AWS Glue Schema Registry との統合
これらのセクションでは、AWS Glue スキーマレジストリとの統合について説明します。このセクションの例では、AVRO データ形式のスキーマを使用します。JSON データ形式のスキーマなど、その他の例については、「AWS Glue Schema Registry open source repository
トピック
ユースケース: Schema Registry を Amazon MSK または Apache Kafka に接続する
Apache Kafka トピックにデータを書き込む場合には、以下の手順に従い作業を開始します。
Amazon Managed Streaming for Apache Kafka(Amazon MSK) または Apache Kafka のクラスターを作成し、少なくとも 1 つのトピックを含めます。Amazon MSK クラスターを作成する場合は、AWS Management Console を使用します。Amazon Managed Streaming for Apache Kafka デベロッパーガイドの「Getting Started Using Amazon MSK」にある手順に従います。
上記の SerDe ライブラリのインストール ステップを実行します。
スキーマのレジストリ、スキーマ、またはスキーマバージョンを作成するには、このドキュメントにある スキーマレジストリの開始方法 セクションの手順に従います。
Amazon MSK または Apache Kafka のトピックとの間で、レコードの書き込みや読み取りを行うために、Schema Registry を使用してプロデューサとコンシューマを起動します。プロデューサとコンシューマのコード例は、Serdeライブラリの ReadMe ファイル
から入手できます。プロデューサの Schema Registry ライブラリは、レコードを自動的にシリアル化し、スキーマバージョン ID でそのレコードを修飾します。 このレコードにスキーマが入力済みの場合、または自動登録が有効になっている場合には、スキーマが Schema Registry に登録されます。
AWS Glue Schema Registry ライブラリを使用して、Amazon MSK または Apache Kafka のトピックからスキーマの読み取りを行うコンシューマは、自動的に Schema Registry からスキーマを検索します。
ユースケース: Amazon Kinesis Data Streams と AWS Glue Schema Registry との統合
この統合には、既存の Amazon Kinesis データストリーム が必要です。詳細については、Amazon Kinesis Data Streams デベロッパーガイドの「Getting Started with Amazon Kinesis Data Streams」を参照してください。
Kinesis データストリームでは、データの操作用に以下の 2 つの方法があります。
Java の Kinesis Producer Library (KPL) および Kinesis Client Library (KCL) ライブラリを使用します。多言語サポートは提供されていません。
AWS SDK for Java に用意されている
PutRecords、PutRecord、およびGetRecordsKinesis Data Streams API を使用します。
現在、KPL/KCL ライブラリを使用中であれば、そのメソッドを引き続き使用することをお勧めします。ここでの例に示すように、Schema Registry が統合済みの、更新された KCL および KPL バージョンを使用できます。それ以外で、KDS API を直接使用している場合には、サンプルコードを通じて AWS Glue Schema Registry を利用します。
Schema Registry との統合は、KPL v0.14.2 以降と KCL v2.3 以降でのみ使用できます。JSON データ形式による Schema Registry との統合は、KPL v0.14.8 以降および KCL v2.3.6 以降で使用できます。
Kinesis SDK V2 を使用したデータの操作
このセクションでは、Kinesis SDK V2 による Kinesis の操作について説明します。
// Example JSON Record, you can construct a AVRO record also private static final JsonDataWithSchema record = JsonDataWithSchema.builder(schemaString, payloadString); private static final DataFormat dataFormat = DataFormat.JSON; //Configurations for Schema Registry GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration("us-east-1"); GlueSchemaRegistrySerializer glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatSerializer dataFormatSerializer = new GlueSchemaRegistrySerializerFactory().getInstance(dataFormat, gsrConfig); Schema gsrSchema = new Schema(dataFormatSerializer.getSchemaDefinition(record), dataFormat.name(), "MySchema"); byte[] serializedBytes = dataFormatSerializer.serialize(record); byte[] gsrEncodedBytes = glueSchemaRegistrySerializer.encode(streamName, gsrSchema, serializedBytes); PutRecordRequest putRecordRequest = PutRecordRequest.builder() .streamName(streamName) .partitionKey("partitionKey") .data(SdkBytes.fromByteArray(gsrEncodedBytes)) .build(); shardId = kinesisClient.putRecord(putRecordRequest) .get() .shardId(); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatDeserializer gsrDataFormatDeserializer = glueSchemaRegistryDeserializerFactory.getInstance(dataFormat, gsrConfig); GetShardIteratorRequest getShardIteratorRequest = GetShardIteratorRequest.builder() .streamName(streamName) .shardId(shardId) .shardIteratorType(ShardIteratorType.TRIM_HORIZON) .build(); String shardIterator = kinesisClient.getShardIterator(getShardIteratorRequest) .get() .shardIterator(); GetRecordsRequest getRecordRequest = GetRecordsRequest.builder() .shardIterator(shardIterator) .build(); GetRecordsResponse recordsResponse = kinesisClient.getRecords(getRecordRequest) .get(); List<Object> consumerRecords = new ArrayList<>(); List<Record> recordsFromKinesis = recordsResponse.records(); for (int i = 0; i < recordsFromKinesis.size(); i++) { byte[] consumedBytes = recordsFromKinesis.get(i) .data() .asByteArray(); Schema gsrSchema = glueSchemaRegistryDeserializer.getSchema(consumedBytes); Object decodedRecord = gsrDataFormatDeserializer.deserialize(ByteBuffer.wrap(consumedBytes), gsrSchema.getSchemaDefinition()); consumerRecords.add(decodedRecord); }
KPL/KCL ライブラリを使用したデータの操作
このセクションでは、KPL/KCL ライブラリを使用しての Kinesis Data Streams と Schema Registry の統合について説明します。KPL/KCL の使用方法については、Amazon Kinesis Data Streams デベロッパーガイドの「Developing Producers Using the Amazon Kinesis Producer Library」を参照してください。
KPL で Schema Registry を設定する
AWS Glue Schema Registryで作成したデータ、データ形式、スキーマ名のスキーマ定義を行います。
必要に応じて、
GlueSchemaRegistryConfigurationオブジェクトも構成します。addUserRecord APIにスキーマオブジェクトを渡します。private static final String SCHEMA_DEFINITION = "{"namespace": "example.avro",\n" + " "type": "record",\n" + " "name": "User",\n" + " "fields": [\n" + " {"name": "name", "type": "string"},\n" + " {"name": "favorite_number", "type": ["int", "null"]},\n" + " {"name": "favorite_color", "type": ["string", "null"]}\n" + " ]\n" + "}"; KinesisProducerConfiguration config = new KinesisProducerConfiguration(); config.setRegion("us-west-1") //[Optional] configuration for Schema Registry. GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration("us-west-1"); schemaRegistryConfig.setCompression(true); config.setGlueSchemaRegistryConfiguration(schemaRegistryConfig); ///Optional configuration ends. final KinesisProducer producer = new KinesisProducer(config); final ByteBuffer data = getDataToSend(); com.amazonaws.services.schemaregistry.common.Schema gsrSchema = new Schema(SCHEMA_DEFINITION, DataFormat.AVRO.toString(), "demoSchema"); ListenableFuture<UserRecordResult> f = producer.addUserRecord( config.getStreamName(), TIMESTAMP, Utils.randomExplicitHashKey(), data, gsrSchema); private static ByteBuffer getDataToSend() { org.apache.avro.Schema avroSchema = new org.apache.avro.Schema.Parser().parse(SCHEMA_DEFINITION); GenericRecord user = new GenericData.Record(avroSchema); user.put("name", "Emily"); user.put("favorite_number", 32); user.put("favorite_color", "green"); ByteArrayOutputStream outBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(outBytes, null); new GenericDatumWriter<>(avroSchema).write(user, encoder); encoder.flush(); return ByteBuffer.wrap(outBytes.toByteArray()); }
Kinesis Client Library のセットアップ
Kinesis Client Library コンシューマーを、Java により構築します。詳細については、Amazon Kinesis Data Streams デベロッパーガイドの「Developing a Kinesis Client Library Consumer in Java」を参照してください。
GlueSchemaRegistryConfigurationオブジェクトを渡すことでGlueSchemaRegistryDeserializerインスタンスを作成します。GlueSchemaRegistryDeserializerをretrievalConfig.glueSchemaRegistryDeserializerに渡します。kinesisClientRecord.getSchema()を呼び出して、受信メッセージのスキーマにアクセスします。GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(this.region.toString()); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), schemaRegistryConfig); RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(streamName, kinesisClient)); retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer); Scheduler scheduler = new Scheduler( configsBuilder.checkpointConfig(), configsBuilder.coordinatorConfig(), configsBuilder.leaseManagementConfig(), configsBuilder.lifecycleConfig(), configsBuilder.metricsConfig(), configsBuilder.processorConfig(), retrievalConfig ); public void processRecords(ProcessRecordsInput processRecordsInput) { MDC.put(SHARD_ID_MDC_KEY, shardId); try { log.info("Processing {} record(s)", processRecordsInput.records().size()); processRecordsInput.records() .forEach( r -> log.info("Processed record pk: {} -- Seq: {} : data {} with schema: {}", r.partitionKey(), r.sequenceNumber(), recordToAvroObj(r).toString(), r.getSchema())); } catch (Throwable t) { log.error("Caught throwable while processing records. Aborting."); Runtime.getRuntime().halt(1); } finally { MDC.remove(SHARD_ID_MDC_KEY); } } private GenericRecord recordToAvroObj(KinesisClientRecord r) { byte[] data = new byte[r.data().remaining()]; r.data().get(data, 0, data.length); org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(r.schema().getSchemaDefinition()); DatumReader datumReader = new GenericDatumReader<>(schema); BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(data, 0, data.length, null); return (GenericRecord) datumReader.read(null, binaryDecoder); }
Kinesis Data Streams API を使用したデータの操作
このセクションでは、Kinesis Data Streams API を使用しての、Kinesis Data Streams と Schema Registry の統合について説明します。
Maven の以下の依存関係を更新します。
<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.884</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-kinesis</artifactId> </dependency> <dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-serde</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-cbor</artifactId> <version>2.11.3</version> </dependency> </dependencies>PutRecordsまたは Kinesis Data Streams のPutRecordAPI を使用しながら、プロデューサ内にスキーマヘッダー情報を追加します。//The following lines add a Schema Header to the record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(getConfigs())); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes);プロデューサ内で
PutRecordsまたはPutRecordAPI を使用して、レコードをデータストリームに配置します。コンシューマ内で、ヘッダーからスキーマレコードを削除し、Avro スキーマレコードをシリアル化します。
//The following lines remove Schema Header from record GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), getConfigs()); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); }
Kinesis Data Streams API を使用したデータの操作
以下に、PutRecords および GetRecords API を使用するコード例を示します。
//Full sample code import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryDeserializerImpl; import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistrySerializerImpl; import com.amazonaws.services.schemaregistry.utils.AVROUtils; import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumReader; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.Decoder; import org.apache.avro.io.DecoderFactory; import org.apache.avro.io.Encoder; import org.apache.avro.io.EncoderFactory; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; import software.amazon.awssdk.services.glue.model.DataFormat; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Collections; import java.util.HashMap; import java.util.Map; public class PutAndGetExampleWithEncodedData { static final String regionName = "us-east-2"; static final String streamName = "testStream1"; static final String schemaName = "User-Topic"; static final String AVRO_USER_SCHEMA_FILE = "src/main/resources/user.avsc"; KinesisApi kinesisApi = new KinesisApi(); void runSampleForPutRecord() throws IOException { Object testRecord = getTestRecord(); byte[] recordAsBytes = convertRecordToBytes(testRecord); String schemaDefinition = AVROUtils.getInstance().getSchemaDefinition(testRecord); //The following lines add a Schema Header to a record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes); //Use PutRecords api to pass a list of records kinesisApi.putRecords(Collections.singletonList(recordWithSchemaHeader), streamName, regionName); //OR //Use PutRecord api to pass single record //kinesisApi.putRecord(recordWithSchemaHeader, streamName, regionName); } byte[] runSampleForGetRecord() throws IOException { ByteBuffer recordWithSchemaHeader = kinesisApi.getRecords(streamName, regionName); //The following lines remove the schema registry header GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); } return record; } private byte[] convertRecordToBytes(final Object record) throws IOException { ByteArrayOutputStream recordAsBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(recordAsBytes, null); GenericDatumWriter datumWriter = new GenericDatumWriter<>(AVROUtils.getInstance().getSchema(record)); datumWriter.write(record, encoder); encoder.flush(); return recordAsBytes.toByteArray(); } private GenericRecord convertBytesToRecord(Schema avroSchema, byte[] record) throws IOException { final GenericDatumReader<GenericRecord> datumReader = new GenericDatumReader<>(avroSchema); Decoder decoder = DecoderFactory.get().binaryDecoder(record, null); GenericRecord genericRecord = datumReader.read(null, decoder); return genericRecord; } private Map<String, String> getMetadata() { Map<String, String> metadata = new HashMap<>(); metadata.put("event-source-1", "topic1"); metadata.put("event-source-2", "topic2"); metadata.put("event-source-3", "topic3"); metadata.put("event-source-4", "topic4"); metadata.put("event-source-5", "topic5"); return metadata; } private GlueSchemaRegistryConfiguration getConfigs() { GlueSchemaRegistryConfiguration configs = new GlueSchemaRegistryConfiguration(regionName); configs.setSchemaName(schemaName); configs.setAutoRegistration(true); configs.setMetadata(getMetadata()); return configs; } private Object getTestRecord() throws IOException { GenericRecord genericRecord; Schema.Parser parser = new Schema.Parser(); Schema avroSchema = parser.parse(new File(AVRO_USER_SCHEMA_FILE)); genericRecord = new GenericData.Record(avroSchema); genericRecord.put("name", "testName"); genericRecord.put("favorite_number", 99); genericRecord.put("favorite_color", "red"); return genericRecord; } }
Amazon Managed Service for Apache Flink のユースケース
Apache Flinkは、無制限および制限付きのデータストリームに対するステートフルな計算に広く使用されている、オープンソースフレームワークの分散処理エンジンです。Amazon Managed Service for Apache Flink は、ストリーミングデータを処理するため、Apache Flink アプリケーションを構築して管理できるようにする完全マネージド型の AWS サービスです。
オープンソースの Apache Flink では、多数のソースとシンクを利用できます。例えば、事前定義済みのデータソースには、ファイル、ディレクトリ、およびソケットからの読み込みや、コレクションとイテレータからのデータの取り込みなどが含まれています。Apache Flink DataStream Connector は、Apache Flinkが、Apache Kafka や Kinesis などの各種サードパーティー製システムと、ソースおよび/またはシンクとしてインターフェースするためのコードを提供します。
詳細については、Amazon Kinesis Data Analytics デベロッパーガイドを参照してください。
Apache Flink Kafka Connector
Apache Flinkは、Kafka のトピックに対するデータの読み取りおよび書き込みを、正確に一度で行えるようにするための、Apache Kafka データストリームのコネクタを提供します。Flink の Kafka コンシューマ FlinkKafkaConsumer では、1 つ以上の Kafka トピックから読み取りを行うアクセスが提供されます。Apache Flink の Kafka プロデューサ FlinkKafkaProducer では、1 つ以上の Kafka トピックに対しレコードのストリームを書き込むことができます。詳細については、「Apache Kafka Connector
Apache Flink Kinesis Streams Connector
Kinesis データストリームのコネクタは、Amazon Kinesis Data Streams へのアクセスを提供します。並列ストリーミングデータソース FlinkKinesisConsumer は、同じAWS のサービスリージョン内で複数の Kinesis ストリームにサブスクライブされ、ジョブの実行中にストリームの再シャーディングを透過的に (確実に 1 回で) 処理できます。コンシューマーの各サブタスクが、複数の Kinesis シャードからのデータレコードの取得を受け持ちます。各サブタスクによって取得されるシャードの数は、Kinesis によってシャードが閉じられ、また作成されるたびに変化します。FlinkKinesisProducer は Kinesis Producer Library (KPL) を使用して、Kinesis ストリーム内に Apache Flink ストリームからのデータを配置します。詳細については、「Amazon Kinesis Streams Connector
詳細については、AWS Glue のGitHub リポジトリ
Apache Flink との統合
Schema Registry で提供されている SerDes ライブラリは、Apache Flink と統合されています。Apache Flink を使用するには、SerializationSchemaDeserializationSchemaGlueSchemaRegistryAvroSerializationSchema および GlueSchemaRegistryAvroDeserializationSchema) を実装する必要があります。これらは、Apache Flink コネクタにプラグインして使用します。
Apache Flink アプリケーションへの AWS Glue Schema Registry の依存関係の追加
Apache Flink アプリケーション内で AWS Glue Schema Registry との統合の依存関係をセットアップするには
pom.xmlファイルに依存関係を追加します。<dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-flink-serde</artifactId> <version>1.0.0</version> </dependency>
Kafka または Amazon MSK を Apache Flink と統合する
Kafka をソースまたはシンクとしながら、Apache Flink 対応の Managed Service for Apache Flink を使用できます。
Kafka をソースとする場合
次の図は、Kafka をソースとしながら、Kinesis Data Streams と Apache Flink 対応の Managed Service for Apache Flink を統合した様子です。
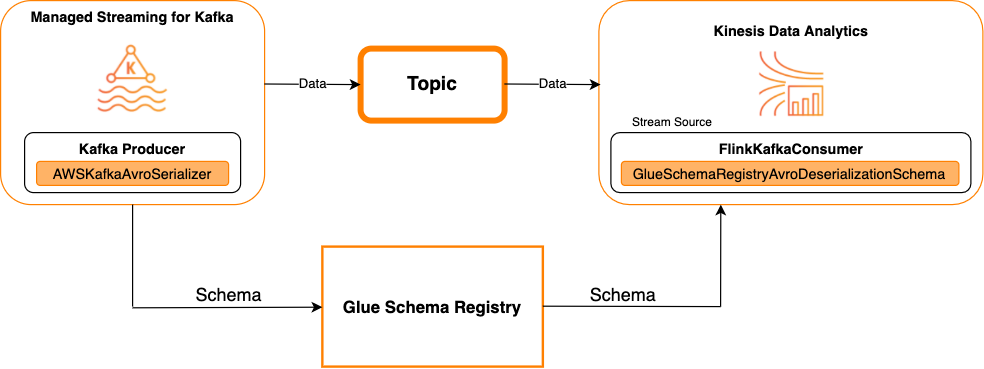
Kafka をシンクとする場合
次の図は、Kafka をシンクとしながら、Kinesis Data Streams と Apache Flink 対応の Managed Service for Apache Flink を統合した様子です。
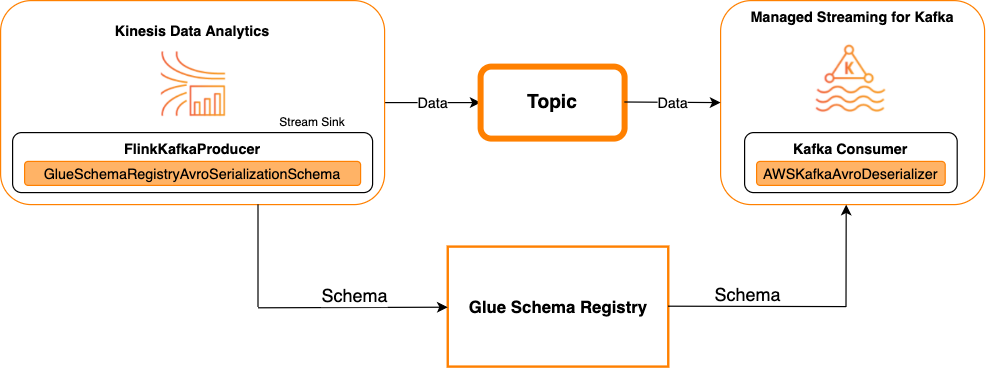
Kafka をソースまたはシンクとしながら、Kafka (または Amazon MSK) を Apache Flink 対応の Managed Service for Apache Flink と統合するには、以下のコード変更を行います。太字で示されたコードブロックを、類似するセクション内の対応するコードにそれぞれ追加します。
Kafka をソースとする場合は、デシリアライザ用コード (ブロック 2) を使用します。Kafka をシンクとする場合は、シリアライザコード (ブロック 3) を使用します。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "topic"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKafkaConsumer<GenericRecord> consumer = new FlinkKafkaConsumer<>( topic, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKafkaProducer<GenericRecord> producer = new FlinkKafkaProducer<>( topic, // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Kinesis Data Streams と Apache Flink との統合
Kinesis Data Streams をソースまたはシンクとしながら、Apache Flink 対応の Managed Service for Apache Flink を使用できます。
Kinesis Data Streams をソースとする場合
次の図は、Kinesis Data Streams をソースとしながら、Kinesis Data Streams と Apache Flink 対応の Managed Service for Apache Flink を統合した様子です。
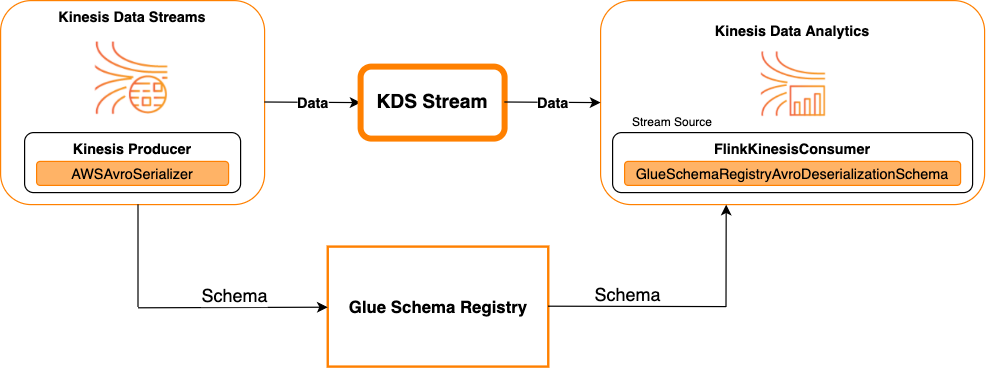
Kinesis Data Streams をシンクとする場合
次の図は、Kinesis Data Streams をシンクとしながら、Kinesis Data Streams と Apache Flink 対応の Managed Service for Apache Flink を統合した様子です。
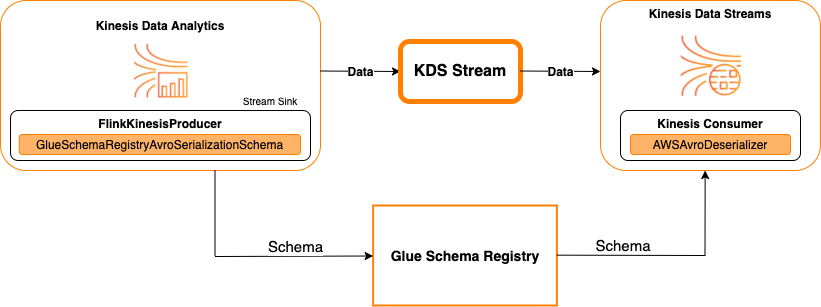
Kinesis Data Streams をソースまたはシンクとしながら、Kinesis Data Streams と Apache Flink 対応の Managed Service for Apache Flink を統合するには、以下のコード変更を行います。太字で示されたコードブロックを、類似するセクション内の対応するコードにそれぞれ追加します。
Kinesis Data Streams をソースとする場合は、デシリアライザコード (ブロック 2) を使用します。Kinesis Data Streams をシンクとする場合は、シリアライザコード (ブロック 3) を使用します。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String streamName = "stream"; Properties consumerConfig = new Properties(); consumerConfig.put(AWSConfigConstants.AWS_REGION, "aws-region"); consumerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id"); consumerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key"); consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKinesisConsumer<GenericRecord> consumer = new FlinkKinesisConsumer<>( streamName, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKinesisProducer<GenericRecord> producer = new FlinkKinesisProducer<>( // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); producer.setDefaultStream(streamName); producer.setDefaultPartition("0"); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
ユースケース: AWS Lambda との統合
AWS Lambda 関数を Apache Kafka/Amazon MSK のコンシューマーとして使用し、Avro でエンコードされたメッセージを AWS Glue Schema Registry により非シリアル化するには、MSK ラボのページ
ユースケース: AWS Glue Data Catalog
AWS Glue テーブルは、手動による指定、または AWS Glue Schema Registry への参照によって指定できる、スキーマをサポートしています。AWS Glue テーブルまたは Data Catalog のパーティションを作成または更新する際に、オプションで Schema Registry に格納されているスキーマを使用できるように、Schema Registry には Data Catalog が統合されています。Schema Registry のスキーマ定義を特定するには、少なくとも、対象となるスキーマの ARN を知る必要があります。スキーマ定義を含むスキーマのスキーマバージョンは、UUID またはバージョン番号により参照が可能です。スキーマバージョンの中でも「最新」バージョンについては、バージョン番号または UUID を把握しなくても常に参照することができます。
CreateTable または UpdateTable オペレーションの呼び出し時は、Schema Registry 内の既存のスキーマに対する TableInput を指定するために SchemaReference 構造体 (StorageDescriptor を含む) を渡します。同様に、GetTable または GetPartition API を呼び出す場合は、そのレスポンスにスキーマと SchemaReference が含まれます。スキーマ参照を使用してテーブルまたはパーティションが作成されると、Data Catalog はこのスキーマ参照のスキーマ取得を試みます。Schema Registry 内にスキーマが見つからない場合は、GetTable レスポンスで空のスキーマを返します。それ以外では、このレスポンスにスキーマとスキーマ参照の両方が出力されます。
また、AWS Glue コンソールからアクションを実行することも可能です。
これらのオペレーションを実行し、スキーマ情報を作成、更新、表示するには、呼び出しユーザーに、GetSchemaVersion API へのアクセス権限を付与する、IAM ロールを付与する必要があります。
テーブルの追加またはテーブルのスキーマの更新
既存のスキーマから新しいテーブルを追加すると、そのテーブルは特定のスキーマバージョンにバインドされます。新しいスキーマバージョンの登録が完了すると、このテーブル定義が、AWS Glue コンソールの [View table] (テーブルの表示) ページ、もしくは UpdateTable アクション (Python: update_table) API を使用して更新できるようになります。
既存のスキーマからのテーブルの追加
AWS Glue コンソールまたは CreateTable API を使用して、レジストリ内のスキーマバージョンから AWS Glue を作成できます。
AWS Glue API
CreateTable API を呼び出す際に、(StorageDescriptor にSchemaReference が指定されている) TableInput を、スキーマレジストリの既存のスキーマに追加します。
AWS Glue コンソール
AWS Glue コンソールを使用してテーブルを作成するには
-
AWS Management Consoleにサインインし、AWS Glue コンソール (https://console.aws.amazon.com/glue/
) を開きます。 ナビゲーションペインの [Data catalog] (データカタログ) で、[Tables] (テーブル) をクリックします。
[Add Tables] (テーブルの追加) メニューで、[Add table from existing schema] (既存のスキーマからテーブルを追加する) をクリックします。
テーブルのプロパティとデータストアを、AWS Glue デベロッパーガイド に沿って設定します。
[Choose a Glue schema] (Glue スキーマの選択) ページで、スキーマが置かれている [Registry] (レジストリ) を選択します。
[Schema name] (スキーマ名) をクリックし、適用するスキーマの [Version] (バージョン) を選択します。
スキーマのプレビューを確認し、[Next] (次へ) をクリックします。
テーブルを確認し、作成します。
作成したテーブルに適用されたスキーマとバージョンは、テーブルの一覧内で [Glue schema] (Glue スキーマ) 列に表示されます。テーブルを表示すると、さらに詳細を確認できます。
テーブルのスキーマの更新
新しいスキーマバージョンが使用可能になったら、テーブルのスキーマを UpdateTable アクション (Python: update_table) API または AWS Glue コンソールにより更新することができます
重要
手動で指定された AWS Glue スキーマを含む既存のテーブル用にスキーマを更新する場合、Schema Registry で参照される新しいスキーマは互換性を持たない可能性があります。この場合、ジョブが失敗することがあります。
AWS Glue API
UpdateTable API を呼び出す際に、(StorageDescriptor にSchemaReference が指定されている) TableInput を、スキーマレジストリの既存のスキーマに追加します。
AWS Glue コンソール
AWS Glue コンソールからテーブルのスキーマを更新するには
-
AWS Management Consoleにサインインし、AWS Glue コンソール (https://console.aws.amazon.com/glue/
) を開きます。 ナビゲーションペインの [Data catalog] (データカタログ) で、[Tables] (テーブル) をクリックします。
テーブルの一覧でテーブルを表示します。
新しいバージョンの情報が表示されたボックスで、[Update schema] (スキーマの更新) をクリックします。
現在のスキーマと更新後のスキーマの違いを確認します。
さらに詳細を表示するには、[Show all schema differences] (スキーマの違いをすべて表示) をクリックします。
[Save table] (テーブルを保存) をクリックし、新しいバージョンを受け入れます。
ユースケース: AWS Glue ストリーミング
AWS Glue ストリーミングは、ストリーミングソースからのデータを消費し、出力シンクに書き込む前に ETL オペレーションを実行します。入力ストリーミングソースは、データテーブルを使用して指定するか、ソース構成を指定して直接指定することができます。
AWS Glue ストリーミングは、AWS Glue スキーマレジストリに存在するスキーマで作成されたストリーミングソースのデータカタログテーブルをサポートします。AWS Glue スキーマレジストリにスキーマを作成し、そのスキーマを使用してストリーミングソースで AWS Glue テーブルを作成できます。この AWS Glue テーブルは、 AWS Glue ストリーミングジョブへの入力として使用し、入力ストリーミングのデータを逆シリアル化することができます。
注意すべき点は、AWS Glue スキーマレジスト内のスキーマが変化した場合、AWS Glue ストリーミングジョブを再度開始して、スキーマの変更を反映させる必要があることです。
ユースケース: Apache Kafka ストリーム
Apache Kafka Streams APIは、Apache Kafka に格納されているデータを処理・分析するためのクライアントライブラリです。このセクションでは、Apache Kafka Streams と AWS Glue Schema Registry の統合について説明します。これにより、データストリーミングアプリケーションのスキーマを、管理および適用できるようになります。Apache Kafka Streams の詳細については、「Apache Kafka Streams
SerDes ライブラリとの統合
GlueSchemaRegistryKafkaStreamsSerde クラスにより、Streams のアプリケーションを設定できます。
Kafka Streams アプリケーションのコード例
Apache Kafka Streams アプリケーション内で AWS Glue Schema Registry を使用するには
Kafka Streams アプリケーションを設定します。
final Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "avro-streams"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, AWSKafkaAvroSerDe.class.getName()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());トピック avro-input からストリームを作成します。
StreamsBuilder builder = new StreamsBuilder(); final KStream<String, GenericRecord> source = builder.stream("avro-input");データレコードを処理します (favorite_color の値がピンクであるか、値が 15 となっているレコードの除外など)。
final KStream<String, GenericRecord> result = source .filter((key, value) -> !"pink".equals(String.valueOf(value.get("favorite_color")))); .filter((key, value) -> !"15.0".equals(String.valueOf(value.get("amount"))));トピック avro-output に結果を書き込みます。
result.to("avro-output");Apache Kafka Streams アプリケーションを起動します。
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
実装結果
以下の結果は、ステップ 3 において (favorite_color が「pink」であるか値が「15.0」であるために) 除外されたレコードに関するフィルタリング処理を示しています。
フィルタリング前のレコード:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"name": "Jay", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105} {"id": "commute_1","amount": 15}
フィルタリング後のレコード:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105}
ユースケース: Apache Kafka Connect
Apache Kafka Connect と AWS Glue Schema Registry を統合することで、コネクタからスキーマ情報を取得できるようになります。Apache Kafka のコンバータにより、Apache Kafka 内のデータ形式と、Apache Kafka Connect データへの変換方法を指定します。すべての Apache Kafka Connect ユーザーは、これらのコンバータを Apache Kafka との間でロードまたは保存する際に、データに適用する形式に基づいた設定を行う必要があります。これにより、Apache Kafka Connect データを AWS Glue Schema Registry で使用する型 (例: Avro) に変換する独自のコンバータを定義し、さらにシリアライザを使用してスキーマを登録しシリアル化を実行します。その後コンバータはデシリアライザを使用して、Apache Kafka から受信したデータを逆シリアル化し、元の Apache Kafka Connect データに変換することができます。ワークフローの例を以下の図に示します。
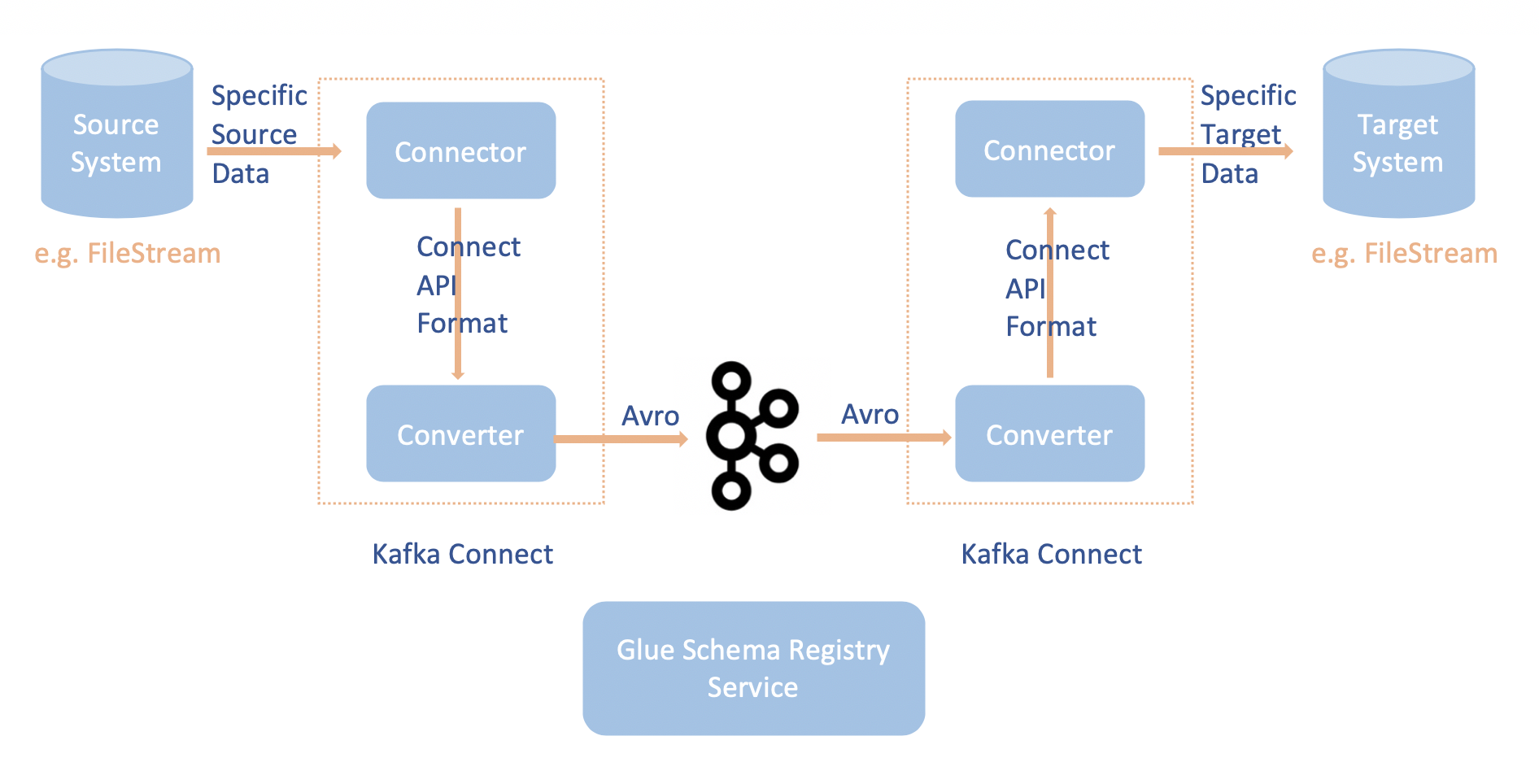
AWS Glue Schema Registry 用 Githubリポジトリ
をクローンして、 aws-glue-schema-registryプロジェクトをインストールします。git clone git@github.com:awslabs/aws-glue-schema-registry.git cd aws-glue-schema-registry mvn clean install mvn dependency:copy-dependenciesApache Kafka Connect を Standalone モードで使用する予定の場合、このステップで以下に示した手順を使用して、connect-standalone.properties を更新します。Apache Kafka Connect を Distributed モードで使用する予定の場合は、同じ手順により connect-avro-distributed.properties を更新します。
Apache Kafka の接続プロパティファイルにも、これらのプロパティを追加します。
key.converter.region=aws-regionvalue.converter.region=aws-regionkey.converter.schemaAutoRegistrationEnabled=true value.converter.schemaAutoRegistrationEnabled=true key.converter.avroRecordType=GENERIC_RECORD value.converter.avroRecordType=GENERIC_RECORD以下のコマンドを、[kafka-run-class.sh] の下の [Launch mode] (起動モード) セクションに追加します。
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"
[kafka-run-class.sh] の下の [Launch mode] (起動モード) セクションに以下のコマンドを追加する
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"プリンシパルは以下のようになります。
# Launch mode if [ "x$DAEMON_MODE" = "xtrue" ]; then nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null & else exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" fibash を使用している場合は、以下のコマンドを実行して、bash_profile で CLASSPATH を設定します。他のシェルの場合は、それに応じて環境を更新します。
echo 'export GSR_LIB_BASE_DIR=<>' >>~/.bash_profile echo 'export GSR_LIB_VERSION=1.0.0' >>~/.bash_profile echo 'export KAFKA_HOME=<your Apache Kafka installation directory>' >>~/.bash_profile echo 'export CLASSPATH=$CLASSPATH:$GSR_LIB_BASE_DIR/avro-kafkaconnect-converter/target/schema-registry-kafkaconnect-converter-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/common/target/schema-registry-common-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/avro-serializer-deserializer/target/schema-registry-serde-$GSR_LIB_VERSION.jar' >>~/.bash_profile source ~/.bash_profile(オプション) 単純なファイルをソースとして使用しテストを行う場合は、ファイルソースコネクタのクローンを作成します。
git clone https://github.com/mmolimar/kafka-connect-fs.git cd kafka-connect-fs/ソースコネクタの設定で、データ形式を Avro に、ファイルリーダーを
AvroFileReaderに変更します。さらに、読み込んでいるファイルパスからサンプルの Avro オブジェクトを更新します。例:vim config/kafka-connect-fs.propertiesfs.uris=<path to a sample avro object> policy.regexp=^.*\.avro$ file_reader.class=com.github.mmolimar.kafka.connect.fs.file.reader.AvroFileReaderソースコネクタをインストールします。
mvn clean package echo "export CLASSPATH=\$CLASSPATH:\"\$(find target/ -type f -name '*.jar'| grep '\-package' | tr '\n' ':')\"" >>~/.bash_profile source ~/.bash_profile<your Apache Kafka installation directory>/config/connect-file-sink.propertiesfile=<output file full path> topics=<my topic>
Source Connector (この例では、ソースファイルのコネクタ) を起動します。
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties config/kafka-connect-fs.propertiesSink Connector (この例では、シンクファイルのコネクタ) を実行します。
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-sink.propertiesKafka Connect の使用例については、AWS Glue Schema Registry 用 Githubリポジトリ
の、integration-tests フォルダにある run-local-tests.sh スクリプトでご確認ください。
