Apache Spark プログラムを AWS Glue に移行する
Apache Spark は、大規模なデータセットで実行される分散コンピューティングワークロード向けのオープンソースプラットフォームです。AWS Glue は、Spark の機能を活用して ETL に最適化されたエクスペリエンスを提供します。Spark プログラムは、AWS Glue に移行することで機能を最大限に活用できます。AWS Glue は、Amazon EMR の Apache Spark と同等のパフォーマンス向上を実現します。
Spark コードを実行する
ネイティブ Spark コードは、AWS Glue 環境で追加設定なしですぐに使用できます。スクリプトは多くの場合、インタラクティブセッションに適したワークフローであるコードを繰り返し変更することによって開発されます。ただし、既存のコードの方が AWS Glue ジョブでの実行に適しています。これにより、スクリプトを実行するたびにログとメトリクスをスケジュールし、一貫して取得できます。コンソールから既存のスクリプトをアップロードして編集できます。
-
スクリプトのソースを取得します。この例では、Apache Spark リポジトリのサンプルスクリプトを使用します。バイナライザーの例
-
AWS Glue コンソールで、左側のナビゲーションペインを展開し、[ETL] > [Jobs] (ジョブ) を選択します。
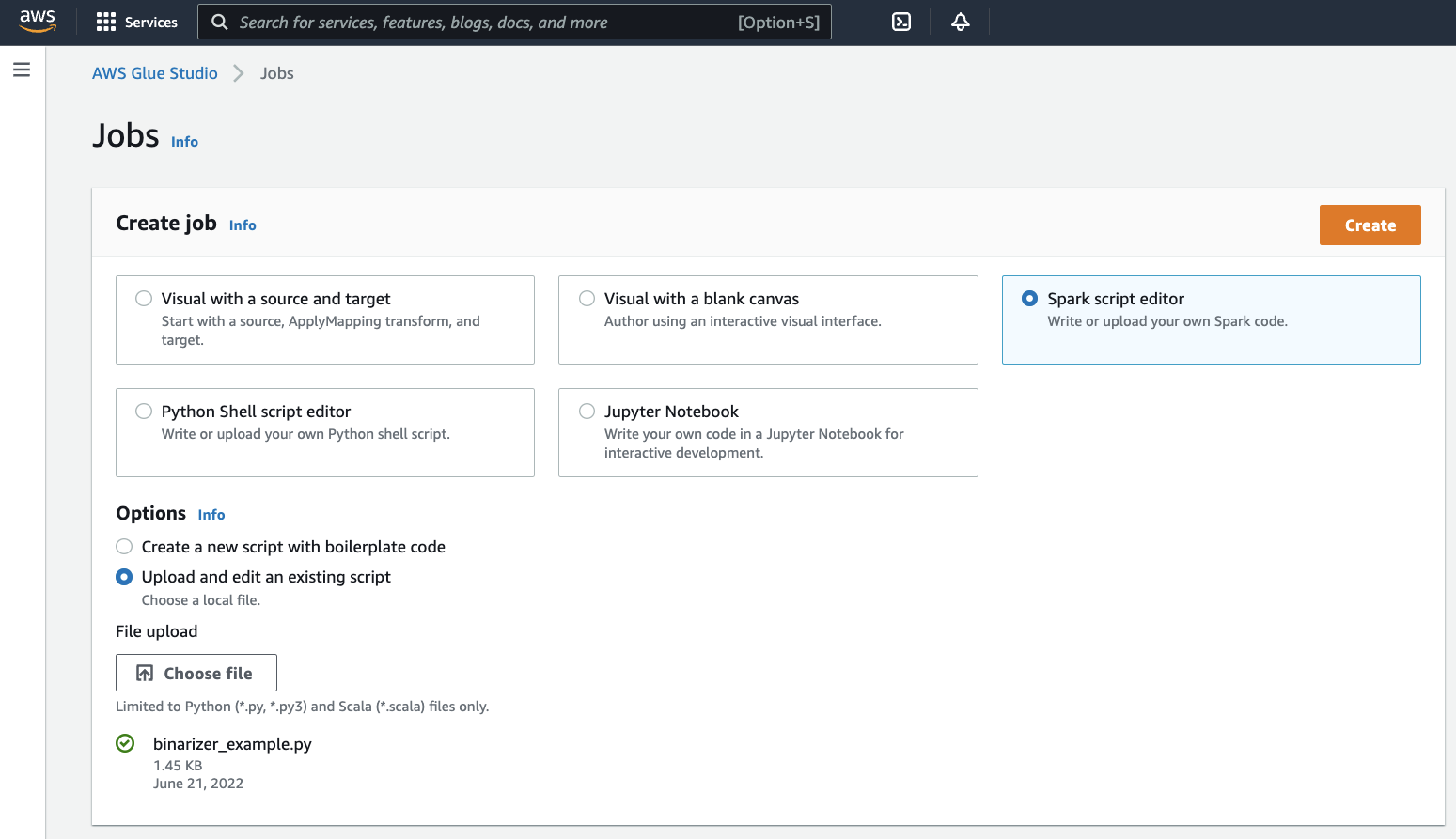
[Create job] (ジョブの作成) パネルで、[Spark script editor] (Spark スクリプトエディタ) を選択します。[Options] (オプション) セクションが表示されます。[Options] (オプション) で [Upload and edit an existing script] (既存のスクリプトのアップロードと編集) を選択します。
[File upload] (ファイルのアップロード) セクションが表示されます。[File upload] (ファイルのアップロード) で [Choose file] (ファイルを選択) をクリックします。システムファイル選択ダイアログが表示されます。
binarizer_example.pyを保存した場所に移動してこの場所を選択し、選択を確定します。[Create job] (ジョブの作成) パネルのヘッダーに [Create] (作成) ボタンが表示されます。このボタンをクリックします。
-
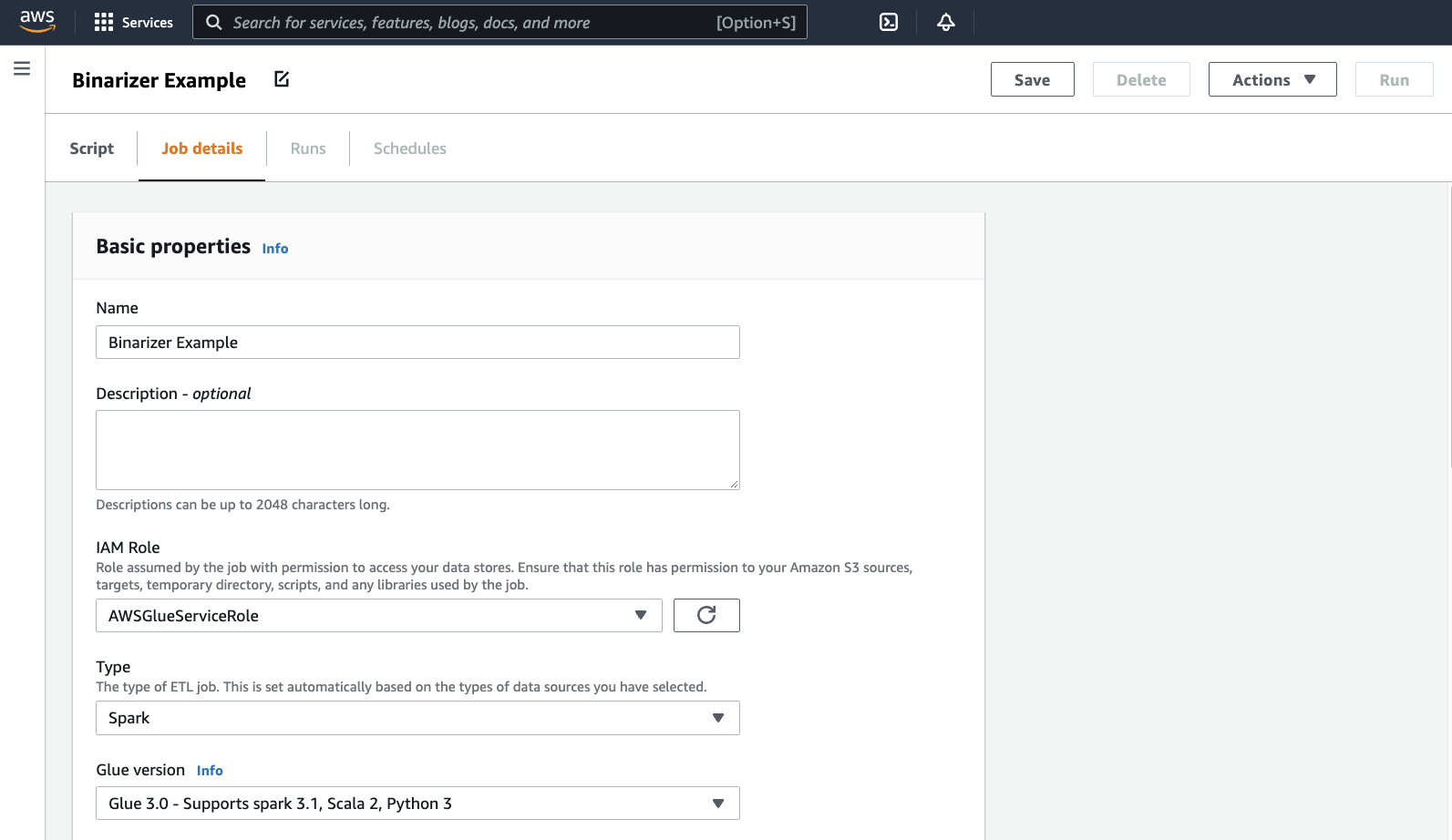
ブラウザがスクリプトエディタに移動します。ヘッダーで、[Job details] (ジョブの詳細) タブをクリックします。名前と IAM ロールを設定します。AWS Glue IAM ロールに関するガイダンスについては、「AWS Glue 用の IAM アクセス許可のセットアップ」を参照してください。
必要に応じて、[Requested number of workers] (要求されたワーカー数) を
2に、[Number of retries] (再試行回数) を1に設定します。これらのオプションは本番ジョブを実行する場合に役立ちますが、無効にすると、機能をテストする際のエクスペリエンスが合理化されます。タイトルバーで、[Save] (保存) をクリックし、続いて [Run] (実行) をクリックします。
-
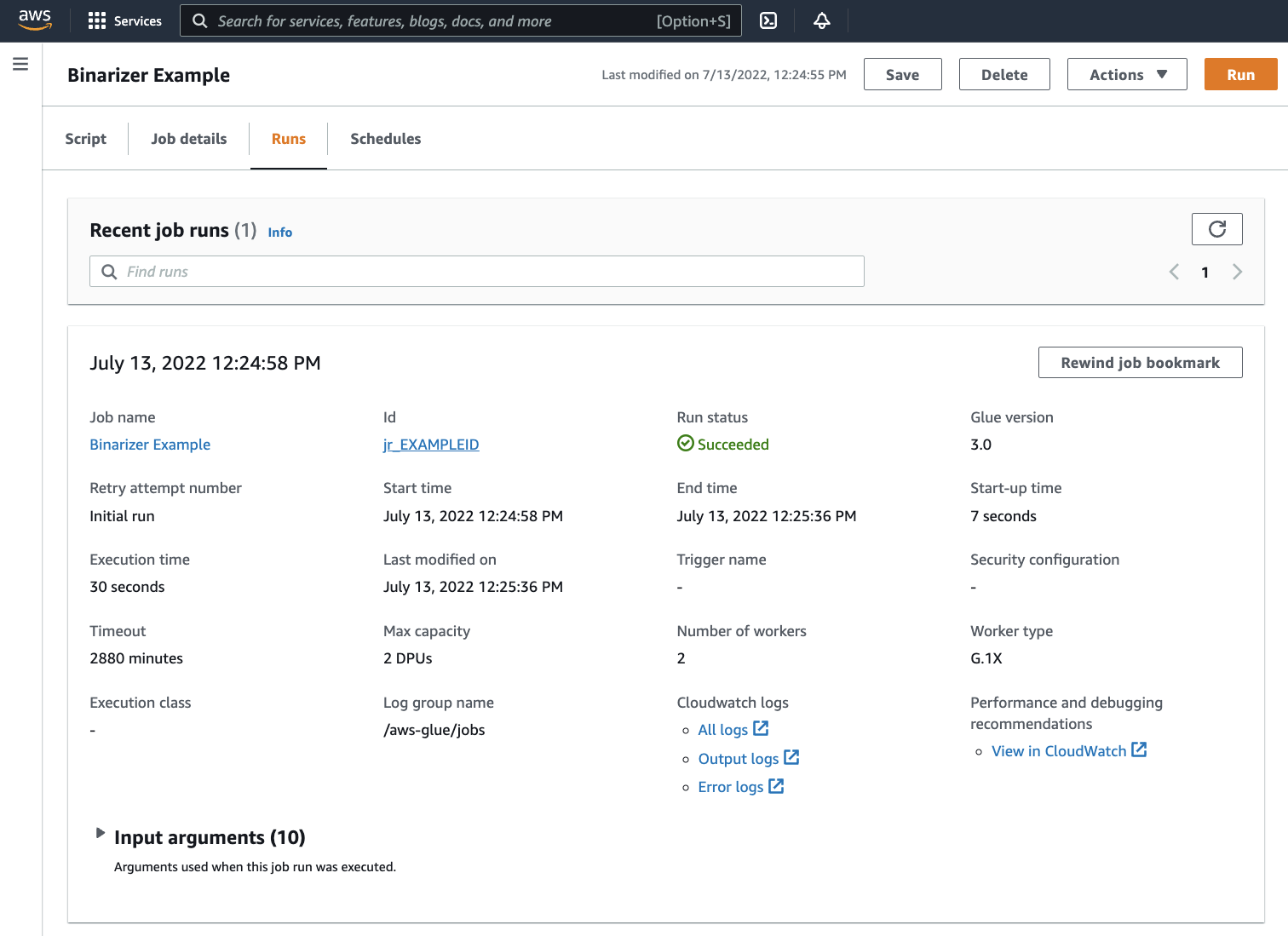
[Runs] (実行) タブに移動します。ジョブの実行に対応するパネルが表示されます。数分間待機した後、ページが自動的に更新され、[Run status] (実行ステータス) の下に[Succeeded] (成功) が表示されます。
-
出力を調べて、Spark スクリプトが意図したとおりに実行されたことを確認する必要があります。この Apache Spark サンプルスクリプトは、出力ストリームに文字列を書き込む必要があります。これは、実行が成功したジョブのパネル内の [Cloudwatch Logs] の下にある [Output logs] (出力ログ) に移動して確認できます。ジョブ実行 ID をメモします。これは、
jr_で始まる [ID] ラベルの下に生成されます。これにより、CloudWatch コンソールが開き、デフォルトの AWS Glue ロググループ
/aws-glue/jobs/outputのコンテンツを視覚化するように設定されます。これで、ジョブ実行 ID のログストリームのコンテンツに絞り込まれます。各ワーカーはログストリームを生成し、[Log streams] (ログストリーム) の下の行として表示されます。1 人のワーカーが要求されたコードを実行しているはずです。正しいワーカーを特定するには、すべてのログストリームを開く必要があります。適切なワーカーが見つかると、次の画像に示すように、スクリプトの出力が表示されます。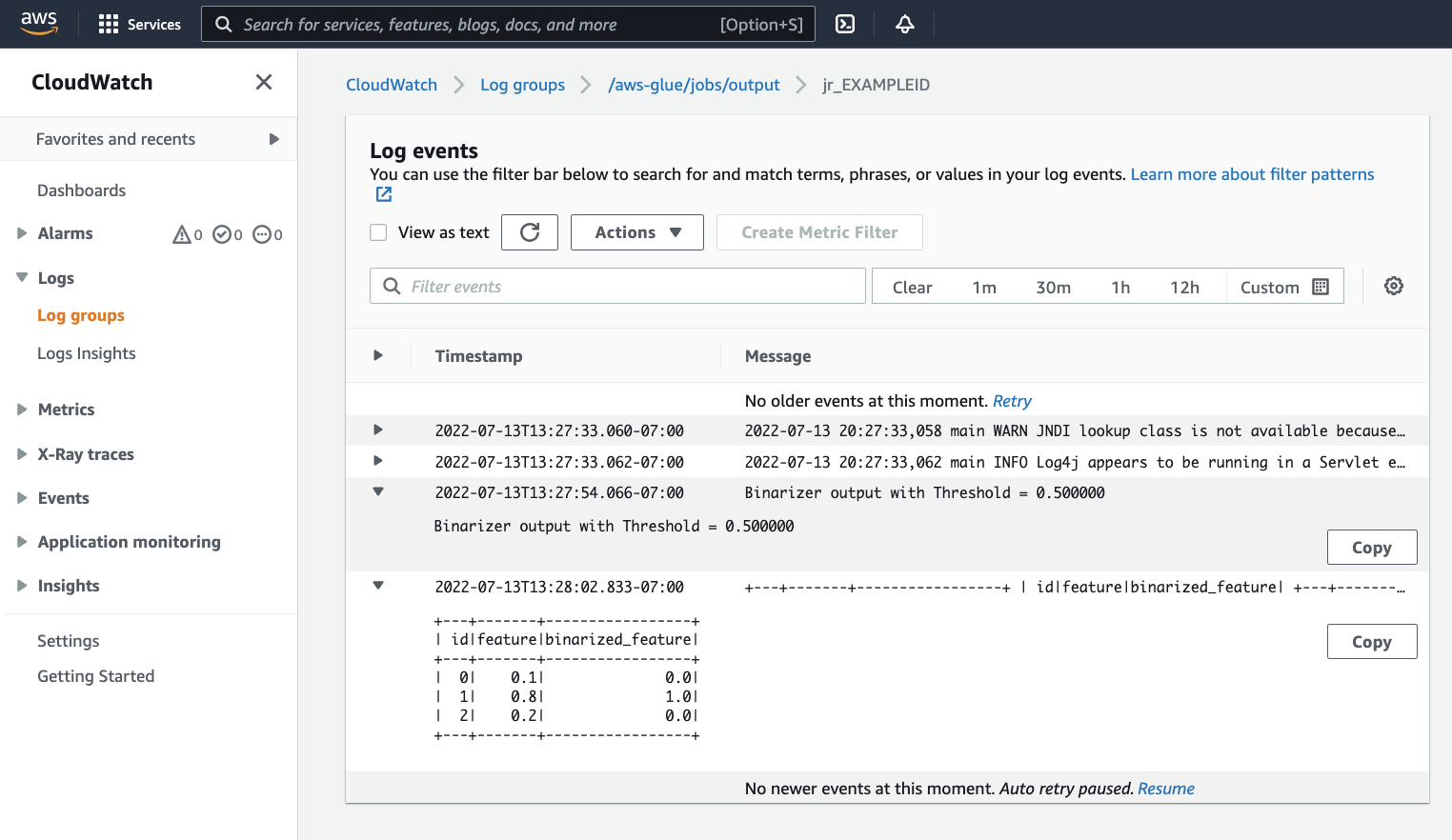
Spark プログラムの移行に必要な一般的な手順
Spark バージョンサポートの評価
AWS Glue リリースバージョンは、AWS Glue ジョブで使用できる Apache Spark と Python のバージョンを決定します。AWS Glue バージョンとそのサポート対象については、「AWS Glue バージョン」をご覧ください。特定の AWS Glue 機能にアクセスするには、Spark プログラムを新しいバージョンの Spark と互換性があるように更新する必要がある場合があります。
サードパーティライブラリを含める
既存の Spark プログラムの多くは、プライベートアーティファクトとパブリックアーティファクトの両方に依存しています。AWS Glue は、Scala ジョブの JAR スタイルの依存関係と、Python ジョブのホイールとソース Pure-Python 依存関係をサポートします。
Python-Python の依存関係については、「AWS Glue での Python ライブラリの使用」を参照してください。
一般的な Python の依存関係は、一般的に要求される Pandas--additional-python-modules を使用します。ジョブ引数の詳細については、「AWS Glue ジョブでジョブパラメータを使用する」を参照してください。
追加の Python 依存関係は、--extra-py-files ジョブ引数で指定できます。Spark プログラムからジョブを移行する場合、このパラメータは良いオプションです。PySpark の --py-files フラグと機能的に同等で、同じ制限が適用されるからです。--extra-py-files パラメータの詳細については、「PySpark のネイティブ機能を使用して Python ファイルを含める」を参照してください。
新しいジョブについては、--additional-python-modules 引数を使用してPython の依存関係を管理できます。この引数を使用すると、より徹底した依存関係管理が可能になります。このパラメータは、Amazon Linux 2 と互換性のあるネイティブコードバインディングを含むホイールスタイルの依存関係をサポートします。
Scala
追加の Scala 依存関係は、--extra-jars ジョブ引数で指定できます。依存関係は Amazon S3 でホストされている必要があり、引数の値は、スペースを含まない Amazon S3 パスのカンマ区切りリストである必要があります。依存関係をホストして設定する前に再バンドルすると、設定を管理しやすくなる場合があります。AWS GlueJAR 依存関係には Java バイトコードが含まれており、任意の JVM 言語から生成できます。Java などの他の JVM 言語を使用して、カスタムの依存関係を記述できます。
データソース認証情報の管理
既存の Spark プログラムには、データソースからデータを取得するための複雑な構成またはカスタム構成が付属している場合があります。一般的なデータソース認証フローは、AWS Glue 接続でサポートされます。AWS Glue 接続の詳細については、「データへの接続」を参照してください。
AWS Glue 接続は、主に次の 2 つの方法 (ライブラリへのメソッド呼び出しと、AWS コンソールで [Additional network connection] (追加のネットワーク接続) を設定する) を通じて、ジョブをさまざまなタイプのデータストアに接続しやすくします。また、接続から情報を取得するため、ジョブ内からの AWS SDK を呼び出すこともできます。
メソッドの呼び出し – AWS Glue 接続は、AWS Glue データカタログと密接に統合されています。これは、データセットに関する情報と、この情報が反映された AWS Glue 接続の操作に使用できるメソッドの管理に利用できます。JDBC 接続で再利用したい既存の認証設定がある場合は、GlueContext の extract_jdbc_conf メソッドを介して AWS Glue 接続の設定にアクセスできます。詳細については、「extract_jdbc_conf」を参照してください。
コンソール設定 – AWS Glue ジョブは、関連する AWS Glue 接続を使用して Amazon VPC サブネットへの接続を設定します。セキュリティ資料を直接管理している場合は、AWSコンソールで、NETWORK タイプ [Additional network connection] (追加のネットワーク接続) を指定してルーティングを設定します。AWS Glue 接続 API の詳細については、「接続 API」を参照してください
Spark プログラムにカスタム認証フローまたは一般的でない認証フローがある場合、セキュリティ資料をハンズオンで管理する必要があるかもしれません。AWS Glue 接続が適切でない場合、セキュリティ資料をシークレットマネージャーで安全にホストし、ジョブで提供される boto3 または AWS SDK を介してアクセスします。
Apache Spark の設定
複雑な移行では、ワークロードに対応するために Spark 設定が変更されることがよくあります。Apache Spark の最新バージョンでは、ランタイム設定を SparkSession で設定できます。AWS Glue3.0 以降のジョブでは SparkSession が提供され、ランタイム設定の変更ができます。Apache Spark 設定
カスタム設定のセット
移行された Spark プログラムは、カスタム設定を選択するように設計されている場合があります。AWS Glue はジョブ引数を使用して、ジョブとジョブの実行レベルで構成を設定できます。ジョブ引数の詳細については、「AWS Glue ジョブでジョブパラメータを使用する」を参照してください。ライブラリを通じて、ジョブのコンテキスト内でジョブの引数にアクセスできます。AWS Glue は、ジョブに設定された引数とジョブ実行時に設定された引数の間で一貫したビューを提供するユーティリティ関数を提供します。Python の「getResolvedOptions を使用して、パラメータにアクセスする」、Scala の「AWS Glue Scala GlueArgParser API」を参照してください。
Java コードの移行
「サードパーティライブラリを含める」で説明されているように、Java や Scala などの JVM 言語で生成されたクラスを依存関係に含めることができます。依存関係には main メソッドが含まれます。AWS Glue Scala ジョブのエントリポイントとして、依存関係内に main メソッドを使用できます。これにより、Java に main メソッドを記述するか、独自のライブラリ標準にパッケージ化された main メソッドを再使用できます。
依存関係から main メソッドを使用するには、次のいずれかの方法を実行します: デフォルトの GlueApp オブジェクトを提供する編集ペインの内容をクリアします。依存関係内のクラスの完全修飾名を、キー --class を使用したジョブ引数として指定します。これで、ジョブ実行をトリガーできるようになります。
AWS Glue が main メソッドに引き渡す引数の順序や構造は設定できません。既存のコードで、AWS Glue の設定を読み取る必要がある場合、以前のコードとの非互換性を引き起こす可能性があります。getResolvedOptions を使用していると、このメソッドを呼び出すのに適した条件もありません。AWS Glue で生成されたメインメソッドから依存関係を直接呼び出すことをおすすめします。この例については、以下の AWS Glue ETL スクリプトをご覧ください。
import com.amazonaws.services.glue.util.GlueArgParser object GlueApp { def main(sysArgs: Array[String]) { val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) // Invoke static method from JAR. Pass some sample arguments as a String[], one defined inline and one taken from the job arguments, using getResolvedOptions com.mycompany.myproject.MyClass.myStaticPublicMethod(Array("string parameter1", args("JOB_NAME"))) // Alternatively, invoke a non-static public method. (new com.mycompany.myproject.MyClass).someMethod() } }
