Redshift 接続
AWS Glue for Spark を使用して Amazon Redshift データベース内のテーブルに対する読み込みと書き込みを行うことができます。AWS Glue は Amazon Redshift SQL の COPY および UNLOAD コマンドを使用して、Amazon S3 を介してデータを移動し、スループットを最大化します。AWS Glue 4.0 以降では、Apache Spark 用の Amazon Redshift インテグレーションを使用して、Amazon Redshift 固有の最適化と機能を使用して読み込みと書き込みを行うことができます。また、以前のバージョンで接続する場合には利用できなかった機能もあります。
AWS Glue によって Amazon Redshift ユーザーがサーバーレスデータ統合と ETL のための AWS Glue への移行がこれまでになく簡単になった方法をご覧ください。
Redshift 接続の設定
AWS Glue で Amazon Redshift クラスターを使用するには、いくつかの前提条件が必要です。
-
データベースの読み込みおよび書き込み時に一時的なストレージとして使用する Amazon S3 ディレクトリがあること。
-
Amazon Redshift クラスター、AWS Glue ジョブ、Amazon S3 ディレクトリ間の通信を可能にする Amazon VPC があること。
-
AWS Glue ジョブと Amazon Redshift クラスターに対する適切な IAM アクセス許可があること。
IAM ロールを設定する
Amazon Redshift クラスターのロールを設定する
AWS Glue ジョブと統合するため、Amazon Redshift クラスターによる Amazon S3 への読み取りおよび書き込みが可能である必要があります。これを可能にするには、接続する Amazon Redshift クラスターに IAM ロールを関連付けます。ロールには、Amazon S3 の一時ディレクトリからの読み取り、および一時ディレクトリへの書き込みを許可するポリシーが必要です。ロールには、redshift.amazonaws.com サービスで AssumeRole を許可する信頼関係が必要です。
IAM ロールを Amazon Redshift に関連付けるには
前提条件: ファイルの一時的なストレージとして使用する Amazon S3 バケットまたはディレクトリがあること。
-
Amazon Redshift クラスターに必要な Amazon S3 のアクセス許可を特定します。Amazon Redshift クラスターとの間でデータを移動する場合、AWS Glue ジョブは Amazon Redshift に対して COPY および UNLOAD ステートメントを発行します。ジョブによって Amazon Redshift のテーブルが変更された場合、AWS Glue は CREATE LIBRARY ステートメントも発行します。Amazon Redshift がこれらのステートメントを実行するために必要な特定の Amazon S3 のアクセス許可については、Amazon Redshift のドキュメント「Amazon Redshift: 他の AWS リソースにアクセスするアクセス許可」を参照してください。
IAM コンソールで、必要なアクセス許可を持つ IAM ポリシーを作成します。ポリシーの作成についての詳細は、「IAM ポリシーの作成」を参照してください。
IAM コンソールで、ロールと信頼関係を作成し、Amazon Redshift がロールを継承できるようにします。これについては、IAM のドキュメントにある「AWS のサービス用ロールの作成 (コンソール)」の手順に従ってください。
AWS サービスのユースケースを選択するように求められた場合、[Redshift - カスタマイズ可能] を選択します。
ポリシーをアタッチするように求められた場合、以前に定義したポリシーを選択します。
注記
Amazon Redshiftのロールの詳細については、Amazon Redshift のドキュメントの「ユーザーに代わって Amazon Redshift が他の AWS サービスにアクセスすることを許可する」を参照してください。
Amazon Redshift コンソールで、ロールを Amazon Redshift クラスターに関連付けます。これについては、Amazon Redshift のドキュメントに記載されている手順に従ってください。
Amazon Redshift コンソールでハイライト表示されているオプションを選択して、この設定を行えます。
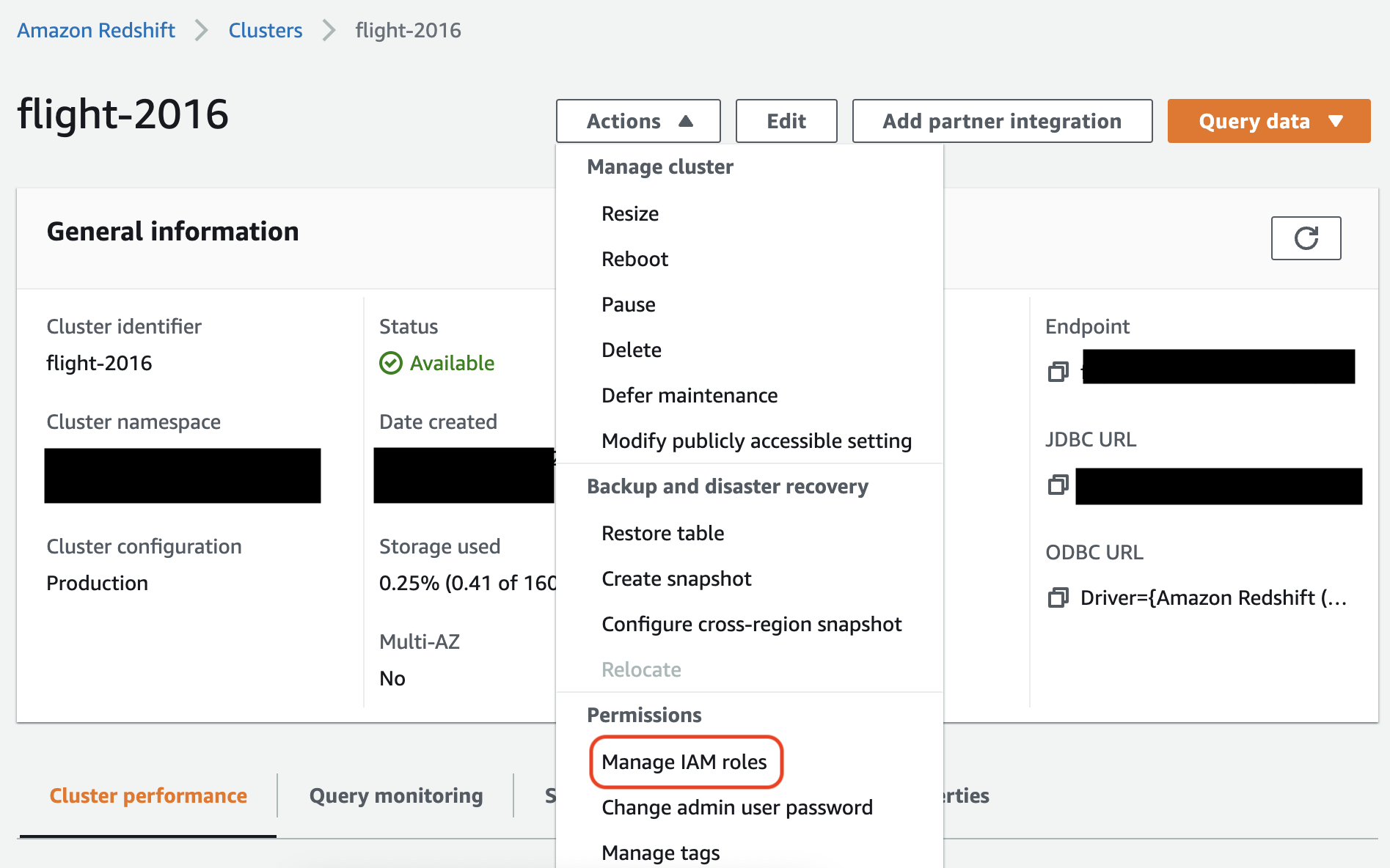
注記
AWS Glue はデフォルトで、ジョブを実行するために指定したロールを使用して作成された、Amazon Redshift の一時的な認証情報を渡します。これらの認証情報を使用することはお勧めしません。これらの認証情報は、セキュリティ上の理由により 1 時間後に失効します。
AWS Glue ジョブのロールを設定する
AWS Glue ジョブには Amazon S3 バケットにアクセスするためのロールが必要です。Amazon Redshift クラスターの IAM アクセス許可は必要ありません。アクセスは Amazon VPC の接続とデータベースの認証情報によって制御されます。
Amazon VPC を設定する
Amazon Redshift データストアへのアクセスをセットアップするには
AWS Management Consoleにサインインして、https://console.aws.amazon.com/redshiftv2/
で Amazon Redshift コンソールを開きます。 -
左のナビゲーションペインで [クラスター] を選択します。
-
AWS Glue からアクセスするクラスターの名前を選択します。
-
[Cluster Properties (クラスターのプロパティ)] セクションで、[VPC security groups (VPC セキュリティグループ)] 内のセキュリティグループを選択し、AWS Glue が使用できるようにします。今後の参照用に選択したセキュリティグループの名前を記録します。Amazon EC2 コンソールでセキュリティグループを選択すると、[Security Groups] (セキュリティグループ) の一覧が開きます。
-
変更するセキュリティグループを選択し、[Inbound (インバウンド)] タブに移動します。
-
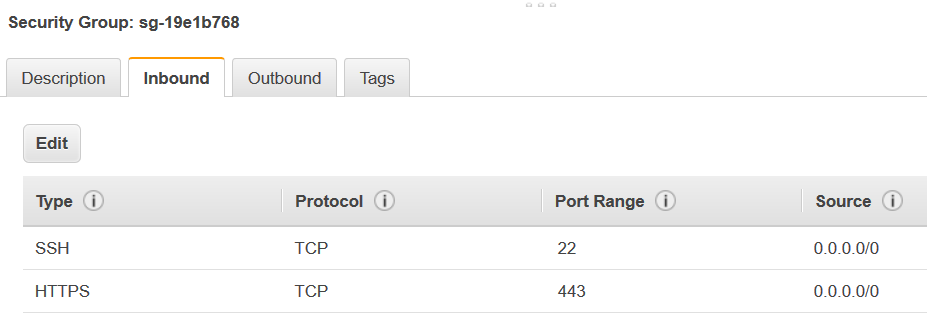
自己参照ルールを追加して、AWS Glue コンポーネントが通信できるようにします。具体的には、[Type (タイプ)]
All TCP、[Protocol (プロトコル)] はTCP、[Port Range (ポート範囲)] にはすべてのポートが含まれ、[Source (ソース)] は [Group ID (グループ ID)] と同じセキュリティグループ名であるというルールを追加または確認します。インバウンドルールは以下のようになります。
タイプ プロトコル ポート範囲 ソース すべての TCP
TCP
0~65535
database-security-group
例:
-
アウトバウンドトラフィックのルールも追加します。すべてのポートへのアウトバウンドトラフィックを開きます。以下に例を示します。
タイプ プロトコル ポート範囲 デスティネーション すべてのトラフィック
すべて
すべて
0.0.0.0/0
または、[Type (タイプ)] は
All TCP、[Protocol (プロトコル)] はTCP、[Port Range (ポート範囲)] にすべてのポートが含まれ、[Destination (宛先)] は [Group ID (グループ ID)] と同じセキュリティグループ名の自己参照ルールを作成します。Amazon S3 VPC エンドポイントを使用している場合は、Amazon S3 にアクセスするための HTTPS ルールも追加します。セキュリティグループルールには、VPC から Amazon S3 VPC エンドポイントへのトラフィックを許可するために、s3-prefix-list-idが必要です。例:
タイプ プロトコル ポート範囲 デスティネーション すべての TCP
TCP
0~65535
security-groupHTTPS
TCP
443
s3-prefix-list-id
AWS Glue をセットアップ
Amazon VPC 接続情報を提供する AWS Glue データカタログ接続を作成する必要があります。
コンソールで AWS Glue への Amazon Redshift Amazon VPC 接続を設定するには
-
「AWS Glue 接続の追加」のステップに従ってデータカタログ接続を作成します。接続を作成したら、次のステップのために接続名
connectionNameを保存しておきます。接続タイプを選択するときは、Amazon Redshift を選択します。
Redshift クラスターを選択するときは、クラスターを名前で選択します。
クラスターの Amazon Redshift ユーザーのデフォルト接続情報を指定します。
Amazon VPC 設定は自動的に設定されます。
注記
AWS SDK を使用して Amazon Redshift 接続を作成する場合は、Amazon VPC の
PhysicalConnectionRequirementsを手動で指定する必要があります。 -
AWS Glue ジョブ設定で、追加のネットワーク接続として
connectionNameを指定します。
例: Amazon Redshift テーブルからの読み取り
Amazon Redshift クラスターと Amazon Redshift Serverless 環境から読み込みを行うことができます。
前提条件: 読み込む目的の Amazon Redshift テーブルがあること。前のセクション Redshift 接続の設定 の手順を実行してください。実行後に、一時ディレクトリ temp-s3-dir および IAM ロール rs-role-name 用の Amazon S3 URI が用意されるはずです (role-account-id アカウント内)。
例: Amazon Redshift テーブルへの書き込み
Amazon Redshift クラスターと Amazon Redshift Serverless 環境に書き込みを行うことができます。
前提条件: Amazon Redshift クラスターがあり、前のセクション「Redshift 接続の設定」の手順を実行すること。実行後に、一時ディレクトリ temp-s3-dir および IAM ロール rs-role-name 用の Amazon S3 URI が用意されるはずです (role-account-id アカウント内)。また、データベースに書き込むコンテンツがある DynamicFrame も必要です。
Amazon Redshift 接続のオプションに関するリファレンス
url、user および password などの情報を設定するため、AWS Glue の JDBC 接続に使用される基本的な接続オプションはすべて、全 JDBC タイプで共通しています。JDBC のパラメータの詳細については、「JDBC 接続オプションのリファレンス」を参照してください。
Amazon Redshift 接続のタイプには、その他の接続オプションがいくつかあります。
-
"redshiftTmpDir": (必須) データベースからコピーする際に一時的なデータをステージングできる Amazon S3 パス。 -
"aws_iam_role": (オプション) IAM ロールの ARN。AWS Glue ジョブはこのロールを Amazon Redshift クラスターに渡し、ジョブの手順を完了するために必要なアクセス許可をクラスターに付与します。
AWS Glue 4.0 以降で利用可能なその他の接続オプション
新しい Amazon Redshift コネクタのオプションを、AWS Glue の接続オプションを介して渡すこともできます。サポートされているコネクタオプションの詳細なリストについては、「Apache Spark 用の Amazon Redshift の統合」の「Spark SQL パラメータ」セクションを参照してください。
参考までに、いくつかの新しいオプションをここで再度確認します。
| 名前 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| autopushdown |
不可 | TRUE | SQL オペレーションの Spark 論理プランをキャプチャして分析することにより、述語とクエリのプッシュダウンを適用します。オペレーションは SQL クエリに変換され、Amazon Redshift で実行されることでパフォーマンスが向上します。 |
| autopushdown.s3_result_cache |
不可 | FALSE | SQL クエリをキャッシュして Amazon S3 パスマッピングのデータをメモリにアンロードします。これにより、同じクエリを同じ Spark セッションで再度実行する必要がなくなります。 |
| unload_s3_format |
不可 | [PARQUET] | PARQUET - クエリ結果をパーケット形式でアンロードします。 TEXT - クエリ結果をパイプ区切りのテキスト形式でアンロードします。 |
| sse_kms_key |
不可 | 該当なし | AWS のデフォルトの暗号化の代わりに |
| extracopyoptions |
不可 | 該当なし | データロード時に Amazon Redshift これらのオプションは |
| csvnullstring (実験的) |
不可 | NULL | CSV |
これらの新しいパラメータは、次の方法で使用できます。
パフォーマンス向上のための新しいオプション
新しいコネクタには、パフォーマンス向上のための新しいオプションがいくつか導入されています。
-
autopushdown: デフォルトでは有効になっています。 -
autopushdown.s3_result_cache: デフォルトでは無効になっています。 -
unload_s3_format: デフォルトではPARQUETになっています。
これらのオプションの使用方法については、「Apache Spark 用の Amazon Redshift の統合」を参照してください。キャッシュされた結果には古い情報が含まれている可能性があるため、読み取りと書き込みのオペレーションが混在している場合は
autopushdown.s3_result_cache をオンにしないことをお勧めします。パフォーマンスを向上させ、ストレージコストを削減するために、UNLOAD コマンドの unload_s3_format オプションはデフォルトで PARQUET に設定されています。UNLOAD コマンドのデフォルト動作を使用するには、オプションを TEXT にリセットします。
読み取り用の新しい暗号化オプション
デフォルトでは、Amazon Redshift テーブルからデータを読み取る際に AWS Glue が使用する一時フォルダ内のデータは、SSE-S3 暗号化を使用して暗号化されます。AWS Key Management Service (AWS KMS) のカスタマーマネージドキーを使用してデータを暗号化するには、AWS Glue バージョン 3.0 の従来の設定オプション ("extraunloadoptions" →
s"ENCRYPTED KMS_KEY_ID '$kmsKey'") ではなく、ksmKey が AWS KMS からのキー ID になるように ("sse_kms_key"
→ kmsKey) を設定します。
datasource0 = glueContext.create_dynamic_frame.from_catalog( database = "database-name", table_name = "table-name", redshift_tmp_dir = args["TempDir"], additional_options = {"sse_kms_key":"<KMS_KEY_ID>"}, transformation_ctx = "datasource0" )
IAM ベースの JDBC URL をサポート
新しいコネクタは IAM ベースの JDBC URL をサポートしているため、ユーザーやパスワード、またはシークレットを渡す必要はありません。IAM ベースの JDBC URL では、コネクタはジョブのランタイムロールを使用して Amazon Redshift データソースにアクセスします。
ステップ 1: 次の最低限必要なポリシーを AWS Glue ジョブランタイムロールにアタッチします。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "redshift:GetClusterCredentials", "Resource": [ "arn:aws:redshift:<region>:<account>:dbgroup:<cluster name>/*", "arn:aws:redshift:*:<account>:dbuser:*/*", "arn:aws:redshift:<region>:<account>:dbname:<cluster name>/<database name>" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "redshift:DescribeClusters", "Resource": "*" } ] }
ステップ 2: IAM ベースの JDBC URL を次のように使用します。接続している Amazon Redshift ユーザー名で新しいオプション DbUser を指定します。
conn_options = { // IAM-based JDBC URL "url": "jdbc:redshift:iam://<cluster name>:<region>/<database name>", "dbtable": dbtable, "redshiftTmpDir": redshiftTmpDir, "aws_iam_role": aws_iam_role, "DbUser": "<Redshift User name>" // required for IAM-based JDBC URL } redshift_write = glueContext.write_dynamic_frame.from_options( frame=dyf, connection_type="redshift", connection_options=conn_options ) redshift_read = glueContext.create_dynamic_frame.from_options( connection_type="redshift", connection_options=conn_options )
注記
DynamicFrame は現在、GlueContext.create_dynamic_frame.from_options ワークフローに
DbUser が含まれている IAM ベースの JDBC URL のみをサポートしています。
AWS Glue バージョン 3.0 からバージョン 4.0 への移行
AWS Glue 4.0 では、さまざまなオプションと設定を搭載した新しい JDBC ドライバーや Amazon Redshift Spark コネクタに ETL ジョブでアクセスできます。新しい Amazon Redshift コネクタとドライバーはパフォーマンスを念頭に置いて作成されており、データのトランザクションの一貫性が保たれます。これらの製品については、Amazon Redshift のドキュメントに記載されています。詳細については、以下を参照してください。
テーブル/列名と識別子の制限
新しい Amazon Redshift Spark コネクタとドライバーで、Redshift テーブル名の要件が厳しくなっています。Amazon Redshift のテーブル名定義の詳細については、「名前と識別子」を参照してください。ジョブブックマークのワークフローは、ルールに一致しないテーブル名やスペースなどの特定の文字があると機能しない場合があります。
名前と識別子のルールに適合しない名前のレガシーテーブルがあり、ブックマーク (古い Amazon Redshift テーブルデータを再処理するジョブ) に問題がある場合は、テーブル名を変更することをお勧めします。詳細については、「ALTER TABLE の例」を参照してください。
データフレームのデフォルトの一時形式の変更
AWS Glue バージョン 3.0 の Spark コネクタでは、Amazon Redshift への書き込み時にデフォルトで tempformat が CSV に設定されます。一貫性を保つために、AWS Glue バージョン 3.0 でも、
DynamicFrame ではデフォルトで tempformat に CSV を使用するようになっています。以前に Amazon Redshift Spark コネクタで Spark データフレーム API を直接使用していた場合は、DataframeReader/Writer オプションで tempformat を CSV に明示的に設定できます。それ以外の場合は、新しい Spark コネクタで tempformat はデフォルトで AVRO になります。
動作の変更: Amazon Redshift データ型 REAL を Spark データ型 DOUBLE ではなく FLOAT にマッピングする
AWS Glue バージョン 3.0 では、Amazon Redshift の REAL は Spark の
DOUBLE 型に変換されます。新しい Amazon Redshift Spark コネクタでは、動作が更新され、Amazon Redshift の
REAL 型が Spark の FLOAT 型に変換されたり、その逆の変換が行われたりするようになりました。従来のユースケースで引き続き Amazon Redshift の REAL 型を Spark の DOUBLE 型にマッピングする場合は、次の回避策を使用できます。
-
DynamicFrameの場合、DynamicFrame.ApplyMappingでFloat型をDouble型にマッピングします。Dataframeの場合、castを使用する必要があります。
コードサンプル:
dyf_cast = dyf.apply_mapping([('a', 'long', 'a', 'long'), ('b', 'float', 'b', 'double')])
