Amazon EMR で Flink を設定する
Hive Metastore と Glue Catalog を使用して Flink を設定する
Amazon EMR リリース 6.9.0 以降は、Hive Metastore と AWS Glue Catalog の両方をサポートし、Hive に接続する Apache Flink コネクタにも対応しています。このセクションでは、AWS Glue Catalog と Hive Metastore を Flink で使用するために必要な手順について概説します。
Hive Metastore を使用する
-
リリース 6.9.0 以降の EMR でクラスターを作成し、少なくとも 2 つのアプリケーション (Hive と Flink) を使用します。
-
スクリプトランナーを使用して、次のスクリプトをステップ関数として実行します。
hive-metastore-setup.shsudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar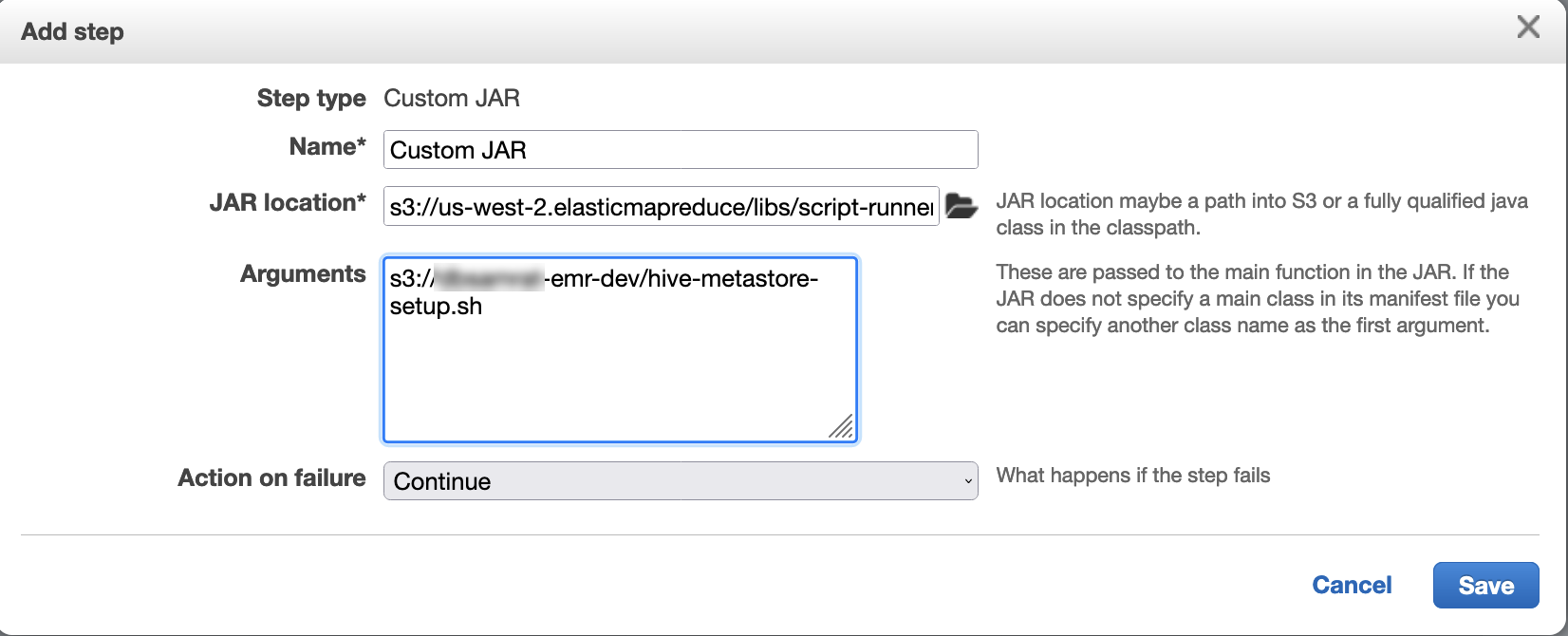
AWS Glue Data Catalog を使用する
-
リリース 6.9.0 以降の EMR でクラスターを作成し、少なくとも 2 つのアプリケーション (Hive と Flink) を使用します。
-
AWS Glue Data Catalog の設定にある [Hive テーブルメタデータに使用] を選択して、クラスターでデータカタログを有効にします。
-
スクリプトランナーを使用して、次のスクリプトをステップ関数として実行します (「Amazon EMR クラスターでのコマンドとスクリプトの実行」を参照).
glue-catalog-setup.sh
sudo cp /usr/lib/hive/auxlib/aws-glue-datacatalog-hive3-client.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/aws-glue-datacatalog-hive3-client.jar sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar
設定ファイルを使用して Flink を構成する
Amazon EMR 設定 API と設定ファイルを使用して、Flink を構成できます。API 内で設定可能なファイルは次のとおりです。
-
flink-conf.yaml -
log4j.properties -
flink-log4j-session -
log4j-cli.properties
flink-conf.yaml は、Flink の主要な設定ファイルです。
Flink に使用するタスクスロットの数を AWS CLI から設定するには
-
次のコンテンツを含む
configurations.jsonファイルを作成します。[ { "Classification": "flink-conf", "Properties": { "taskmanager.numberOfTaskSlots":"2" } } ] -
次に、次の設定でクラスターを作成します。
aws emr create-cluster --release-labelemr-7.3.0\ --applications Name=Flink \ --configurations file://./configurations.json \ --regionus-east-1\ --log-uri s3://myLogUri\ --instance-type m5.xlarge \ --instance-count2\ --service-role EMR_DefaultRole_V2 \ --ec2-attributes KeyName=YourKeyName,InstanceProfile=EMR_EC2_DefaultRole
注記
Flink API でも、一部の設定を変更できます。詳細については、Flink のドキュメントで「Concepts (概念)
Amazon EMR バージョン 5.21.0 以降では、実行中のクラスター内のインスタンスグループごとに、クラスター設定を上書きして追加の設定分類を指定できます。これを行うには、Amazon EMR コンソール、AWS Command Line Interface (AWS CLI)、または AWS SDK を使用します。詳細については、「実行中のクラスター内のインスタンスグループの設定を指定する」を参照してください。
Parallelism オプション
アプリケーションの所有者であれば、Flink 内のタスクにどのリソースを割り当てるべきかを熟知しているでしょう。このドキュメントの例では、アプリケーションに使用するスレーブインスタンスと同じ数のタスクを使用します。初期レベルの並列処理では、多くの場合、そうすることをお勧めしますが、タスクスロットを使用して並列処理の粒度を高めることも可能です。ただし、一般的には、並列処理がインスタンスあたりの仮想コア
複数のプライマリノードを持つ EMR クラスターで Flink を設定する
Flink の JobManager は、複数のプライマリノードを持つ Amazon EMR クラスターでプライマリノードがフェイルオーバーしている間も引き続き使用できます。また、Amazon EMR 5.28.0 以降では、JobManager の高可用性が自動的に有効になるため、手動設定は必要ありません。
Amazon EMR バージョン 5.27.0 以前では、JobManager は単一障害点です。JobManager に障害が発生すると、すべてのジョブ状態が失われ、実行中のジョブは再開されません。以下の例に示すように、アプリケーションの試行回数およびチェックポイントを設定し、ZooKeeper を Flink のステートストレージとして有効にすることで、JobManager の高可用性を有効にできます。
[ { "Classification": "yarn-site", "Properties": { "yarn.resourcemanager.am.max-attempts": "10" } }, { "Classification": "flink-conf", "Properties": { "yarn.application-attempts": "10", "high-availability": "zookeeper", "high-availability.zookeeper.quorum": "%{hiera('hadoop::zk')}", "high-availability.storageDir": "hdfs:///user/flink/recovery", "high-availability.zookeeper.path.root": "/flink" } } ]
YARN の最大アプリケーションマスター試行回数と Flink のアプリケーション試行回数の両方を設定する必要があります。詳細については、「YARN クラスターの高可用性の設定
メモリプロセスサイズの設定
Flink 1.11.x を使用する Amazon EMR の各バージョンでは、JobManager (jobmanager.memory.process.size) と TaskManager (taskmanager.memory.process.size) の両方について、flink-conf.yaml で合計メモリプロセスサイズを設定する必要があります。これらの値を設定するには、設定 API を使用してクラスターを設定するか、SSH を介してこれらのフィールドのコメントを手動で解除します。Flink には、次のデフォルト値が設定されています。
-
jobmanager.memory.process.size: 1600m -
taskmanager.memory.process.size: 1728m
JVM メタスペースとオーバーヘッドを除外する場合は、taskmanager.memory.process.size の代わりに Flink の合計メモリサイズ (taskmanager.memory.flink.size) を使用します。taskmanager.memory.process.size のデフォルト値は 1280m です。taskmanager.memory.process.size と taskmanager.memory.process.size の両方を設定することはお勧めしません。
Flink 1.12.0 以降を使用するいずれの Amazon EMR バージョンにも、Flink のオープンソースにリストされているデフォルト値が Amazon EMR のデフォルト値として設定されているため、自分で設定する必要はありません。
ログ出力ファイルサイズの設定
Flink アプリケーションコンテナは、.out ファイル、.log ファイル、.err ファイルの 3 種類のログファイルを作成して書き込みます。.err ファイルのみが圧縮されてファイルシステムから削除され、.log および .out ログファイルはファイルシステムに残ります。これらの出力ファイルを管理しやすく、クラスターを安定させるために、log4j.properties のログローテーションを設定して、ファイルの最大数を設定し、それらのサイズを制限できます。
Amazon EMR バージョン 5.30.0 以降
Amazon EMR 5.30.0 以降の場合、Flink では、設定分類名 flink-log4j. を持つ log4j2 ロギングフレームワークが使用されます。次の設定例は、log4j2 形式を示しています。
[ { "Classification": "flink-log4j", "Properties": { "appender.main.name": "MainAppender", "appender.main.type": "RollingFile", "appender.main.append" : "false", "appender.main.fileName" : "${sys:log.file}", "appender.main.filePattern" : "${sys:log.file}.%i", "appender.main.layout.type" : "PatternLayout", "appender.main.layout.pattern" : "%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n", "appender.main.policies.type" : "Policies", "appender.main.policies.size.type" : "SizeBasedTriggeringPolicy", "appender.main.policies.size.size" : "100MB", "appender.main.strategy.type" : "DefaultRolloverStrategy", "appender.main.strategy.max" : "10" }, } ]
Amazon EMR バージョン 5.29.0 以降
Amazon EMR バージョン 5.29.0 以前の場合、Flink では log4j ロギングフレームワークが使用されます。次の設定例は、log4j 形式を示しています。
[ { "Classification": "flink-log4j", "Properties": { "log4j.appender.file": "org.apache.log4j.RollingFileAppender", "log4j.appender.file.append":"true", # keep up to 4 files and each file size is limited to 100MB "log4j.appender.file.MaxFileSize":"100MB", "log4j.appender.file.MaxBackupIndex":4, "log4j.appender.file.layout":"org.apache.log4j.PatternLayout", "log4j.appender.file.layout.ConversionPattern":"%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n" }, } ]
Flink が Java 11 で実行されるよう設定する
Amazon EMR リリース 6.12.0 以降では、Java 11 ランタイム環境で Flink を実行できます。このセクションでは、Java 11 ランタイム環境で Flink を実行するための設定について説明します。
トピック
Java 11 で実行する Flink をクラスター作成時に設定する
Flink を Java 11 ランタイムで実行する EMR クラスターを作成するには、次の手順に従います。Java 11 ランタイム環境を使用できるようにする設定ファイルは flink-conf.yaml です。
稼働しているクラスターの Java 11 で実行されている Flink を設定する
Flink を Java 11 ランタイムで実行している稼働中の EMR クラスターを更新するには、次の手順に従います。Java 11 ランタイム環境を使用できるようにする設定ファイルは flink-conf.yaml です。
稼働中のクラスターで Flink の Java ランタイムを確認します。
稼働中のクラスターの Java ランタイムを確認するには、「SSH を使用してプライマリノードに接続する」の説明どおり、プライマリノードに SSH でログインします。次に、以下のコマンドを実行します。
ps -ef | grep flink
ps コマンドで -ef オプションを指定すると、システム上で実行中のプロセスをすべて一覧表示できます。その出力を grep でフィルタリングすると、flink の文字列が含まれる行を検索できます。Java ランタイム環境 (JRE) の値 jre-XX を出力で確認します。次の出力の jre-11 は、Flink のランタイム環境として Java 11 が選択されることを示しています。
flink 19130 1 0 09:17 ? 00:00:15 /usr/lib/jvm/jre-11/bin/java -Djava.io.tmpdir=/mnt/tmp -Dlog.file=/usr/lib/flink/log/flink-flink-historyserver-0-ip-172-31-32-127.log -Dlog4j.configuration=file:/usr/lib/flink/conf/log4j.properties -Dlog4j.configurationFile=file:/usr/lib/flink/conf/log4j.properties -Dlogback.configurationFile=file:/usr/lib/flink/conf/logback.xml -classpath /usr/lib/flink/lib/flink-cep-1.17.0.jar:/usr/lib/flink/lib/flink-connector-files-1.17.0.jar:/usr/lib/flink/lib/flink-csv-1.17.0.jar:/usr/lib/flink/lib/flink-json-1.17.0.jar:/usr/lib/flink/lib/flink-scala_2.12-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-java-uber-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-scala-bridge_2.12-1.17.0.
または、プライマリノードに SSH でログインし、コマンド flink-yarn-session -d を使用して Flink YARN セッションを開始します。次の例の出力には、Flink の Java Virtual Machine (JVM) として java-11-amazon-corretto が表示されています。
2023-05-29 10:38:14,129 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: containerized.master.env.JAVA_HOME, /usr/lib/jvm/java-11-amazon-corretto.x86_64
