Amazon Forecast は、新規顧客では利用できなくなりました。Amazon Forecast の既存のお客様は、通常どおりサービスを引き続き使用できます。詳細はこちら
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
CNN-QR アルゴリズム
Amazon Forecast CNN-QR、畳み込みニューラルネットワーク - 分位点回帰は、因果畳み込みニューラルネットワーク (CNN) を使用してスカラー (1 次元) 時系列を予測するための独自の機械学習アルゴリズムです。この教師あり学習アルゴリズムは、時系列の大規模なコレクションから 1 つのグローバルモデルをトレーニングし、分位数デコーダーを使用して確率的予測を行います。
CNN-QR の開始方法
CNN-QR を使用して予測子をトレーニングするには、次の 2 つの方法があります。
-
CNN-QR アルゴリズムを手動で選択します。
-
AutoML の選択 (CNN-QR は AutoML の一部です)。
使用するアルゴリズムがわからない場合は、AutoML を選択することをお勧めします。これにより、Forecast は、データに対して最も正確なアルゴリズムである場合に CNN-QR を選択します。CNN-QR が最も正確なモデルとして選択されたかどうかを確認するには、DescribePredictor API を使用するか、コンソールで予測子名を選択します。
CNN-QR の主なユースケースは次のとおりです。
-
大規模で複雑なデータセットを使用した予測 - CNN-QR は、大規模で複雑なデータセットを使用してトレーニングした場合に最適に機能します。ニューラルネットワークは多くのデータセットから学習できます。これは、関連する時系列と項目メタデータがある場合に役立ちます。
-
履歴の関連する時系列を使用した予測 - CNN-QR では、関連する時系列に予測期間内のデータポイントを含める必要はありません。この追加された柔軟性により、商品の価格、イベント、ウェブメトリクス、製品カテゴリなど、関連する時系列および項目メタデータを幅広く含めることができます。
CNN-QR の仕組み
CNN-QR は、確率的予測のためのシーケンス間 (Seq2Seq) モデルであり、エンコードシーケンスを条件として、予測がデコードシーケンスをどれだけ適切に再構築するかをテストします。
このアルゴリズムでは、エンコードシーケンスとデコードシーケンスでさまざまな特徴を使用できるため、エンコーダーで関連する時系列を使用し、デコーダーから除外することができます (その逆も可能です)。デフォルトでは、予測期間内のデータポイントに関連する時系列は、エンコーダーとデコーダーの両方に含まれます。予測期間にデータポイントがない関連する時系列は、エンコーダーにのみ含まれます。
CNN-QR は、学習可能な特徴抽出機能として使用できる階層的因果 CNN を使用して分位点回帰を実行します。
週末の急増などの時間依存パターンの学習を容易にするために、CNN-QR は時系列の詳細度に基づいて特徴の時系列を自動的に作成します。例えば、CNN-QR は、週に 1 回の頻度で 2 つの特徴の時系列 (月初からの日付と年初からの日付) を作成します。アルゴリズムは、このように派生した特徴の時系列を使用するだけでなく、トレーニングと推論の間にユーザーが提供するカスタムの特徴の時系列も使用します。次の例は、ターゲット時系列である zi,t と、派生した 2 つの時系列の特徴を示しています。ui,1,t はその日の時間を表し、ui,2,t はその曜日を表します。
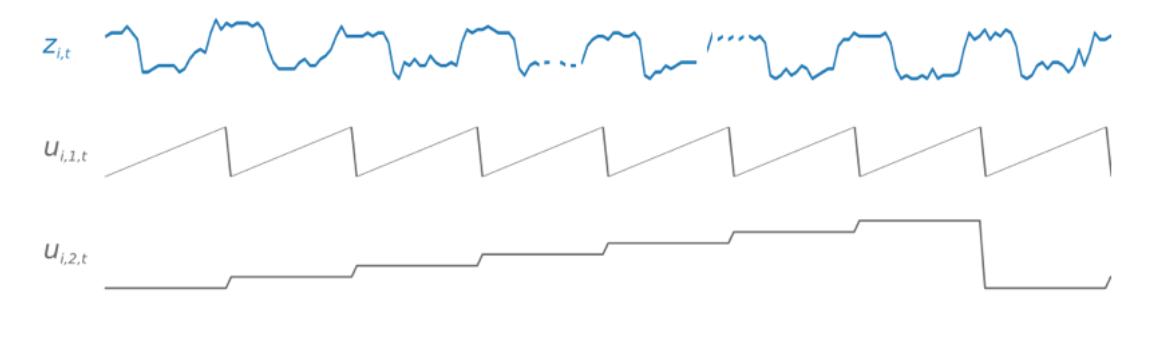
CNN-QR は、データの頻度とトレーニングデータのサイズに基づいて、これらの特徴の時系列を自動的に組み込みます。次の表に、サポートされている基本的な頻度ごとに、派生させることのできる特徴を示します。
| 時系列の頻度 | 派生する特徴 |
|---|---|
| 分 | 分、時、曜日、月初からの日付、年初からの日付 |
| 時間 | 時、曜日、月初からの日付、年初からの日付 |
| 日 | 曜日、月初からの日付、年初からの日付 |
| 週 | 月初からの週、年初からの週 |
| 月 | 月 |
トレーニング中、トレーニングデータセットの各時系列は、固定された事前定義済みの長さを持つ、隣接するコンテキストウィンドウと予測ウィンドウのペアで構成されます。これを次の図に示します。コンテキストウィンドウは緑色で表され、予測ウィンドウは青色で表されています。
特定のトレーニングセットでトレーニングされたモデルを使用すると、トレーニングセット内の時系列の予測と他の時系列の予測を生成できます。トレーニングデータセットは、関連する時系列と項目メタデータのリストに関連付けられている可能性のあるターゲット時系列で構成されています。
以下の図は、インデックス i が付されたトレーニングデータセットの要素に対してこれがどのように機能するかを示しています。トレーニングデータセットは、ターゲット時系列 zi,t、および 2 つの関連付けられた関連する時系列 xi,1,t と xi,2,t から構成されます。最初の関連する時系列である xi,1,t はフォワードルックの時系列であり、2 番目の時系列である xi,2,t は履歴時系列です。
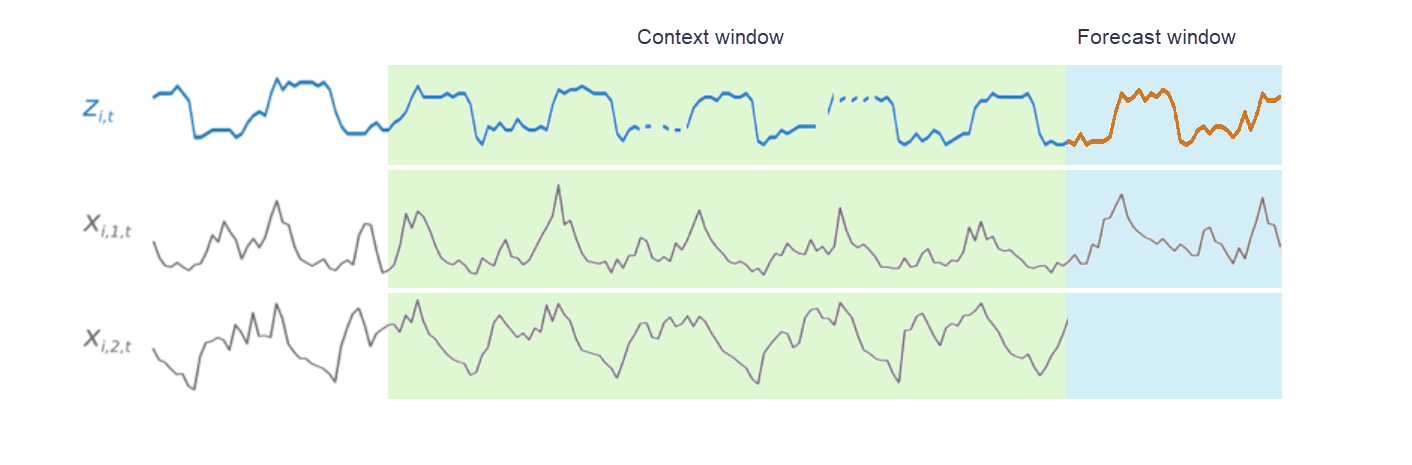
CNN-QR は、ターゲット時系列である zi,t と、関連する時系列である xi,1,t および xi,2,t を学習して、予測ウィンドウで予測を生成します。これは、オレンジ色の線で表されます。
CNN-QR での関連データの使用
CNNQR では、過去と将来の時系列データセットの両方がサポートされます。将来を見据えた関連時系列データセットを提供する場合、欠損値は将来のフィル手法を使用して埋められます。履歴およびフォワードルックの関連する時系列の詳細については、「Using Related Time Series Datasets」(関連する時系列データセットの使用) を参照してください。
CNN-QR で項目メタデータデータセットを使用することもできます。これらは、ターゲット時系列の項目に関する静的情報を含むデータセットです。項目メタデータは、履歴データがほとんどないか、まったくないコールドスタート予想シナリオで特に役立ちます。項目メタデータの詳細については、「Item Metadata」(項目メタデータ) を参照してください。
CNN-QR ハイパーパラメータ
Amazon Forecast は、選択したハイパーパラメータで CNN-QR モデルを最適化します。CNN-QR を手動で選択する場合、これらのハイパーパラメータのトレーニングパラメータを渡すオプションがあります。次の表に、CNN-QR アルゴリズムの調整可能なハイパーパラメータを示します。
| Parameter Name | 値 | 説明 |
|---|---|---|
context_length |
|
予測を生成する前にモデルが読み込む時間ポイントの数。通常、CNN-QR はそれ以上の履歴データを調べるためにラグを使用しないため、CNN-QR の
|
use_related_data |
|
モデルに含める関連する時系列データの種類を決定します。 次の 4 つのオプションのいずれかを選択します。
|
use_item_metadata |
|
モデルに項目のメタデータが含まれるかどうかを決定します。 2 つのオプションのいずれかを選択します。
|
epochs |
|
トレーニングデータの完全なパスの最大数。データセットが小さいほど、より多くのエポックが必要になります。
|
ハイパーパラメータの最適化 (HPO)
ハイパーパラメータの最適化 (HPO) は、特定の学習目標に最適なハイパーパラメータ値を選択するタスクです。Forecast を使用すると、このプロセスを 2 つの方法で自動化できます。
-
AutoML を選択すると、CNN-QR に対して HPO が自動的に実行されます。
-
CNN-QR を手動で選択して
PerformHPO = TRUEを設定します。
関連する時系列と項目のメタデータを追加しても、CNN-QR モデルの精度が常に向上するとは限りません。AutoML を実行するか、HPO を有効にすると、CNN-QR は、提供された関連する時系列と項目メタデータがある場合とない場合のモデルの精度をテストし、最も精度の高いモデルを選択します。
Amazon Forecast は、HPO 中に次の 3 つのハイパーパラメータを自動的に最適化し、最終的にトレーニングされた値を提供します。
-
context_length - ネットワークが参照できる過去の長さを決定します。HPO プロセスは、トレーニング時間を考慮しながら、モデルの精度を最大化する
context_lengthの値を自動的に設定します。 -
use_related_data - モデルに含める関連する時系列データの形式を決定します。HPO プロセスは、関連する時系列データがモデルを改善するかどうかを自動的にチェックし、最適な設定を選択します。
-
use_item_metadata - モデルに項目メタデータを含めるかどうかを決定します。HPO プロセスは、項目メタデータがモデルを改善するかどうかを自動的にチェックし、最適な設定を選択します。
注記
Holiday の補足的な特徴が選択されている場合に use_related_data が NONE もしくは HISTORICAL に設定されているときは、これは祝祭日データを含めてもモデルの精度が向上しないことを意味します。
PerformHPO = TRUE を手動選択中に設定した場合は、context_length ハイパーパラメータの HPO 構成を設定できます。ただし、AutoML を選択した場合、HPO 設定のどの側面も変更できません。HPO 設定の詳細については、IntergerParameterRange API を参照してください。
ヒントとベストプラクティス
ForecastHorizon に大きな値を使用しないようにする - ForecastHorizon に 100 を超える値を使用すると、トレーニング時間が長くなり、モデルの精度が低下する可能性があります。未来の予測をさらに生成するには、より高い頻度で情報を集約することを検討してください。たとえば、1min ではなく 5min を使用します。
CNN はより長いコンテキスト長を可能にする - CNN-QR を使用することで、context_length を DeepAR+ よりもわずかに長く設定できます。これは、CNN が一般に RNN よりも効率的であることによります。
関連データの特徴エンジニアリング - モデルをトレーニングするときに、関連する時系列と項目メタデータのさまざまな組み合わせを試して、追加情報によって精度が向上するかどうかを評価します。関連する時系列と項目のメタデータのさまざまな組み合わせと変換により、さまざまな結果が得られます。
CNN-QR は平均分位数で予測しない – CreateForecast API で ForecastTypes を mean に設定すると、代わりに分位数の中央値 (0.5 または P50) で予測が生成されます。
