翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon のマネージドスケーリングメトリクスについて EMR
Amazon EMR は、クラスターでマネージドスケーリングが有効になっている場合、1 分単位でデータを含む高解像度メトリクスを発行します。Amazon EMRコンソールまたは Amazon console. CloudWatch metrics を使用して、マネージドスケーリングによって制御されるすべてのサイズ変更の開始と完了のイベントを表示できます CloudWatch 。Amazon EMRマネージドスケーリングが動作するには、メトリクスが不可欠です。 CloudWatch メトリクスを注意深くモニタリングして、データが欠落していないことを確認することをお勧めします。欠落しているメトリクスを検出するように CloudWatch アラームを設定する方法の詳細については、「Amazon CloudWatch アラームの使用」を参照してください。Amazon での CloudWatch イベントの使用の詳細についてはEMR、「イベントのモニタリング CloudWatch」を参照してください。
次のメトリクスは、クラスターの現在の容量またはターゲットの容量を示します。これらのメトリクスは、マネージドスケーリングが有効になっている場合にのみ使用できます。インスタンスフリートで構成されるクラスターの場合、クラスター容量のメトリクスは Units 単位で測定されます。インスタンスグループで構成されるクラスターの場合、クラスター容量のメトリクスは、マネージドスケーリングポリシーで使用される単位タイプに基づき、Nodes 単位または vCPU 単位で測定されます。
| メトリクス | 説明 |
|---|---|
|
マネージドスケーリングによって決定されるクラスターunits/nodes/vCPUs内の のターゲット合計数。 単位: Count |
|
実行中のクラスターでunits/nodes/vCPUs使用可能な の現在の合計数。クラスターのサイズ変更がリクエストされると、クラスターに新しいインスタンスが追加または削除された後に、このメトリクスが更新されます。 単位: Count |
|
マネージドスケーリングによって決定されるクラスターCOREunits/nodes/vCPUs内の のターゲット数。 単位: Count |
|
クラスターでCOREunits/nodes/vCPUs現在実行されている の数。 単位: Count |
|
マネージドスケーリングによって決定されるクラスターTASKunits/nodes/vCPUs内の のターゲット数。 単位: Count |
|
クラスターでTASKunits/nodes/vCPUs現在実行されている の数。 単位: Count |
次のメトリクスは、クラスターとアプリケーションの使用状況を示します。これらのメトリクスはすべての Amazon EMR機能で使用できますが、クラスターでマネージドスケーリングが有効になっている場合、1 分単位でデータを使用して高解像度で公開されます。以下のメトリクスを前の表のクラスター容量メトリクスと関連付けることで、マネージドスケーリングの決定について理解することができます。
| メトリクス | 説明 |
|---|---|
|
|
に送信されたYARN、完了したアプリケーションの数。 ユースケース:クラスターの進捗状況を監視する 単位: Count |
|
|
に送信されたYARN、保留中の状態のアプリケーションの数。 ユースケース:クラスターの進捗状況を監視する 単位: Count |
|
|
に送信された実行中YARNのアプリケーションの数。 ユースケース:クラスターの進捗状況を監視する 単位: Count |
ContainerAllocated |
によって割り当てられたリソースコンテナの数ResourceManager。 ユースケース:クラスターの進捗状況を監視する 単位: Count |
|
|
キュー内にあり、まだ割り当てられていないコンテナの数。 ユースケース:クラスターの進捗状況を監視する 単位: Count |
ContainerPendingRatio |
割り当てられたコンテナに対する保留中のコンテナの比率 (ContainerPendingRatio = ContainerPending / ContainerAllocated)。If ContainerAllocated = 0, then ContainerPendingRatio = ContainerPending。の値は、パーセンテージではなく数値 ContainerPendingRatio を表します。この値は、コンテナ割り当て動作に基づくクラスターリソースのスケーリングに役立ちます。 単位: Count |
|
|
現在使用されているHDFSストレージの割合。 ユースケース:クラスターのパフォーマンスを分析する 単位: パーセント |
|
|
クラスターが作業を行っていないが、まだ有効で課金されていることを示します。タスクもジョブも実行されていない場合は 1 に設定され、それ以外の場合は 0 に設定されます。この値は 5 分間隔で確認され、値が 1 の場合は、確認時にクラスターがアイドル状態だったことのみを示します。5 分間ずっとアイドル状態だったことを示すわけではありません。誤検出を避けるには、5 分ごとの確認で複数回連続してこの値が 1 である場合に通知するように、アラームを指定する必要があります。たとえば、30 分間にわたってこの値が 1 だった場合に通知するようアラームを指定できます。 ユースケース:クラスターのパフォーマンスを監視する 単位: ブール |
|
|
割り当てに使用できるメモリの量。 ユースケース:クラスターの進捗状況を監視する 単位: Count |
|
|
現在実行中の MapReduce タスクまたはジョブのノード数。YARN メトリクス に相当します ユースケース:クラスターの進捗状況を監視する 単位: Count |
|
|
使用可能な残りのメモリの割合 YARN (YARNMemoryAvailablePercentage = MemoryAvailableMB/MemoryTotalMB)。この値は、YARNメモリ使用量に基づいてクラスターリソースをスケーリングするのに役立ちます。 単位: パーセント |
次のメトリクスは、YARNコンテナとノードで使用されるリソースに関する情報を提供します。YARN リソースマネージャーのこれらのメトリクスは、クラスターで実行されているコンテナとノードが使用するリソースに関するインサイトを提供します。これらのメトリクスを前のテーブルのクラスター容量メトリクスと比較すると、マネージドスケーリングの影響をより明確に把握できます。
| メトリクス | 関連リリース | 説明 |
|---|---|---|
|
|
リリースラベル 7.3.0 以降で使用可能 |
発行期間に消費されたコンテナメモリ * 秒。 単位: GB * 秒 |
|
|
リリースラベル 7.3.0 以降で使用可能 |
公開期間の合計ヤーンコンテナ * 秒。 単位: GB * 秒 |
|
|
リリースラベル 7.5.0 以降で使用可能 |
発行期間に消費されたコンテナ VCPU * 秒。 単位: VCPU * 秒 |
|
リリースラベル 7.5.0 以降で使用可能 |
公開期間の合計コンテナ VCPU * 秒。 単位: VCPU * 秒 |
|
|
リリースラベル 7.5.0 以降で使用可能 |
発行期間に消費されたノードメモリ * 秒。 単位: GB * 秒 |
|
リリースラベル 7.5.0 以降で使用可能 |
発行期間の合計ノードメモリ * 秒。 単位: GB * 秒 |
|
|
リリースラベル 7.3.0 以降で使用可能 |
発行期間に消費されたノード VCPU * 秒。 単位: VCPU * 秒 |
|
|
リリースラベル 7.3.0 以降で使用可能 |
発行期間の合計ノード VCPU * 秒。 単位: VCPU * 秒 |
マネージドスケーリングメトリクスをグラフ化する
メトリクスをグラフ化して、次の手順で示すように、クラスターのワークロードパターンと、Amazon EMRマネージドスケーリングによって行われた対応するスケーリングの決定を視覚化できます。
CloudWatch コンソールでマネージドスケーリングメトリクスをグラフ化するには
-
CloudWatch コンソール
を開きます。 -
ナビゲーションペインで、Amazon EMRを選択します。モニタリングするクラスターのクラスター識別子を検索できます。
-
グラフ化するメトリクスまでスクロールダウンします。グラフを表示するメトリクスを開きます。
-
1 つ以上のメトリクスをグラフ化するには、各メトリクスの横にあるチェックボックスを選択します。
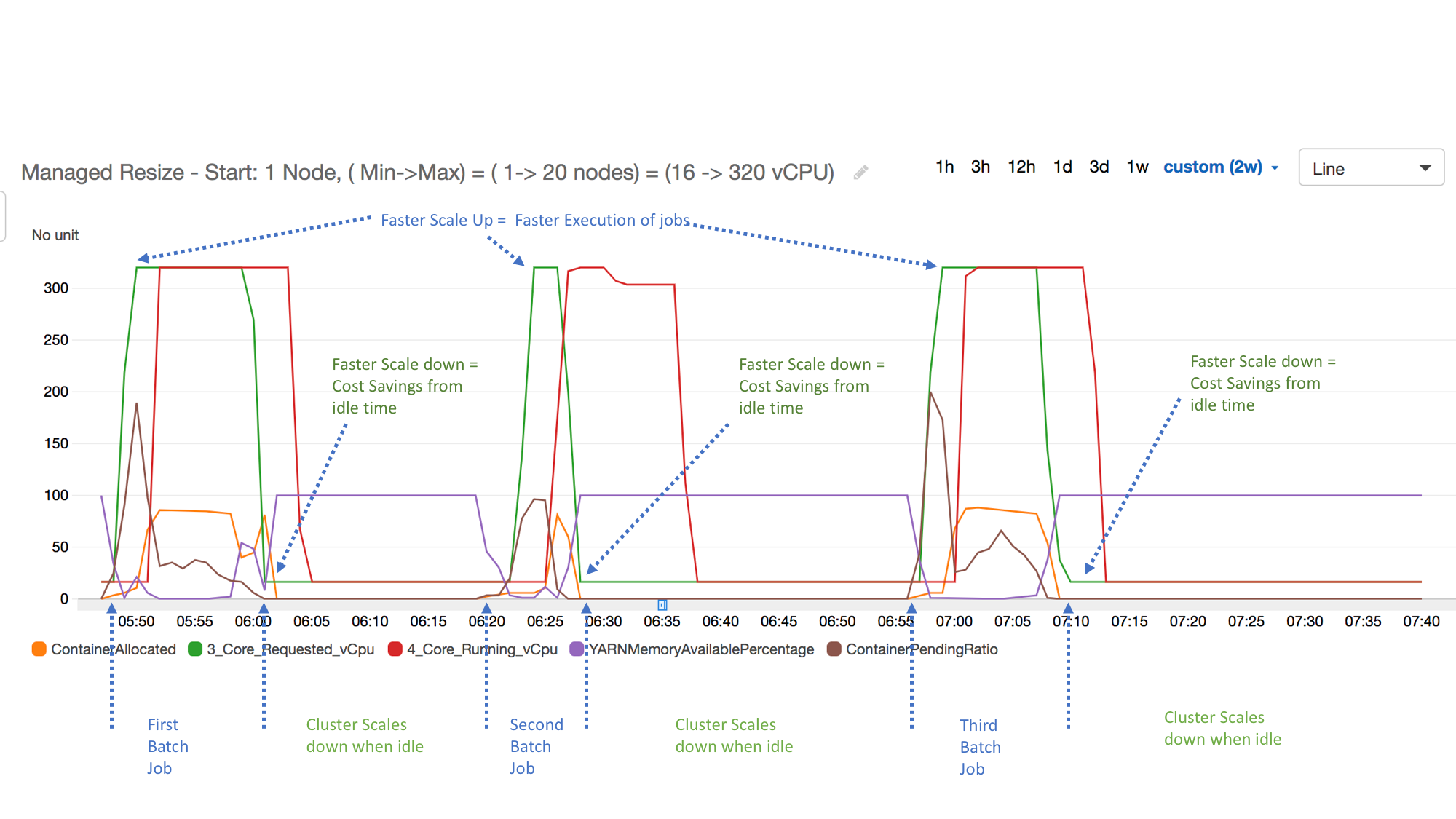
次の例は、クラスターの Amazon EMRマネージドスケーリングアクティビティを示しています。グラフには、アクティブ度の低いワークロードがある場合にコストを節約する、3 つの自動スケールダウン期間が示されています。
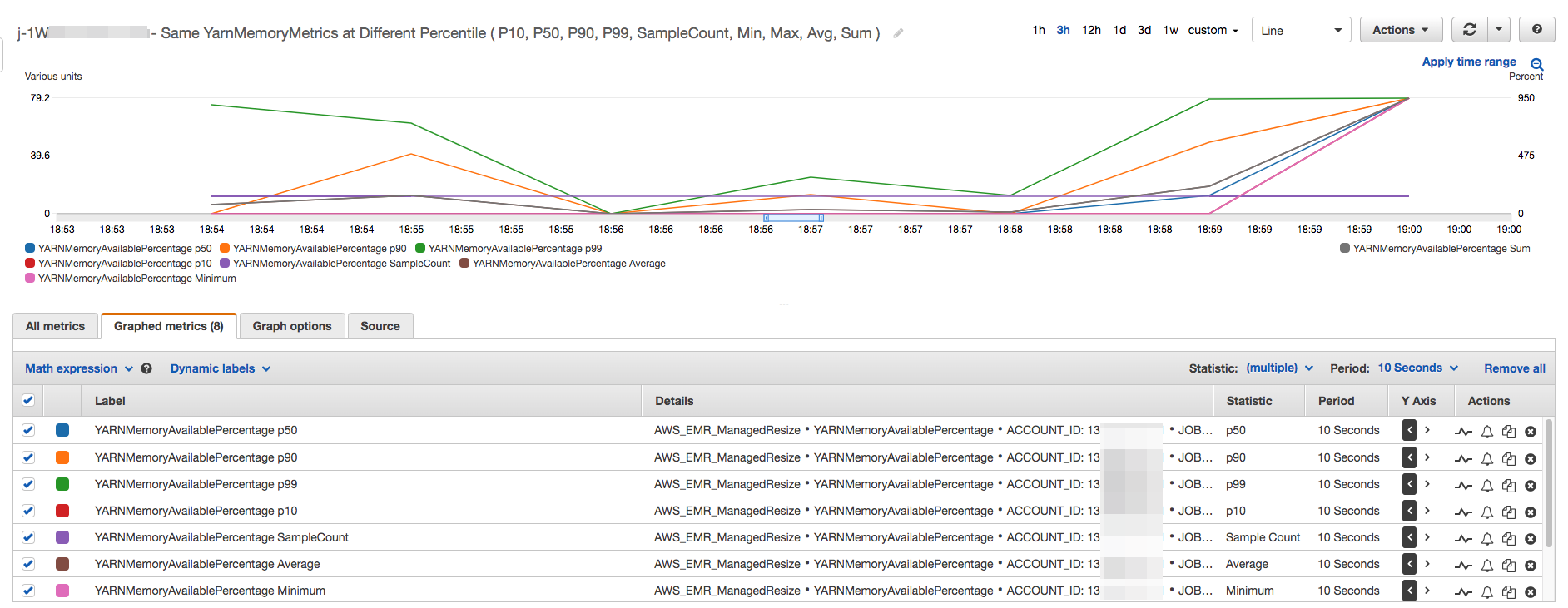
すべてのクラスターの容量および使用率のメトリクスが、1 分間隔で公開されます。各 1 分間データには追加の統計情報も関連付けられており、Percentiles、Min、Max、Sum、Average、SampleCount などさまざまな関数に使用できます。
たとえば、次のグラフでは、Sum、Average、Min、SampleCount とともに、同じ YARNMemoryAvailablePercentage メトリクスが異なるパーセンタイル (P10、P50、P90、P99) で描画されます。