レコードマッチング変換を使用して既存のデータ分類変換を呼び出す
この変換は、既存のレコードマッチング機械学習データ分類変換を呼び出します。
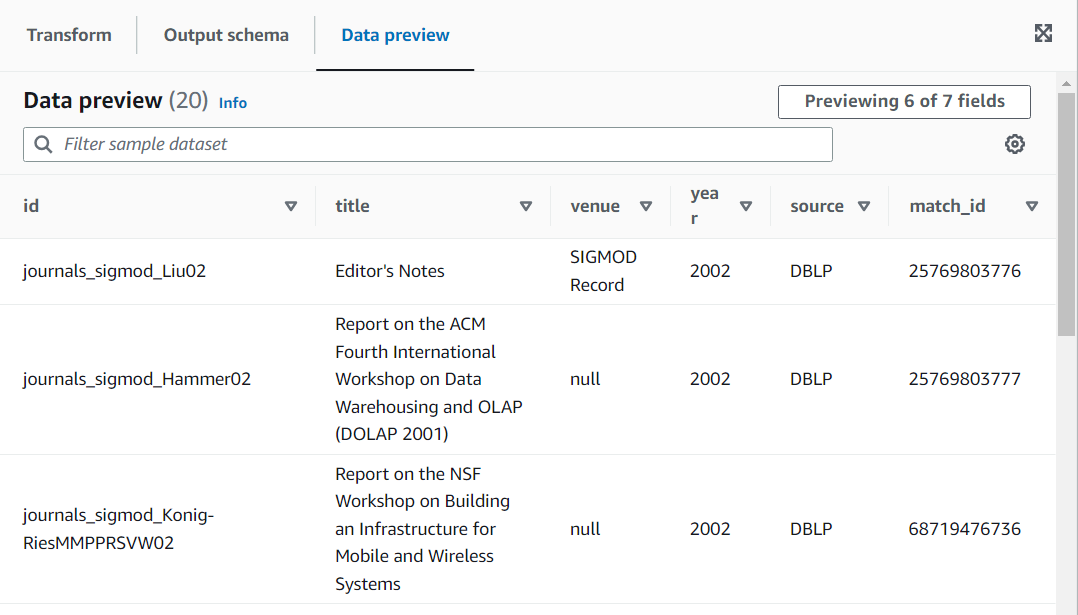
この変換は、ラベルに基づいて、トレーニング済みモデルに対して現在のデータを評価します。列「match_id」が追加され、アルゴリズムトレーニングに基づいて、同等とみなされる項目のグループに各行が割り当てられます。詳細については、「AWS Lake Formation FindMatches によるレコードのマッチング」を参照してください。
注記
ビジュアルジョブで使用する AWS Glue のバージョンは、レコードマッチング変換の作成時に AWS Glue で使用するバージョンと一致する必要があります。
レコードマッチング変換ノードをジョブ図に追加するには
-
リソースパネルを開いて、[Record Matching] を選択し、ジョブ図に新しい変換を追加します。ノードを追加する際に選択したノードが、その親になります。
ノードのプロパティパネルで、ジョブ図にノード名を入力します。ノードの親がまだ選択されていない場合、[Node parents] (ノードの親) リストから、変換の入力ソースとして使用するノードを選択します。
[変換] タブに、[機械学習の変換] ページから取得した ID を入力します。
(オプション) [変換] タブで、信頼スコアを追加するオプションを確認できます。計算量は増えますが、モデルは各マッチングの信頼スコアを追加の列として推定します。
