリングを実行することができます ([クラスターオートスケーラー](https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler) または [Karpenter](https://karpenter.sh/))。容量が不要になると、これらのサービスは不要なポッドを削除して、不要なノードをシャットダウンすることができます。
+ **使用可能** - アプリケーションまたはノードが異常な状態になった場合や使用できなくなった場合、Kubernetes は実行中のワークロードを使用可能な別のノードに移動できます。この問題はワークロードを実行しているワークロードまたはノードの実行中のインスタンスを削除すれば、強制的に解決できます。ここでのポイントはワークロードを現在の場所で実行できなくなったときは他の場所で起動できるという点です。
+ **宣言型** - Kubernetes は、アクティブな照合を使用して、クラスターに宣言した状態が実際の状態と一致していることを常にチェックします。[Kubernetes オブジェクト](https://kubernetes.io/docs/concepts/overview/working-with-objects/) をクラスターに適用すると、通常は YAML 形式の設定ファイルを通じて、例えばクラスター上で実行するワークロードの起動をリクエストすることができます。後で設定に変更を加えることができます。例えば、新しいバージョンのコンテナを使用する、メモリをさらに割り当てるといったことができます。Kubernetes は、目的の状態を確立するためにやるべきことをやります。例えば、ノードの起動や停止、ワークロードの停止および再起動、更新したコンテナの取得などを実行してください。
+ **コンポーザブル** - アプリケーションは通常、複数のコンポーネントで構成されているため、これら一連のコンポーネント (通常は複数のコンテナで表されます) をまとめて管理できるようにしておくことをお勧めします。これを、Docker Compose では Docker を使用して直接実行するのに対して、Kubernetes では [Kompose](http://kompose.io/) コマンドを利用して実行します。その方法の例については「[Translate a Compose File to Kubernetes Resources](https://kubernetes.io/docs/tasks/configure-pod-container/translate-compose-kubernetes/)」を参照してください。
+ **拡張可能** - 独自のソフトウェアとは異なり、オープンソースの Kubernetes プロジェクトではニーズに合わせて Kubernetes を自由に拡張できるようになっています。API と設定ファイルは直接変更することができます。サードパーティーは、インフラストラクチャとエンドユーザー Kubernetes 機能の両方を拡張する場合、独自の [コントローラー](https://kubernetes.io/docs/concepts/architecture/controller/) を作成するよう奨励されています。[Webhook](https://kubernetes.io/docs/reference/access-authn-authz/extensible-admission-controllers/) を使用すると、クラスタールを設定して、ポリシーを適用し、状況の変化に対応することができます。Kubernetes クラスターを拡張する方法の詳細については、「[Kubernetes を拡張する](https://kubernetes.io/docs/concepts/extend-kubernetes/)」を参照してください。
+ **ポータブル** - 多くの組織では、アプリケーションのニーズをすべて同じ方法で管理できることから、自社での Kubernetes の運用を標準化しています。デベロッパーはコンテナ化されたアプリケーションを同じパイプラインを使って構築し、保存することができます。その後、オンプレミス、クラウド、レストランの POS 端末、企業のリモートサイトに分散する IOT デバイスなどで稼働している Kubernetes クラスターにこうしたアプリケーションをデプロイできます。オープンソースであるため、このような特殊な Kubernetes ディストリビューションをその管理に必要なツールと併せて開発することができます。
### Kubernetes の管理
Kubernetes ソースコードは無料で入手できるため、手元にある機器を使用して Kubernetes をインストールし、管理することができます。ただし、Kubernetes を自己管理するには運用に関する専門知識が必要であり、維持していくには時間と労力がかかります。そのため、本番環境のワークロードをデプロイする人の大半が、独自のテスト済み Kubernetes ディストリビューションと、Kubernetes の専門家のサポートを備えた、クラウドプロバイダー (Amazon EKS など) またはオンプレミスプロバイダー (Amazon EKS Anywhere など) を利用しています。これらを利用することで、以下のようなクラスターのメンテナンスに必要な未分化で手間のかかる作業の多くを軽減しています。
+ **ハードウェア** - 要件に応じて Kubernetes を実行できるハードウェアがない場合、AWS Amazon EKS などのクラウドプロバイダーを利用すると初期費用を節約できます。Amazon EKS ではコンピュータインスタンス (Amazon Elastic Compute Cloud)、独自のプライベート環境 (Amazon VPC)、アイデンティティとアクセス許可の一元管理 (IAM)、ストレージ (Amazon EBS) など、AWS で提供されている最善のクラウドリソースを利用できます。AWS はコンピュータ、ネットワーク、データセンター、および Kubernetes の実行に必要な他のすべての物理コンポーネントを管理します。同様に、需要が最も高い日に最大容量を処理できるようにデータセンターを計画しておく必要はありません。Amazon EKS Anywhere やその他のオンプレミスの Kubernetes クラスターの場合、Kubernetes デプロイに使用されるインフラストラクチャの管理は利用する側の責任となりますが、引き続き AWS を利用して Kubernetes を最新の状態に保つことができます。
+ **コントロールプレーン管理** - Amazon EKS は AWS がホストしている Kubernetes コントロールプレーンのセキュリティと可用性を管理します。コンテナのスケジュール、アプリケーションの可用性の管理、その他の重要なタスクはこのコントロールプレーンが行うため、ユーザーはアプリケーションのワークロードに専念できます。クラスターが故障した場合、AWS には実行状態に復元するための方法がいくつかあります。Amazon EKS Anywhere の場合、コントロールプレーンを自分で管理することになります。
+ **テスト済みのアップグレード** - クラスターをアップグレードするときは、Amazon EKS または Amazon EKS Anywhere を利用して、Kubernetes ディストリビューションのテスト済みバージョンを用意できます。
+ **アドオン** - 拡張して Kubernetes と連携するように構築された数百ものプロジェクトがあり、クラスターのインフラストラクチャに追加したり、ワークロードの実行を支援するために使用したりできます。これらのアドオンを自分で構築して管理する代わりに、AWS にはクラスターで使用できる [Amazon EKS アドオン](eks-add-ons.md)Amazon EKS アドオンが用意されています。Amazon EKS Anywhere には多くの一般的なオープンソースプロジェクトのビルドを含む、[キュレーションパッケージ](https://anywhere.eks.amazonaws.com/docs/packages/) があります。そのため、ユーザーはソフトウェアを自分で構築したり、重要なセキュリティパッチ、バグ修正、アップグレードを管理したりする必要はありません。同様に、デフォルトの設定がニーズを満たしていれば、通常、それらのアドオンの設定はほとんど必要ありません。アドオンを使用してクラスターを拡張する方法については、[拡張クラスター](#extend-clusters) を参照してください。
### Kubernetes の動作
以下の図は、Kubernetes 管理者またはアプリケーションデベロッパーが Kubernetes クラスターを作成して使用する際に実行する主要なアクティビティを示したものです。そのプロセスにおいて、基盤となるクラウドプロバイダーの例として AWS クラウドを使用し、Kubernetes のコンポーネントがどのように相互作用するかを説明しています。
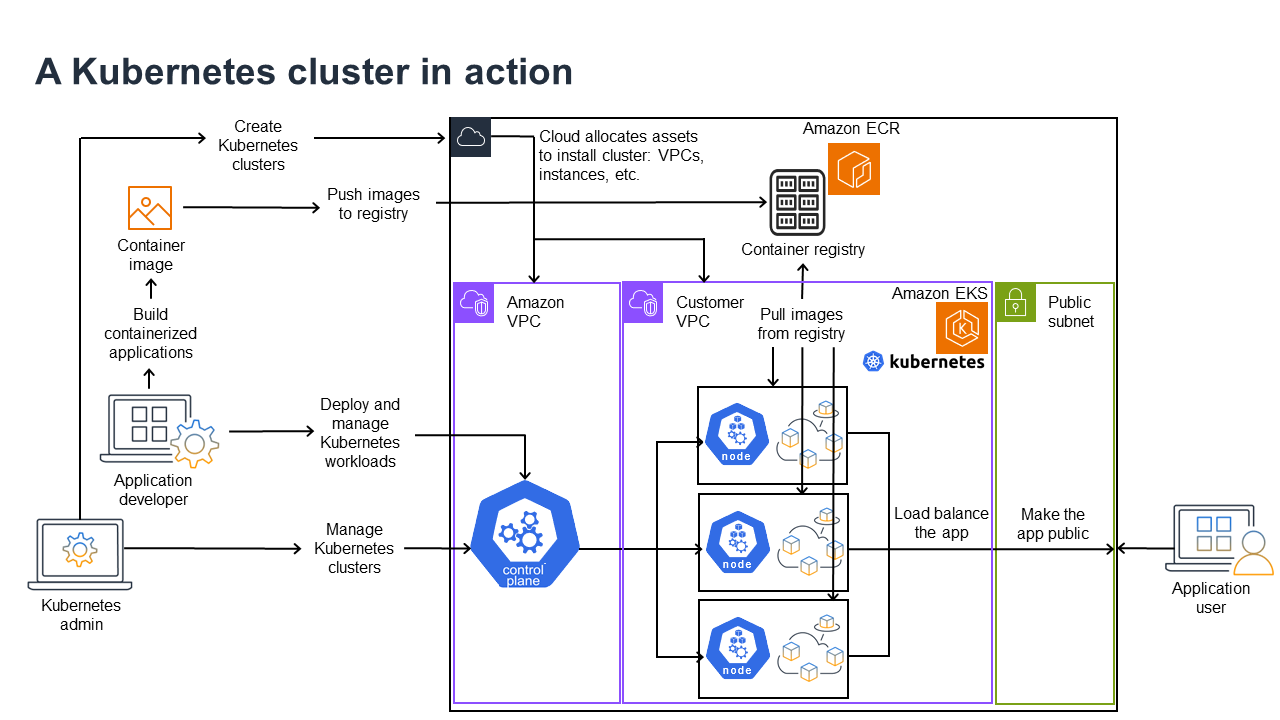
Kubernetes 管理者は、クラスターが構築されるプロバイダーのタイプに固有のツールを使用して、Kubernetes クラスターを作成します。この例では、Amazon EKS という Kubernetes マネージドサービスを提供する AWS クラウドをプロバイダーとして使用します。マネージドサービスは、クラスター用に仮想プライベートクラウド (Amazon VPC) を新たに 2 つ作成する、ネットワークを設定する、クラウドアセット管理用に新しい VPC に対して Kubernetes アクセス許可を直接マッピングするなど、クラスターの作成に必要なリソースを自動的に割り当てます。マネージドサービスは、コントロールプレーンサービスの実行先を確認し、ワークロードを実行するための Kubernetes ノードとして 0 個以上の Amazon EC2 インスタンスを割り当てます。AWS はコントロールプレーン用に 1 つの Amazon VPC 自体を管理し、もう 1 つの Amazon VPC にはワークロードを実行するカスタマーノードが含まれます。
Kubernetes 管理者が今後行うタスクの多くは、`kubectl` などの Kubernetes ツールを使って行われます。このツールはクラスターのコントロールプレーンに直接サービスをリクエストします。その場合、クラスターに対してクエリや変更を行う方法は任意の Kubernetes クラスターに対して行う場合の方法と非常によく似ています。
このクラスターにワークロードをデプロイする場合、アプリケーションデベロッパーはいくつかのタスクを実行することができます。デベロッパーはアプリケーションを 1 つ以上のコンテナイメージに構築し、そのイメージを Kubernetes クラスターにアクセスできるコンテナレジストリにプッシュする必要があります。AWS には、それを行うための Amazon Elastic Container Registry (Amazon ECR) というレジストリがあります。
このアプリケーションを実行するにはデベロッパーはレジストリからどのコンテナを取得するか、それらのコンテナをポッドにどのようにラップするかなど、アプリケーションの実行方法をクラスターに指示する YAML 形式の設定ファイルを作成します。コントロールプレーン (スケジューラー) はコンテナを 1 つ以上のノードにスケジュールし、各ノードのコンテナランタイムが必要なコンテナーを実際にプルして実行してください。また、デベロッパーは application load balancer を設定することで、各ノードで実行されている利用可能なコンテナにトラフィックを分散し、パブリックネットワーク上で外部から利用できるようにアプリケーションを公開することもできます。これで、アプリケーションを使用したいユーザーが、アプリケーションエンドポイントに接続してアクセスできるようになります。
以下のセクションでは、これらの各機能について、Kubernetes のクラスターとワークロードの観点から詳しく説明します。
## クラスター
ジョブに Kubernetes クラスターの起動および管理が含まれる場合は、Kubernetes クラスターの作成、強化、管理、削除の方法を理解しておく必要があります。また、クラスターを構成しているコンポーネントと、それらのコンポーネントを維持するために行うべきことについても、知っておく必要があります。
クラスターを管理するツールは、Kubernetes のサービスとその基盤となるハードウェアプロバイダーとの重複を処理します。そのため、これらのタスクの自動化は Kubernetes プロバイダー (Amazon EKS や Amazon EKS Anywhere など) が、そのプロバイダーに固有のツールを使って行うのが一般的です。例えば、Amazon EKS クラスターを起動する場合は `eksctl create cluster` を使用できますが、Amazon EKS Anywhere には `eksctl anywhere create cluster` を使用できます。これらのコマンドは、Kubernetes クラスターを作成しますが、プロバイダー固有のものであるため、Kubernetes プロジェクト自体には含まれていないことに注意してください。
### クラスターの作成および管理ツール
Kubernetes プロジェクトには、Kubernetes クラスターを手動で作成するためのツールが用意されています。したがって、Kubernetes を単一のマシンにインストールしたり、マシン上でコントロールプレーンを実行したり、ノードを手動で追加したりする場合は、Kubernetes [インストールツール](https://kubernetes.io/docs/tasks/tools/)に一覧表示されている [kind](https://kind.sigs.k8s.io/)、[minikube](https://kubernetes.io/docs/tutorials/hello-minikube/)、[kubeadm](https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/) などの CLI ツールを使用できます。クラスターの作成と管理のライフサイクル全体を簡素化して自動化するには、Amazon EKS や Amazon EKS Anywhere といった定評ある Kubernetes プロバイダーがサポートしているツールを使用してください。作業がはるかに簡単になります。
AWS クラウドでは[Amazon EKS](https://docs.aws.amazon.com/eks/) クラスターを、[eksctl](https://eksctl.io/) などの CLI ツールや、Terraform などのより宣言的なツールを使用して作成することができます (「[Amazon EKS Blueprints for Terraform](https://github.com/aws-ia/terraform-aws-eks-blueprints)」を参照)。クラスターは AWS マネジメントコンソール を使用して作成することもできます。Amazon EKS で何ができるかについては、「[Amazon EKS の機能](https://aws.amazon.com/eks/features/)」を参照してください。Kubernetes に関して Amazon EKS 側で果たす責務は次のとおりです。
+ **マネージドコントロールプレーン** - AWS はコントロールプレーンをユーザーに代わって管理し、AWS アベイラビリティーゾーン全体で利用可能にするため、Amazon EKS クラスターが利用可能かつスケーラブルになります。
+ **ノード管理** - ノードを手動で追加する代わりに、[マネージドノードグループを使用してノードライフサイクルを簡素化する](managed-node-groups.md)マネージドノードグループまたは [Karpenter](https://karpenter.sh/) を使用して、必要に応じて Amazon EKS でノードを自動的に作成できます。マネージドノードグループは、Kubernetes [クラスター自動スケーリング](https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md) と統合されています。ノード管理ツールを使用すると、[スポットインスタンス](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-spot-instances.html) やノード統合などによりコストを節約したり、ワークロードのデプロイ方法やノードの選択方法を設定する [スケジューリング](https://karpenter.sh/docs/concepts/scheduling/) 機能を使用して可用性を実現したりすることができます。
+ **クラスターネットワーク** - `eksctl` は、クラウドフォーメーション テンプレートを使用して、Kubernetes クラスター内のコントロールプレーンとデータプレーン (ノード) コンポーネントとの間にネットワークを設定します。また、内部と外部の通信を行うためのエンドポイントも設定します。詳細については「[ツールのインストール Amazon EKS ワーカーノードのクラスターネットワーキングの謎を解く](https://aws.amazon.com/blogs/containers/de-mystifying-cluster-networking-for-amazon-eks-worker-nodes)」を参照してください。Amazon EKS 内のポッド間の通信は [EKS Pod Identity が Pod に AWS サービスへのアクセス権を付与する仕組みを学ぶ](pod-identities.md)Amazon EKS Pod Identity を使用して行われます。これによりポッドは認証情報やアクセス許可を管理する AWS クラウドの方法を利用できるようになります。
+ **アドオン** - Amazon EKS を使用すると、Kubernetes クラスターをサポートするためによく使用されるソフトウェアコンポーネントを構築して追加する必要がなくなります。例えば、AWS マネジメントコンソール から Amazon EKS クラスターを作成すると、Amazon EKS kube-proxy ([Amazon EKS クラスターで `kube-proxy` を管理する](managing-kube-proxy.md))、Amazon VPC CNI plugin for Kubernetes ([Amazon VPC CNI を使用して Pod に IP を割り当てる](managing-vpc-cni.md))、CoreDNS ([Amazon EKS クラスターで DNS の CoreDNS を管理する](managing-coredns.md)) アドオンが自動的に追加されます。利用可能なアドオンも含む、これらのアドオンの詳細については、[Amazon EKS アドオン](eks-add-ons.md) を参照してください。
クラスターをオンプレミスのコンピュータとネットワーク上で実行できるように、Amazon は [Amazon EKS Anywhere](https://anywhere.eks.amazonaws.com/) を提供しています。AWS クラウドをプロバイダーにする代わりに、Amazon EKS Anywhere を [VMware vSphere](https://anywhere.eks.amazonaws.com/docs/getting-started/vsphere/)、[ベアメタル](https://anywhere.eks.amazonaws.com/docs/getting-started/baremetal/) ([ティンカーベル プロバイダー](https://tinkerbell.org))、[Snow](https://anywhere.eks.amazonaws.com/docs/getting-started/snow/)、[CloudStack](https://anywhere.eks.amazonaws.com/docs/getting-started/cloudstack/)、[Nutanix](https://anywhere.eks.amazonaws.com/docs/getting-started/nutanix/) の各プラットフォームで、独自の機器を使用して実行することを選択できます。
Amazon EKS Anywhere は Amazon EKS で使用されているものと同じ [Amazon EKS Distro](https://distro.eks.amazonaws.com/) ソフトウェアをベースにしています。ただし、Amazon EKS Anywhere は Amazon EKS Anywhere クラスター内のマシンのライフサイクル全体を管理するために、[Kubernetes クラスター API](https://cluster-api.sigs.k8s.io/) (CAPI) インターフェイスのさまざまな実装に依存しています (vSphere の場合は [CAPV](https://github.com/kubernetes-sigs/cluster-api-provider-vsphere)、CloudStack の場合は [CAPC](https://github.com/kubernetes-sigs/cluster-api-provider-cloudstack) など)。クラスター全体がユーザーの機器上で実行されるため、ユーザーはコントロールプレーンの管理とデータのバックアップの責任を追加で負うことになります (本ドキ `etcd` ュメントで後述する etcd を参照)。
### クラスターコンポーネント
Kubernetes クラスターコンポーネントは、コントロールプレーンとワーカーノードという 2 つの主要な領域に分かれています。[コントロールプレーンコンポーネント](https://kubernetes.io/docs/concepts/overview/components/#control-plane-components) はクラスターを管理し、その API へのアクセスを提供します。ワーカーノード (単にノードとも呼ばれます) は実際のワークロードを実行する場所です。[ノードコンポーネント](https://kubernetes.io/docs/concepts/overview/components/#node-components) は各ノード上で実行されるサービスで構成され、コントロールプレーンと通信してコンテナを実行してください。クラスターのワーカーノードのセットは *データプレーン* と呼ばれます。
#### コントロールプレーン
コントロールプレーンはクラスターを管理する一連のサービスで構成されています。これらのサービスはすべて 1 台のコンピュータで実行される場合もあれば、複数のコンピュータに分散される場合もあります。内部的にはこれらはコントロールプレーンインスタンス (CPI) と呼ばれます。CPI の実行方法はクラスターの規模と、高可用性の要件に応じて異なります。クラスターの需要が増えると、コントロールプレーンサービスはスケールしてそのサービスのインスタンスを増やし、リクエストはインスタンス間で負荷分散されます。
Kubernetes コントロールプレーンのコンポーネントが実行するタスクには、以下のものがあります。
+ **クラスターコンポーネント (API サーバー) との通信** - API サーバー ([kube-apiserver](https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/)) はクラスターへのリクエストをクラスターの内部と外部の両方から行えるようにするために Kubernetes API を公開します。つまり、クラスターのオブジェクト (ポッド、サービス、ノードなど) を追加または変更するリクエストはポッドを実行する `kubectl` のリクエストなどの外部コマンドから送信することができます。同様に、ポッドのステータスを `kubelet` サービスにクエリするときのように、API サーバーからクラスター内のコンポーネントに対してリクエストを実行することができます。
+ **クラスターに関するデータの保存 (`etcd` キーバリューストア)\* - ** サービスはクラスターの現在の状態を追跡するという重要な役割を担っています。`etcd``etcd` サービスにアクセスできなくなると、ワークロードはしばらく実行し続けますが、クラスターの状態を更新したりクエリしたりすることはできなくなります。そのため、重要なクラスターは通常、複数の負荷分散された `etcd` サービスのインスタンスを同時に実行し、データの損失や破損に備えて、`etcd` キーバリューストアのバックアップを定期的に行っています。Amazon EKS では、これはすべてデフォルトで自動的に処理されます。Amazon EKS Anywhere は [etcd のバックアップと復元](https://anywhere.eks.amazonaws.com/docs/clustermgmt/etcd-backup-restore/) の手順を公開しています。によるデータ管理の方法については[https://etcd.io/docs/v3.5/learning/data_model/](https://etcd.io/docs/v3.5/learning/data_model/)Data Model `etcd` を参照してください。
+ **ノードへの Pod のスケジュール (スケジューラー)** - Kubernetes での Pod の起動または停止のリクエストは、[Kubernetes スケジューラー](https://kubernetes.io/docs/concepts/scheduling-eviction/kube-scheduler/) ([kube-scheduler](https://kubernetes.io/docs/reference/command-line-tools-reference/kube-scheduler/)) に送信されます。クラスターにはポッドを実行できるノードが複数含まれている場合があるため、どのノード (レプリカの場合は複数のノード) でポッドを実行するかはスケジューラーが決定します。リクエストされたポッドを既存のノードで実行するための十分な容量がない場合、他のポッドをプロビジョニングしていなければそのリクエストは失敗します。プロビジョニングには新しいノードを自動的に起動してワークロードを処理する [マネージドノードグループを使用してノードライフサイクルを簡素化する](managed-node-groups.md)マネージド型ノードグループや [Karpenter](https://karpenter.sh/) などのサービスを有効化する作業が含まれます。
+ **コンポーネントを目的の状態に維持する (コントローラーマネージャー)** - Kubernetes コントローラーマネージャーは、クラスターの状態をモニタリングしたり、クラスターに変更を加えて期待される状態に戻したりするデーモンプロセス ([kube-controller-manager](https://kubernetes.io/docs/reference/command-line-tools-reference/kube-controller-manager/)) として実行されます。特に、`statefulset-controller`、`endpoint-controller`、`cronjob-controller`、`node-controller` など、さまざまな Kubernetes オブジェクトを監視するコントローラーがいくつかあります。
+ **クラウドリソースの管理 (クラウドコントローラーマネージャー)** - Kubernetes とその基盤となるデータセンターリソースのリクエストを実行するクラウドプロバイダーとのやり取りは、[クラウドコントローラーマネージャー](https://kubernetes.io/docs/concepts/architecture/cloud-controller/) ([cloud-controller-manager](https://github.com/kubernetes/kubernetes/tree/master/cmd/cloud-controller-manager)) が処理します。クラウド コントローラー マネージャー が管理するコントローラーにはルートコントローラー (クラウドネットワークルートの設定用)、サービスコントローラー (クラウドのロードバランシングサービスを使用するためのもの)、ノードライフサイクルコントローラー (クラウド API を使用してライフサイクル全体でノードを Kubernetes と同期させるためのもの) があります。
#### ワーカーノード (データプレーン)
単一ノード Kubernetes クラスターの場合、ワークロードはコントロールプレーンと同じマシンで実行してください。ただし、より標準的な構成では Kubernetes ワークロードを実行するための専用の個別のコンピュータシステム ([ノード](https://kubernetes.io/docs/concepts/architecture/nodes/)) を 1 つ以上用意します。
Kubernetes クラスターを初めて作成する場合、作成ツールによっては (既存のコンピュータシステムを識別するか、プロバイダーに新しいコンピュータシステムを作成させることによって) 特定の数のノードをクラスターに追加するように設定できるものがあります。これらのシステムにワークロードを追加する前に、以下の機能を実装するためのサービスを各ノードに追加します。
+ **各ノードの管理 (`kubelet`)\* - API サーバーは各ノードで実行されている **kubelet[ サービスと通信し、ノードが正しく登録され、スケジューラーからリクエストされたポッドが実行されていることを確認します。](https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/)kubelet はポッドマニフェストを読み取り、ローカルシステム上で Pod が必要とするストレージボリュームやその他の機能を設定できます。また、ローカルで実行されているコンテナの状態もチェックすることができます。
+ **ノードでコンテナを実行する (コンテナランタイム)** - 各ノードの [コンテナランタイム](https://kubernetes.io/docs/setup/production-environment/container-runtimes/) はノードに割り当てられた各ポッドに対してリクエストされたコンテナを管理します。つまり、適切なレジストリからコンテナイメージをプルし、そのコンテナを実行して停止し、コンテナに関するクエリに応答することができます。デフォルトのコンテナランタイムは [containerd](https://github.com/containerd/containerd/blob/main/docs/getting-started.md) です。Kubernetes 1.24 以降、コンテナランタイムとして使用できる Docker (`dockershim`) 固有の統合は、Kubernetes から削除されました。ローカルシステムでコンテナをテストおよび実行する際は、引き続き Docker を使用することができますが、Kubernetes で Docker を使用するには、各ノードに [Docker Engine をインストール](https://docs.docker.com/engine/install/#server)して Kubernetes で使用する必要があります。
+ **コンテナ間のネットワークを管理する (`kube-proxy`)** - Pod 間の通信をサポートできるようにするために、Kubernetes は [Service](https://kubernetes.io/docs/concepts/services-networking/service/) と呼ばれる機能を使用して、それらの Pod に関連付けられた IP アドレスとポートを追跡する Pod ネットワークを設定します。[kube-proxy](https://kubernetes.io/docs/reference/command-line-tools-reference/kube-proxy/) サービスは各ノードで実行し、ポッド間でその通信を可能にします。
### 拡張クラスター
クラスターをサポートするために Kubernetes に追加できるサービスがいくつかありますが、そのいずれもコントロールプレーンでは実行されません。それらのサービスは多くの場合、kube-system 名前空間のノードで直接実行されるか、独自の名前空間で実行されます (サードパーティーのサービスプロバイダーではよく行われています)。一般的な例が、クラスターに DNS サービスを提供する CoreDNS サービスです。クラスターの kube-system でどのクラスターサービスが実行されているのかを確認する方法については「[組み込みサービスの発見](https://kubernetes.io/docs/tasks/access-application-cluster/access-cluster-services/)」を参照してください。
クラスターに追加できるアドオンにはさまざまな種類があります。クラスターを健全な状態に保つにはログ記録、監査、メトリクスなどの作業を実行できる、[クラスターのパフォーマンスをモニタリングし、ログを表示する](eks-observe.md)オブザーバビリティ機能を追加します。この情報があれば、多くの場合、同じオブザーバビリティインターフェイスを使用して、発生した問題をトラブルシューティングすることができます。こうしたタイプのサービスには、[Amazon GuardDuty](https://docs.aws.amazon.com/guardduty/latest/ug/runtime-monitoring.html)、CloudWatch ([Amazon CloudWatch でクラスターデータをモニタリングする](cloudwatch.md) を参照)、[AWS Distro for OpenTelemetry](https://aws-otel.github.io/)、Amazon VPC CNI plugin for Kubernetes ([Amazon VPC CNI を使用して Pod に IP を割り当てる](managing-vpc-cni.md) を参照)、[Grafana Kubernetes Monitoring](https://grafana.com/docs/grafana-cloud/monitor-infrastructure/kubernetes-monitoring/configuration/config-aws-eks/) などがあります。[クラスターのアプリケーションデータストレージを使用する](storage.md)ストレージでは Amazon EKS のアドオンには [Amazon EBS で Kubernetes ボリュームストレージを使用する](ebs-csi.md)Amazon エラスティック・ブロック・ストア CSI ドライバー (ブロックストレージデバイスの追加用)、[Amazon EFS で Elastic File System ストレージを使用する](efs-csi.md)Amazon エラスティック・ファイル・システム CSI ドライバー (ファイルシステムストレージの追加用)、サードパーティー製ストレージのアドオン ([FSx for NetApp ONTAP で高性能なアプリケーションストレージを使用する](fsx-ontap.md)Amazon FSx for NetApp ONTAP CSI ドライバーなど) などがあります。
使用可能な Amazon EKS アドオンの完全なリストについては、[Amazon EKS アドオン](eks-add-ons.md) を参照してください。
## ワークロード
Kubernetes では、[ワークロード](https://kubernetes.io/docs/concepts/workloads/)を「Kubernetes で動作するアプリケーション」と定義しています。そのアプリケーションは [ポッド](https://kubernetes.io/docs/reference/glossary/?fundamental=true#term-pod) 内の [コンテナ](https://kubernetes.io/docs/reference/glossary/?fundamental=true#term-container) として実行される、一連のマイクロサービスで構成されていますが、バッチジョブやその他の種類のアプリケーションとして実行される場合もあります。Kubernetes は、それらのオブジェクトを設定またはデプロイするために行われたリクエストを確実に実行する役割を担います。アプリケーションをデプロイするユーザーはコンテナの構築方法、ポッドの定義方法、デプロイに使用する方法を学ぶ必要があります。
### コンテナ
Kubernetes にデプロイして管理するアプリケーションワークロードの最も基本的な要素が *[Pod](https://kubernetes.io/docs/concepts/workloads/pods/)* です。ポッドはアプリケーションのコンポーネントを格納する方法であるだけでなく、ポッドの属性を記述する仕様を定義する方法でもあります。RPM や Deb パッケージは Linux システム用のソフトウェアをまとめてパッケージ化しますが、それ自体はエンティティとしては動作しません。
ポッドはデプロイ可能な最小のユニットであるため、通常は 1 つのコンテナしか格納できません。しかし、コンテナが密結合している場合は複数のコンテナを 1 つのポッドに含めることができます。例えばウェブサーバーコンテナはログ記録、モニタリング、またはウェブサーバーコンテナと密結合したその他のサービスを提供できる [サイドカー](https://kubernetes.io/docs/concepts/workloads/pods/sidecar-containers/) タイプのコンテナとともに、ポッドにパッケージ化できます。この場合、同じポッド内にあることで、そのポッドが実行している各インスタンスでは両方のコンテナが常に同じノードで実行されることになります。同様に、ポッド内のすべてのコンテナは同じ環境を共有し、ポッド内のコンテナは隔離された同じホストにあるかのように実行されます。これにより、各コンテナはポッドへのアクセスを可能にする 1 つの IP アドレスを共有し、コンテナはあたかも独自のローカルホスト上で実行しているかのように相互に通信することができます。
ポッドの仕様 ([PodSpec](https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#PodSpec)) はポッドの望ましい状態を定義します。ワークロードリソースを使用して [ポッドテンプレート](https://kubernetes.io/docs/concepts/workloads/pods/#pod-templates) を管理することで、個別のポッドまたは複数のポッドをデプロイできます。ワークロードリソースには [展開](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/) (複数のポッドレプリカを管理する)、[StatefulSets](https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/) (データベースポッドなどの一意にする必要があるポッドをデプロイする)、[DaemonSets](https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/) (ポッドをすべてのノードで継続的に実行する必要がある場合) が含まれます。詳細は後ほど説明します。
ポッドはデプロイできる最小のユニットですが、コンテナは構築して管理できる最小のユニットです。
#### コンテナの構築
ポッドは実際には 1 つ以上のコンテナを取り囲む構造に過ぎず、各コンテナ自体にファイルシステム、実行ファイル、設定ファイル、ライブラリ、その他アプリケーションを実際に実行するためのコンポーネントが格納されています。コンテナを普及させた会社の名前が Docker Inc. であったため、Docker コンテナと呼ばれることもあります。しかし、コンテナのランタイム、イメージ、ディストリビューション方法を業界向けに定義してきたのは [オープン・コンテナ構想](https://opencontainers.org/) です。また、コンテナは Linux に既に存在していた多くの機能から作成されていることから、OCI コンテナ、Linux コンテナ、あるいはただ単にコンテナとも呼ばれます。
コンテナを構築するときは通常、Dockerfile (会社名から命名) から始めます。Dockerfile 内では以下を識別します。
+ **ベースイメージ** - ベースのコンテナイメージは通常はオペレーティングシステムのファイルシステム ([レッドハット・エンタープライズ Linux](https://catalog.redhat.com/software/base-images) や [Ubuntu](https://gallery.ecr.aws/docker/library/ubuntu) など) の最小バージョン、または特定の種類のアプリケーション ([nodejs](https://catalog.redhat.com/software/container-stacks/detail/611c11fabd674341b5c5ed64) や [python](https://gallery.ecr.aws/docker/library/python) アプリケーションなど) を実行するソフトウェアを提供するように拡張された最小システムのいずれかから構築されるコンテナです。
+ **アプリケーションソフトウェア** - Linux システムに追加するときとほぼ同じ方法で、アプリケーションソフトウェアをコンテナに追加できます。例えば、Dockerfile では `npm` や `yarn` を実行して Java アプリケーションをインストールするか、`yum` や `dnf` を実行して RPM パッケージをインストールすることができます。つまり、Dockerfile で RUN コマンドを使用すると、ベースイメージのファイルシステムで使用可能な任意のコマンドを実行して、生成されたコンテナイメージの内部でソフトウェアをインストールしたり、設定したりできます。
+ **インストラクション** - [Dockerfile 参照](https://docs.docker.com/reference/dockerfile/) にはDockerfile の設定時に追加できるインストラクションが記載されています。これにはコンテナ自体の中にあるもの (ローカルシステムの `ADD` または `COPY` ファイル) の構築、コンテナを実行するときに実行するコマンドの特定 (`CMD` または `ENTRYPOINT`)、コンテナを実行するシステムへのコンテナの接続 (実行する `USER`、マウントするローカル `VOLUME`、`EXPOSE` するポート) などに使用する指示が含まれています。
`docker` コマンドとサービスは従来、コンテナ (`docker build`) の構築に使用されてきましたが、コンテナイメージの構築に使用できるその他ツールには [podman](https://docs.podman.io/en/stable/markdown/podman-build.1.html) や [nerdctl](https://github.com/containerd/nerdctl) などがあります。コンテナの構築方法については「[より良いコンテナ・イメージの構築](https://aws.amazon.com/blogs/containers/building-better-container-images)」または「[Dockerビルドの概要](https://docs.docker.com/build/)」参照してください。
#### コンテナの保存
コンテナイメージを作成したら、ワークステーションのコンテナ[ディストリビューションレジストリ](https://distribution.github.io/distribution/)、またはパブリックコンテナレジストリに保存できます。ワークステーションでプライベートコンテナレジストリを実行すると、コンテナイメージをローカルに保存して、すぐに利用できるようにすることができます。
コンテナイメージを、よりパブリックな方法で保存するときはイメージをパブリックコンテナレジストリーにプッシュします。パブリックコンテナレジストリはコンテナイメージの保存と配布を一元的に行える場所です。代表的なパブリックコンテナレジストリには [Amazon Elastic Container Registry](https://aws.amazon.com/ecr/)、[Red Hat Quay](https://quay.io/) レジストリ、[Docker Hub](https://hub.docker.com/) レジストリなどがあります。
Amazon Elastic Kubernetes Service (Amazon EKS) でコンテナ化されたワークロードを実行するときは、Amazon Elastic Container Registry に保存されている Docker 公式イメージのコピーをプルすることをお勧めします。Amazon ECR は2021 年からこれらのイメージを保存しています。人気の高いコンテナイメージは [Amazon ECR Public Gallery](https://gallery.ecr.aws/) で検索でき、中でも Docker Hub イメージは [Amazon ECR Docker Gallery](https://gallery.ecr.aws/docker/) で検索できます。
#### コンテナの実行
コンテナは標準フォーマットで構築されているため、コンテナランタイム (Docker など) を実行でき、コンテンツがローカルマシンのアーキテクチャ (`x86_64` や `arm` など) に一致するマシンであれば、どのマシンでもコンテナを実行できます。コンテナをテストしたり、ローカルのデスクトップで実行したりするには `docker run` または `podman run` コマンドを使用して、ローカルホストでコンテナを起動します。ただし Kubernetes では、各ワーカーノードにコンテナランタイムがデプロイされており、そのノードにコンテナの実行をリクエストするかどうかは Kubernetes が決定します。
コンテナがノード上で実行されるように割り当てられると、そのノードはリクエストされたバージョンのコンテナイメージがノード上にすでに存在するかどうかを確認します。存在しなければ、Kubernetes がコンテナランタイムに対して、適切なコンテナレジストリからそのコンテナをプルしてローカルで実行するように指示します。*コンテナイメージ* とは、ノートパソコン、コンテナレジストリ、Kubernetes ノード間を移動するソフトウェアパッケージのことです。*コンテナ* とはそのイメージの実行中のインスタンスを指します。
### ポッド
コンテナの準備が整ったら、ポッドの操作として、ポッドの設定、デプロイ、ポッドをアクセス可能にするなどの作業を行います。
#### ポッドの設定
ポッドを定義するときは一連の属性をポッドに割り当てます。これらの属性には少なくともポッド名と実行するコンテナイメージが含まれている必要があります。ただし、ポッドの定義を使用して設定する必要のある項目は他にも多数あります (ポッドに追加できる内容の詳細については「[PodSpec](https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#PodSpec)」のページを参照してください)。具体的には次のとおりです。
+ **ストレージ** - 実行中のコンテナを停止して削除すると、より永続的なストレージを設定しない限り、そのコンテナ内のデータストレージは削除されます。Kubernetes は、多種多様なストレージタイプをサポートしており、[Volumes](https://kubernetes.io/docs/concepts/storage/volumes/) の制御の下でタイプを抽出します。ストレージタイプには[CephFS](https://kubernetes.io/docs/concepts/storage/volumes/#cephfs)、[NFS](https://kubernetes.io/docs/concepts/storage/volumes/#nfs)、[iSCSI](https://kubernetes.io/docs/concepts/storage/volumes/#iscsi) などがあります。ローカルのコンピュータから [ローカルブロックデバイス](https://kubernetes.io/docs/concepts/storage/volumes/#local) を使用することもできます。クラスターからこれらのストレージタイプのいずれかを使用すれば、ストレージボリュームをコンテナのファイルシステム内の選択したマウントポイントにマウントできます。[永続ボリューム](https://kubernetes.io/docs/concepts/storage/persistent-volumes/) はポッドが削除された後も残り、[エフェメラルボリューム](https://kubernetes.io/docs/concepts/storage/ephemeral-volumes/) はポッドが削除されると、削除されます。クラスター管理者がクラスター用に異なる [ストレージクラス](https://kubernetes.io/docs/concepts/storage/storage-classes/) を作成した場合、使用後にボリュームを削除するか、再利用するか、スペースがさらに必要になった場合に拡張するか、また、特定のパフォーマンス要件を満たすようにするかなど、使用するストレージの属性を選択できることがあります。
+ **シークレット** - ポッド仕様のコンテナで [シークレット](https://kubernetes.io/docs/concepts/configuration/secret/) を使用できるようにすると、ファイルシステム、データベース、その他保護されているアセットにアクセスするために必要な許可をそれらのコンテナに付与できます。キー、パスワード、トークンはシークレットとして保存できるアイテムです。シークレットを使用すると、この情報をコンテナイメージに保存する必要はなく、実行中のコンテナでシークレットを利用できるようにすることができます。シークレットに似ているのが [ConfigMaps](https://kubernetes.io/docs/concepts/configuration/configmap/) です。`ConfigMap` には一般に、サービスを設定するためのキーと値のペアなど、重要度が低い情報が格納されます。
+ **コンテナリソース** - コンテナを詳細に設定するためのオブジェクトはリソース設定の形式をとることができます。コンテナごとに、そのコンテナが使用できるメモリと CPU の量をリクエストできるほか、コンテナが使用できるリソースの合計量の上限を設定できます。例については「[Resource Management for Pods and Containers](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/)」を参照してください。
+ **中断** - ポッドは意図せずに (ノードがダウンしたとき)、または意図的に (アップグレードが必要なとき) 中断することがあります。[ポッド中断の予算](https://kubernetes.io/docs/concepts/workloads/pods/disruptions/#pod-disruption-budgets) を設定することで、中断が起きた場合のアプリケーションの可用性をある程度制御することができます。アプリケーションの例については「[中断予算の指定](https://kubernetes.io/docs/tasks/run-application/configure-pdb/)」を参照してください。
+ **名前空間** - Kubernetes には、Kubernetes コンポーネントとワークロードを互いに分離するさまざまな方法が用意されています。特定のアプリケーションのすべてのポッドを、同じ [名前空間](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/) で実行することはそれらのポッドをまとめて保護し管理する一般的な方法です。独自の名前空間を作成して使用することも、名前空間を指定しない (Kubernetes が `default` の名前空間を使用する) ように選択することもできます。Kubernetes コントロールプレーンコンポーネントは通常、[kube-system](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/) 名前空間で動作します。
これらの設定は通常、YAML ファイルにまとめて一緒に Kubernetes クラスターに適用します。パーソナルな Kubernetes クラスターの場合は、これらの YAML ファイルをローカルシステムに保存します。ただし、よりクリティカルなクラスターやワークロードの場合は、ストレージを自動化し、ワークロードと Kubernetes インフラストラクチャリソースの両方を更新する方法として、[GitOps](https://www.eksworkshop.com/docs/automation/gitops/) がよく使用されます。
ポッド情報の収集とデプロイに使用されるオブジェクトは以下のデプロイ方法のいずれかによって定義されます。
#### ポッドのデプロイ
ポッドをデプロイする際に選択すべき方法はそのポッドで実行する予定のアプリケーションのタイプに応じて異なります。この方法には以下のようなものがあります。
+ **ステートレスアプリケーション** - ステートレスアプリケーションはクライアントのセッションデータを保存しないため、その次のセッションは前のセッションで起きたことを参照する必要がありません。これにより、ポッドが異常な状態になった場合は新しいポッドと交換するか、状態を保存せずにポッドを移動させるだけで済みます。ステートレスアプリケーション (ウェブサーバーなど) を実行している場合は [Deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/) を使用して [Pods](https://kubernetes.io/docs/concepts/workloads/pods/) と [ReplicaSets](https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/) をデプロイできます。ReplicaSet は同時に実行したいポッドのインスタンス数を定義します。ReplicaSet は直接実行することもできますが、1 回に実行するポッドのレプリカの数を定義するため、デプロイ内でレプリカを直接実行するのが一般的です。
+ **ステートフルアプリケーション** - ステートフルアプリケーションとはポッドの ID とポッドの起動順序が重要であるアプリケーションのことです。これらのアプリケーションには安定した永続的ストレージが必要であり、一貫した方法でデプロイしスケールインする必要があります。Kubernetes にステートフルアプリケーションをデプロイするには、[StatefulSets](https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/) を使用します。通常、StatefulSet として実行されるアプリケーションの一例が、データベースです。StatefulSet 内ではレプリカ、ポッドとそのコンテナ、マウントするストレージボリューム、データを保存するコンテナ内の場所を定義できます。ReplicaSet としてデプロイされるデータベースの例については「[レプリケートされたステートフル アプリ](https://kubernetes.io/docs/tasks/run-application/run-replicated-stateful-application/)」を参照してください。
+ **ノードあたりのアプリケーション** - アプリケーションを Kubernetes クラスター内のすべてのノードで実行しなければならない場合があります。例えば、データセンターで、すべてのコンピュータでモニタリングアプリケーションまたは特定のリモートアクセスサービスを実行する必要がある場合です。Kubernetes では、[DaemonSet](https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/) を使用することで、選択したアプリケーションがクラスター内のすべてのノードで実行されるようにすることができます。
+ **完了まで実行するアプリケーション** - 特定のタスクを完了するために、複数のアプリケーションを実行する必要がある場合があります。例えば、毎月のステータスレポートを実行したり、古いデータを消去したりする場合です。[Job](https://kubernetes.io/docs/concepts/workloads/controllers/job/) オブジェクトを使用すると、アプリケーションを起動して実行し、タスクが完了したら、終了するように設定することができます。[CronJob](https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/) オブジェクトを使用すると、Linux の [crontab](https://man7.org/linux/man-pages/man5/crontab.5.html) 形式で定義された構造を使用して、特定の時間、分、日、月、曜日に、アプリケーションを実行するように設定できます。
#### ネットワークからアプリケーションにアクセスできるようにする
アプリケーションはさまざまな場所を移動するマイクロサービスのセットとしてデプロイされることが多いため、Kubernetes にはそれらのマイクロサービスが相互に検索できる方法が必要でした。また、Kubernetes クラスターの外にあるアプリケーションにアクセスするユーザーのために、Kubernetes にはそのアプリケーションを外部のアドレスとポートで公開する方法が必要でした。これらのネットワーク関連の機能はそれぞれ サービス オブジェクトと イングレス オブジェクトを使って実行されます。
+ **サービス** - ポッドは異なるノードやアドレスに移動できるため、最初のポッドと通信する必要のある別のポッドがそのポッドの場所を特定することが困難になる場合があります。この問題を解決するため、Kubernetes ではアプリケーションを [Service](https://kubernetes.io/docs/concepts/services-networking/service/) として表すことができます。サービス を使用すると、特定の名前を持つポッドまたはポッドのセットを識別し、そのアプリケーションのサービスをポッドから公開するポートと、他のアプリケーションがそのサービスにアクセスする際に使用できるポートを指定することができます。クラスター内の別の Pod は名前で Service をリクエストでき、Kubernetes はそのリクエストをその Service を実行している Pod のインスタンスの適切なポートに転送します。
+ **イングレス** – [イングレス](https://kubernetes.io/docs/concepts/services-networking/ingress/)は、Kubernetes Service によって表されたアプリケーションをクラスター外のクライアントから利用できるようにします。イングレス の基本機能にはロードバランサー (イングレス が管理)、イングレス コントローラー、コントローラーから サービス にリクエストを送信するルールなどがあります。Kubernetes で選択できる[イングレスコントローラー](https://kubernetes.io/docs/concepts/services-networking/ingress-controllers/)がいくつかあります。
## 次のステップ
Kubernetes の基本的な概念と、それらが Amazon EKS とどのように関連するのかを理解することで、[Amazon EKS ドキュメント](https://docs.aws.amazon.com/eks/)と [Kubernetes のドキュメント](https://kubernetes.io/docs)の両方を参照しながら、Amazon EKS クラスターを管理したりワークロードをクラスターにデプロイしたりする際に必要になる情報をすぐに見つけられるようになります。Amazon EKS の使用を開始するには以下から選択してください。
+ [Amazon EKS – `eksctl` の使用を開始する](getting-started-eksctl.md)
+ [Amazon EKS クラスターを作成します。](create-cluster.md)
+ [Linux サンプルアプリケーションをデプロイする](sample-deployment.md)
+ [クラスターリソースを整理およびモニタリングする](eks-managing.md)