AWS Glue コンポーネント
AWS Glue は、抽出、変換、ロード (ETL) ワークロードを設定し管理するためのコンソールと API オペレーションを備えています。いくつかの言語に固有な SDK と AWS Command Line Interface (AWS CLI) を介して API オペレーションを使用できます。AWS CLI の使用については、「AWS CLI コマンドリファレンス」を参照してください。
AWS Glue は AWS Glue Data Catalog を使用して、データソース、変換、およびターゲットについてのメタデータを保存します。Data Catalog は Apache Hive メタストアのドロップインリプレースメントです。AWS Glue Jobs system は、データの ETL オペレーションの定義、スケジューリング、および実行のためのマネージド型インフラストラクチャを備えています。AWS Glue API の詳細については、「AWS Glue API」を参照してください。
AWS Glue コンソール
AWS Glue コンソールを使用して、ETL ワークフローを定義しオーケストレーションします。コンソールは AWS Glue Data Catalog および AWS Glue Jobs system のいくつかの API オペレーションを呼び出して、次のタスクを実行します。
-
ジョブ、テーブル、クローラ、接続などの AWS Glue オブジェクトを定義します。
-
いつクローラが実行するかをスケジュールします。
-
ジョブトリガーのイベントやスケジュールを定義します。
-
AWS Glue オブジェクトのリストを検索しフィルタリングします。
-
変換スクリプトを編集します。
AWS Glue Data Catalog
AWS Glue Data Catalog は AWS クラウド内にある永続的な技術メタデータストアです。
各 AWS アカウントには、AWS リージョンごとに 1 つの AWS Glue Data Catalog があります。各データカタログは、データベースに構成された高度にスケーラブルなテーブルのコレクションです。テーブルは、Amazon RDS、Apache Hadoop 分散ファイルシステム、Amazon OpenSearch Service などのソースに保存されている構造化データまたは半構造化データの集合をメタデータで表現したものです。AWS Glue Data Catalog は統一されたリポジトリを提供するため、異種システムはデータサイロのデータを追跡するためにメタデータを保存し検索することができます。その後は、メタデータを使用して、多種多様なアプリケーション全体で一貫したやり方でそのデータをクエリしたり変換したりすることができます。
データカタログを AWS Identity and Access Management ポリシーと Lake Formation と併用することで、テーブルやデータベースへのアクセスを制御します。この方法により、企業内の様々なグループが、機密情報を高度かつ詳細に保護しながら、より広範な組織に対してデータを安全に公開できるようになります。
また、データカタログを CloudTrail や Lake Formation を併用することで、スキーマ変更の追跡やデータアクセス制御を備えた包括的な監査およびガバナンス機能も提供します。これにより、データの不適切な変更や誤った共有を防止できます。
AWS Glue Data Catalog のセキュリティ保護と監査の詳細については、以下を参照してください。
-
AWS Lake Formation – 詳細については、「AWS Lake Formation デベロッパーガイド」の「AWS Lake Formation とは?」を参照してください。
-
CloudTrail – 詳細については、「AWS CloudTrail ユーザーガイド」の「CloudTrail とは」を参照してください。
次に示すのは、AWS Glue Data Catalog を使用する AWS の他のサービスとオープンソースプロジェクトです。
-
Amazon Athena – 詳細については、Amazon Athena ユーザーガイドの「テーブル、データベース、およびデータカタログの理解」を参照してください。
-
Amazon Redshift Spectrum – 詳細については、「Amazon Redshift データベースデベロッパーガイド」の「Amazon Redshift Spectrum を使用した外部データのクエリ」を参照してください。
-
Amazon EMR – 詳細については、Amazon EMR マネジメントガイドの「AWS Glue Data Catalog への Amazon EMR アクセスにリソースベースのポリシーを使用する」を参照してください。
-
Apache Hive メタストア用 AWS Glue Data Catalog クライアント – この GitHub プロジェクトの詳細については、「AWS Glue Data Catalog Client for Apache Hive Metastore
」を参照してください。
AWS Glue クローラおよび分類子
AWS Glue では、あらゆる種類のリポジトリにあるデータのスキャン、分類、スキーマ情報の抽出、そのメタデータの AWS Glue Data Catalog への自動保存ができるクローラを設定することもできます。そこから AWS Glue Data Catalog は ETL オペレーションをガイドするのに使用できます。
クローラおよび分類子の設定方法については、「クローラーを使用したデータカタログへの入力」を参照してください。AWS Glue API を使用してクローラおよび分類子をプログラムする方法については、「クローラーおよび分類子 API」を参照してください。
AWS Glue ETL オペレーション
AWS Glue は、Data Catalog のメタデータを使用して、さまざまな ETL オペレーションを実行するために使用や変更ができる AWS Glue 拡張機能を備えた、Scala または PySpark (Apache Spark 用の Python API) スクリプトを自動生成できます。たとえば、未加工データを抽出、クリーンアップ、および変換してからその結果を別のリポジトリに保存して、クエリと分析を行うことができます。このようなスクリプトは、CSV ファイルをリレーショナル形式に変換し、Amazon Redshift に保存する場合があります。
AWS Glue ETL 機能の使用方法の詳細については、「Spark スクリプトのプログラミング」を参照してください。
AWS Glue でのストリーミング ETL
AWS Glue を使用すると、連続実行のジョブを使用して、ストリーミングデータに対して ETL 操作を実行できます。AWS Glue のストリーミング ETL は、Apache Spark 構造化ストリーミングエンジン上に構築され、Amazon Kinesis Data Streams、Apache Kafka、および Amazon Managed Streaming for Apache Kafka (Amazon MSK) からストリームを取り込むことができます。ストリーミング ETL では、ストリーミングデータのクリーニングと変換を行い、Simple Storage Service (Amazon S3) または JDBC データストアにロードできます。AWS Glue のストリーミング ETL を使用すると、IoT ストリーム、クリックストリーム、ネットワークログなどのイベントデータを処理できます。
ストリーミングデータソースのスキーマがわかっている場合は、Data Catalog テーブルで指定できます。そうでない場合は、ストリーミング ETL ジョブでスキーマ検出を有効にできます。ジョブは、受信データからスキーマを自動的に決定します。
ストリーミング ETL ジョブは、AWS Glue 組み込みの変換および Apache Spark 構造化ストリーミングネイティブの変換の両方を使用できます。詳細については、「Operations on streaming DataFrames/Datasets
詳しくは、「AWS Glue でのストリーミング ETL ジョブ」を参照してください。
AWS Glue ジョブシステム
AWS Glue Jobs system は、ETL ワークフローをオーケストレーションするためのマネージド型インフラストラクチャを提供します。データを抽出したり変換したり異なる場所へ転送したりするのに使用するスクリプトを自動化するジョブを AWS Glue で作成できます。ジョブはスケジュールしたり連鎖させることができます。または新しいデータの到着などのイベントによってトリガーすることができます。
AWS Glue Jobs system の使用方法の詳細については、「AWS Glue のモニタリング」を参照してください。AWS Glue Jobs system API を使用したプログラミングについては、「ジョブ API」を参照してください。
ビジュアル ETL コンポーネント
AWS Glue では、操作可能なビジュアルキャンバスから ETL ジョブを作成できます。
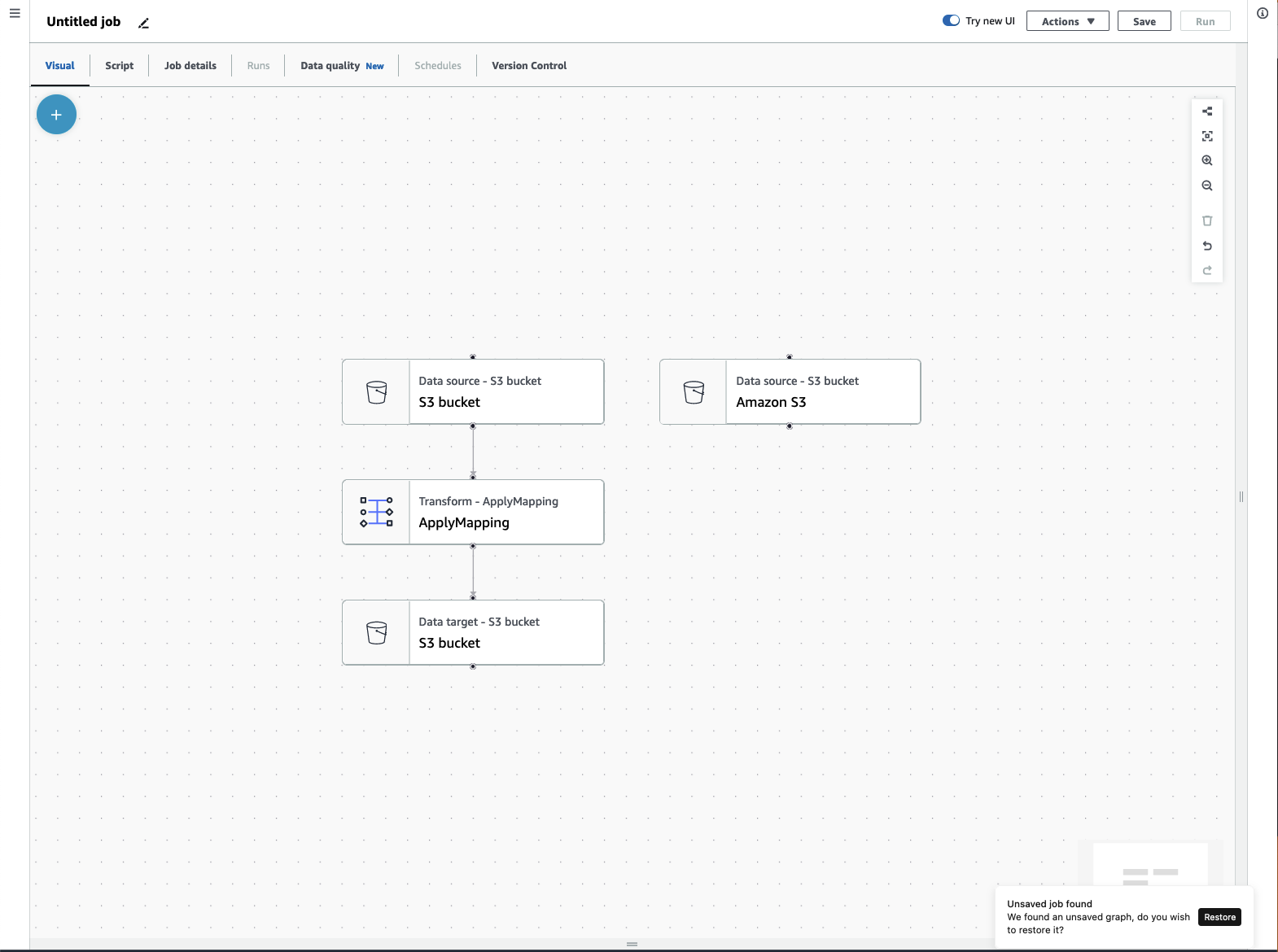
ETL ジョブメニュー
キャンバスの上部にあるメニューオプションから、ジョブに関するさまざまなビューや設定の詳細にアクセスできます。
-
[Visual] - ビジュアルジョブエディタのキャンバスです。ここでは、ノードを追加してジョブを作成できます。
-
スクリプト - ETL ジョブのスクリプト表現。AWSGlue は、ジョブの視覚的表現に基づいてスクリプトを生成します。スクリプトを編集したり、ダウンロードしたりもできます。
注記
スクリプトを編集することを選択した場合、ジョブ作成体験は完全にスクリプト専用モードに変更されます。それ以後、ビジュアルエディタを使用してジョブを編集することはできません。そのため、スクリプトを編集することを選択する前に、すべてのジョブソース、変換、ターゲットを追加し、ビジュアルエディタで必要な変更をすべて行ってください。
-
[ジョブの詳細] - [ジョブの詳細] タブでは、ジョブのプロパティを設定することでジョブを設定できます。基本的なプロパティとして、ジョブの名前と説明、IAM ロール、ジョブタイプ、AWS Glue バージョン、言語、ワーカータイプ、ワーカー数、ジョブブックマーク、Flex 実行、廃止数、ジョブタイムアウトなどがあります。高度なプロパティとして、接続、ライブラリ、ジョブパラメータ、タグなどがあります。
-
[Runs] - ジョブの実行後に、このタブにアクセスして過去のジョブを表示できます。
-
[Data quality] - [Data quality] は、データアセットの品質を評価およびモニタリングします。このタブでは、データ品質の活用方法を詳しく確認したり、データ品質変換をジョブに追加したりできます。
-
[Schedules] - このタブには、スケジュールされたジョブが表示されます。このジョブにスケジュールがアタッチされていない場合、このタブにはアクセスできません。
-
[Version control] - ジョブを Git リポジトリに設定することで、ジョブで Git を使用できます。
ビジュアル ETL パネル
キャンバスで作業するときに、ノードの設定、データのプレビュー、出力スキーマの表示などに役立つパネルがいくつか用意されています。
-
[プロパティ] - キャンバス上のノードを選択すると、[プロパティ] パネルが表示されます。
-
[Data preview] - [Data preview] パネルには、データ出力のプレビューが表示されるため、ジョブを実行して出力を確認する前に判断を行えます。
-
[Output schema] - [Output schema] タブでは、変換ノードのスキーマを表示および編集できます。
パネルサイズを変更する
画面の右側にある [プロパティ] パネルと、[Data preview] タブや [Output schema] タブを含む下部パネルのサイズを変更するには、パネルの端をクリックして左右または上下にドラッグします。
-
[プロパティ] パネル - [プロパティ] パネルのサイズを変更するには、画面の右側にあるキャンバスの端をクリックしてドラッグし、左にドラッグして幅を拡大します。デフォルトでは、パネルは折りたたまれており、ノードを選択すると、[プロパティ] パネルがデフォルトサイズで表示されます。
-
[Data preview] と [Output schema] パネル - 下部パネルのサイズを変更するには、画面の下部にあるキャンバスの下端をクリックしてドラッグし、上にドラッグして高さを拡大します。デフォルトでは、パネルは折りたたまれており、ノードを選択すると、下部パネルがデフォルトサイズで表示されます。
ジョブキャンバス
ビジュアル ETL キャンバスでは、ノードの追加、削除、移動/順序変更を直接行えます。これは、データソースで始まりデータターゲットで終わる、完全に機能する ETL ジョブを作成するためのワークスペースと考えてください。
キャンバス上のノードを操作するときに、ツールバーを使用できます。ツールバーでは、ズームインとズームアウト、ノードの削除、ノード間の接続の作成または編集、ジョブフローの向きの変更、アクションを元に戻す/やり直すなどが行えます。

フローティングツールバーはキャンバス画面の右上に固定されており、アクションを実行する複数のアイコン画像が表示されています。
-
レイアウトアイコン - レイアウトアイコンは、ツールバーの一番上のアイコンです。デフォルトでは、ビジュアルジョブの方向は上から下です。ノードを左から右に水平に配置することで、ビジュアルジョブの配置方向を変更します。レイアウトアイコンを再度クリックすると、方向は上から下に戻ります。
-
リセンタリングアイコン - リセンタリングアイコンは、キャンバスの表示位置を中央に変更します。大規模なジョブで、中央位置に戻るときに活用できます。
-
ズームインアイコン - ズームインアイコンは、キャンバス上のノードのサイズを拡大します。
-
ズームアウトアイコン - ズームアウトアイコンは、キャンバス上のノードのサイズを縮小します。
-
ゴミ箱アイコン - ゴミ箱アイコンは、ビジュアルジョブからノードを削除します。先にノードを選択しておく必要があります。
-
元に戻すアイコン - 元に戻すアイコンは、ビジュアルジョブで最後に実行したアクションを取り消します。
-
やり直すアイコン - やり直すアイコンは、ビジュアルジョブで最後に実行されたアクションをやり直します。
ミニマップを使用する

リソースパネル
リソースパネルには、使用可能なデータソース、変換アクション、接続がすべて含まれています。キャンバスでリソースパネルを表示するには、[+] アイコンをクリックします。これで、リソースパネルが開きます。
リソースパネルを閉じるには、リソースパネルの右上隅にある [X] をクリックします。これにより、再び開く準備ができるまでパネルが非表示になります。
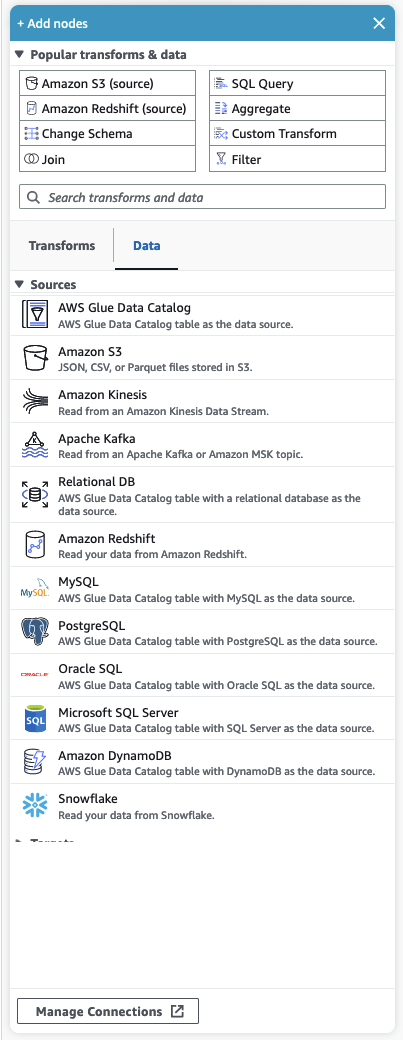
[Popular transforms & data]
パネルの上部に、[Popular transforms & data] というコレクションがあります。これらのノードは、AWS Glue で一般的に使用されるものです。いずれかを選択してキャンバスに追加します。また、[Popular transforms & data] の見出しの横にある三角アイコンをクリックすると、[Popular transforms & data] を非表示にできます。
[Popular transforms & data] セクションの下で、変換およびデータソースノードを検索できます。入力すると結果が表示されます。検索クエリに追加する文字が多いほど、表示される結果は少なくなります。検索結果には、ノードの名前または説明が表示されます。結果に表示されたノードを選択してキャンバスに追加します。
[Transforms] と [Data]
ノードを [Transforms] と [Data] に整理する 2 つのタブがあります。
[Transforms] – [Transforms] タブを選択すると、使用可能なすべての変換を選択できます。変換を選択してキャンバスに追加します。また、[Transforms] リストの下部にある [変換の追加] をクリックすると、カスタムビジュアル変換を作成するためのドキュメントへの新しいページが開きます。手順に従うことで、独自の変換を作成できます。この変換はその後、使用可能な変換のリストに表示されます。
[Data] – [Data] タブには、[ソース] と [ターゲット] のノードがすべて含まれています。[ソース] と [ターゲット] を非表示にするには、[ソース] または [ターゲット] の見出しの横にある三角アイコンをクリックします。三角アイコンを再度クリックすると、[ソース] と [ターゲット] を再表示できます。ソースノードまたはターゲットノードを選択し、キャンバスに追加します。また、[Manage Connections] をクリックすると、新しい接続を追加できます。このとき、コンソールのコネクタページが開きます。
