翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Iceberg の仕組み
Iceberg は個々のデータファイルをディレクトリではなくテーブルで追跡します。これにより、作成者はデータファイルを作成するだけですみます (ファイルの移動や変更はありません)。また、作成者は明示的なコミットでのみテーブルにファイルを追加できます。テーブルの状態はメタデータファイルで管理されます。テーブル状態を変更すると、古いメタデータをアトミックに置き換える新しいメタデータファイルが作成されます。テーブルメタデータファイルでは、テーブルスキーマ、パーティショニング設定、その他のプロパティが追跡されます。
テーブルコンテンツのスナップショットも含まれています。各スナップショットは、ある時点におけるテーブル内のデータファイルの完全なセットです。スナップショットはメタデータファイルにリスト化されますが、スナップショット内のファイルは別のマニフェストファイルに保存されます。あるテーブルメタデータファイルから次のテーブルメタデータファイルへのアトミックな移行により、スナップショットが分離されます。読み込みでは、テーブルメタデータをロードした時点の最新のスナップショットを使用します。また、更新して新しいメタデータの場所を取得するまで、変更の影響を受けません。スナップショット内のデータファイルは 1 つまたは複数のマニフェストファイルに保存されます。マニフェストファイルには、テーブル内の各データファイル、そのパーティションデータとメトリクスが 1 行ずつ格納されます。スナップショットは、マニフェスト内のすべてのファイルをまとめたものです。また、マニフェストファイルはスナップショット間で共有できるため、変更頻度の低いメタデータを書き換える必要がありません。
Iceberg スナップショットの図
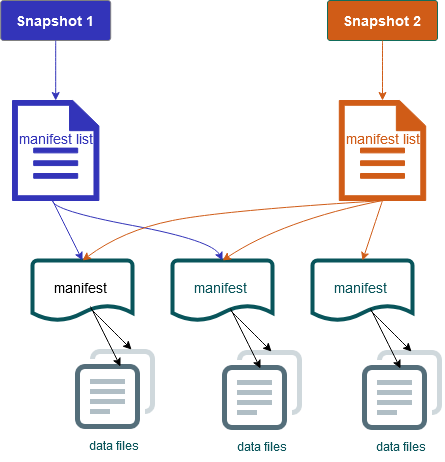
Iceberg には以下の機能があります。
-
Amazon S3 データレイクでのACIDトランザクションとタイムトラベルをサポートします。
-
コミットの再試行には、オプティミスティック同時実行
のパフォーマンス上の利点が活かされます。 -
ファイルレベルの競合解決により、高い同時実行性が実現します。
-
メタデータの列ごとの最小/最大統計を使用すると、ファイルをスキップできるため、選択的クエリのパフォーマンスが向上します。
-
テーブルを柔軟なパーティションレイアウトに整理でき、パーティションの進化によりパーティションスキームを更新できます。これにより、クエリやデータの量を物理ディレクトリに依存せずに変更できます。
-
スキーマ進化
と適用をサポートします。 -
Iceberg テーブルは冪等性シンクと再生可能なソースとして機能します。これにより、1 回限りのパイプラインによるストリーミングとバッチサポートが可能になります。冪等性シンクは、過去に成功した書き込み操作を追跡します。そのため、シンクは障害が発生した場合はデータを再度要求し、複数回送信された場合はデータをドロップできます。
-
テーブル進化、操作履歴、各コミットの統計など、履歴と系統を表示します。
-
データ形式 (Parquet、、Avro) と分析エンジン (SparkORC、Trino、PrestoDB、Hive) を選択して既存のデータセットから移行します。
