Spark ユーザーおよびジョブのアクティビティをモニタリングするためのユーザー偽装の有効化
EMR Notebooks では、Spark クラスターでユーザー偽装を設定することができます。この機能を使用すると、ノートブックエディタ内から開始されたジョブのアクティビティを追跡できます。また、EMR Notebooks には組み込みの Jupyter Notebook ウィジェットがあり、Spark のジョブの詳細とクエリの出力をノートブックエディタで確認できます。ウィジェットはデフォルトで使用可能で、特別な設定は必要ありません。ただし、履歴サーバーを表示するには、プライマリノードにホストされている Amazon EMR ウェブインターフェイスを表示するようにクライアントを設定する必要があります。
注記
EMR Notebooks は、コンソールで EMR Studio Workspace として使用できます。コンソールの [ワークスペースの作成] ボタンを使用すると、新しいノートブックを作成できます。EMR Notebooks ユーザーが Workspace にアクセスしたり作成したりするには、追加の IAM ロール権限が必要です。詳細については、「Amazon EMR Notebooks are Amazon EMR Studio Workspaces in the console」および「Amazon EMR console」を参照してください。
Spark ユーザー偽装の設定
デフォルトでは、ノートブックエディタを使用してユーザーが送信する Spark ジョブは、不明瞭な livy ユーザー ID から発生しているように見えます。クラスターにユーザー偽装を設定して、代わりに、それらのジョブをコードを実行したユーザー ID に関連付けることができます。プライマリノードの HDFS ユーザーディレクトリは、ノートブックでコードを実行する各ユーザー ID に対して作成されます。例えば、ユーザー NbUser1 がノートブックエディタからコードを実行する場合、プライマリノードに接続して、hadoop fs -ls /user がディレクトリ /user/user_NbUser1 を示していることを確認できます。
core-site および livy-conf の設定分類でプロパティを設定して、この機能を有効にします。この機能は、Amazon EMR でクラスターと共にノートブックを作成する場合、デフォルトでは使用できません。アプリケーションをカスタマイズするための設定分類の使用の詳細については、「Amazon EMR リリース ガイド」の「アプリケーションの設定」を参照してください。
EMR Notebooks のユーザー偽装を有効にするには、次の設定分類と値を使用します。
[ { "Classification": "core-site", "Properties": { "hadoop.proxyuser.livy.groups": "*", "hadoop.proxyuser.livy.hosts": "*" } }, { "Classification": "livy-conf", "Properties": { "livy.impersonation.enabled": "true" } } ]
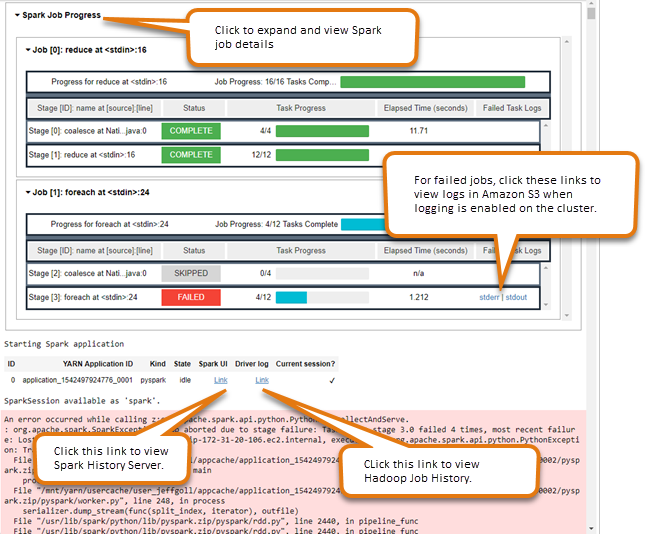
Spark ジョブモニタリングウィジェットの使用
EMR クラスター上で Spark ジョブを実行するノートブックエディタでコードを実行する場合、出力には Spark ジョブモニタリングの Jupyter Notebook が含まれます。ウィジェットには、ジョブの詳細と、Spark の履歴サーバーページや Hadoop のジョブ履歴ページへの便利なリンクの他に、失敗したジョブに関する Amazon S3 内のジョブログへの便利なリンクがあります。
クラスタープライマリノードで履歴サーバーのページを表示するには、必要に応じて SSH クライアントとプロキシをセットアップする必要があります。詳細については、「Amazon EMR クラスターでホストされているウェブインターフェイスを表示する」を参照してください。Amazon S3 内のログを表示するには、クラスターのログ記録を有効にする必要があります。この設定は新しいクラスターではデフォルトです。詳細については、「Amazon S3 にアーカイブされたログファイルを表示する」を参照してください。
以下は Spark ジョブモニタリングの例です。