サポート終了通知: 2026 年 10 月 7 日、AWSはサポートを終了しますAWS IoT Greengrass Version 1。2026 年 10 月 7 日以降、AWS IoT Greengrass V1リソースにアクセスできなくなります。詳細については、「 からの移行AWS IoT Greengrass Version 1」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
サポートされている AWS クラウド 送信先のエクスポート設定
ユーザー定義の Lambda 関数は、 AWS IoT Greengrass Core SDK StreamManagerClientで を使用してストリームマネージャーとやり取りします。Lambda 関数は、ストリームの作成またはストリームの更新を行う際に、MessageStreamDefinition オブジェクト (エクスポート定義などのストリームプロパティ) を渡します。ExportDefinition オブジェクトには、そのストリームに定義されたエクスポート設定が含まれています。ストリームマネージャーは、これらのエクスポート設定を使用して、ストリームをエクスポートする場所と方法を決定します。
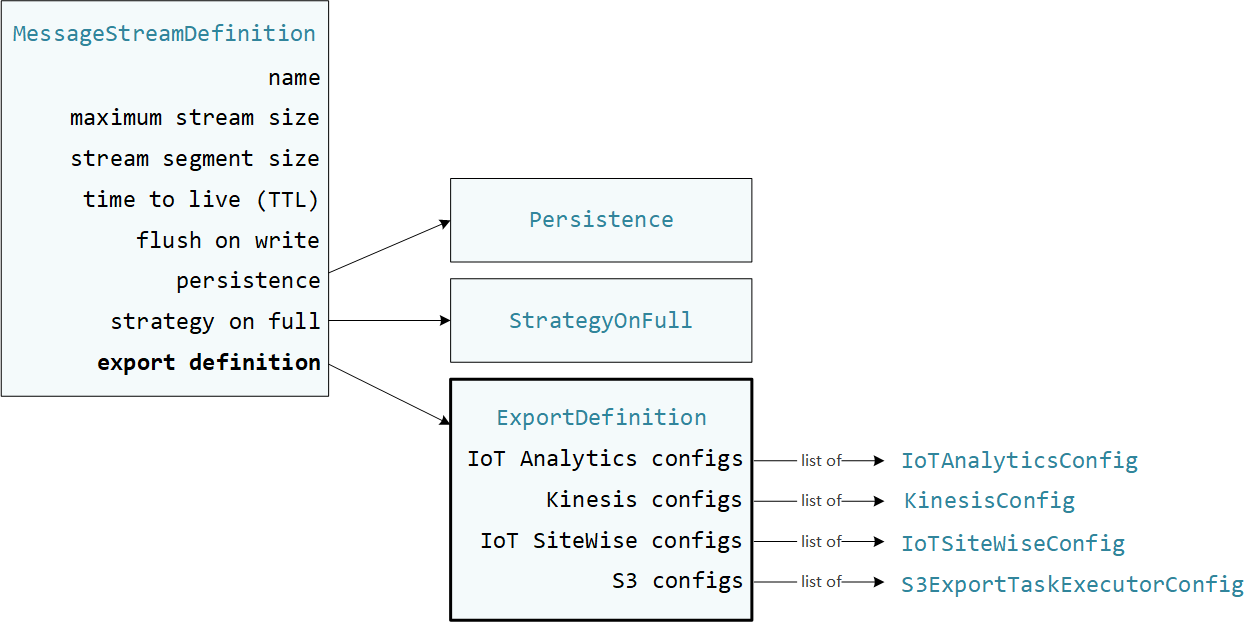
1 つのストリームに 0 または 1 つ以上のエクスポートを定義できます。この場合、1 つの送信先タイプに複数のエクスポートを定義することも可能です。例えば、ストリームを 2 つの AWS IoT Analytics チャネルと 1 つの Kinesis データストリームにエクスポートできます。
エクスポートに失敗した場合、ストリームマネージャーは最大 5 分間隔で AWS クラウド へのデータのエクスポートを継続的に再試行します。再試行回数に上限はありません。
注記
StreamManagerClient を利用すると、ターゲットの送信先を使用して、ストリームを HTTP サーバーにエクスポートできます。このターゲットは、テストのみを目的としています。本場環境での使用は安定しておらず、サポートされていません。
サポートされている AWS クラウド 送信先
これらの AWS クラウド リソースを維持する責任はお客様にあります。
AWS IoT Analytics チャネル
ストリームマネージャーは、 への自動エクスポートをサポートしています AWS IoT Analytics。 AWS IoT Analytics を使用すると、データに対して高度な分析を実行して、ビジネス上の意思決定を行い、機械学習モデルを改善できます。詳細については、「 とは」を参照してください AWS IoT Analytics。 AWS IoT Analytics 「 ユーザーガイド」の「」を参照してください。
AWS IoT Greengrass Core SDK では、Lambda 関数は IoTAnalyticsConfig を使用して、この送信先タイプのエクスポート設定を定義します。詳細については、ターゲット言語の SDK リファレンスを参照してください。
-
Python SDK の IoTAnalyticsConfig
-
Java SDK の IoTAnalyticsConfig
-
Node.js SDK の IoTAnalyticsConfig
要件
このエクスポート先には以下の要件があります。
-
のターゲットチャネルは、Greengrass グループと同じ AWS アカウント および AWS リージョン にある AWS IoT Analytics 必要があります。
-
Greengrass グループのロール は、ターゲットのチャネルに
iotanalytics:BatchPutMessage権限を許可する必要があります。例:リソースにきめ細かいアクセス権限または条件付きアクセス権限を付与できます (例えば、ワイルドカード
*命名スキームを使用)。詳細については、「IAM ユーザーガイド」の「IAM ID のアクセス許可の追加および削除」を参照してください。
へのエクスポート AWS IoT Analytics
にエクスポートするストリームを作成するには AWS IoT Analytics、Lambda 関数は 1 つ以上のオブジェクトを含むエクスポート定義を使用してストリームを作成します。 IoTAnalyticsConfigこのオブジェクトによって、ターゲットチャネル、バッチサイズ、バッチ間隔、優先度などのエクスポート設定を定義します。
Lambda 関数は、デバイスからデータを受信した際に、データの BLOB を含むメッセージをターゲットストリームに追加します。
その後、ストリームマネージャーは、ストリームのエクスポート設定で定義されたバッチ設定と優先度に基づいてデータをエクスポートします。
Amazon Kinesis Data Streams
ストリームマネージャーは、Amazon Kinesis Data Streams への自動エクスポートをサポートしています。Kinesis Data Streams は、一般的に、大量のデータを集約して、データウェアハウスまたは MapReduce クラスターに読み込むために使用されます。詳細については、「Amazon Kinesis デベロッパーガイド」の「Amazon Kinesis Data Streams とは」を参照してください。
AWS IoT Greengrass Core SDK では、Lambda 関数は KinesisConfig を使用して、この送信先タイプのエクスポート設定を定義します。詳細については、ターゲット言語の SDK リファレンスを参照してください。
-
Python SDK の KinesisConfig
-
Java SDK の KinesisConfig
-
Node.js SDK の KinesisConfig
要件
このエクスポート先には以下の要件があります。
-
Kinesis Data Streams のターゲットストリームは、Greengrass グループと同じ AWS アカウント および AWS リージョン にある必要があります。
-
Greengrass グループのロール は、ターゲットデータストリームに
kinesis:PutRecords権限を許可する必要があります。例:リソースにきめ細かいアクセス権限または条件付きアクセス権限を付与できます (例えば、ワイルドカード
*命名スキームを使用)。詳細については、「IAM ユーザーガイド」の「IAM ID のアクセス許可の追加および削除」を参照してください。
Kinesis Data Streams へのエクスポート
Kinesis Data Streams にエクスポートするストリームを作成するには、Lambda 関数で 1 つ以上の KinesisConfig オブジェクトを含むエクスポート定義を使用してストリームを作成します。このオブジェクトによって、ターゲットデータストリーム、バッチサイズ、バッチ間隔、優先度などのエクスポート設定を定義します。
Lambda 関数は、デバイスからデータを受信した際に、データの BLOB を含むメッセージをターゲットストリームに追加します。その後、ストリームマネージャーは、ストリームのエクスポート設定で定義されたバッチ設定と優先度に基づいてデータをエクスポートします。
ストリームマネージャーは、Amazon Kinesis にアップロードされた各レコードのパーティションキーとして、一意のランダムな UUID を生成します。
AWS IoT SiteWise アセットプロパティ
ストリームマネージャーは への自動エクスポートをサポートしています AWS IoT SiteWise。 AWS IoT SiteWise を使用すると、産業機器からデータを大規模に収集、整理、分析できます。詳細については、「 とは」を参照してください AWS IoT SiteWise。 AWS IoT SiteWise 「 ユーザーガイド」の「」を参照してください。
AWS IoT Greengrass Core SDK では、Lambda 関数は IoTSiteWiseConfig を使用して、この送信先タイプのエクスポート設定を定義します。詳細については、ターゲット言語の SDK リファレンスを参照してください。
-
Python SDK の IoTSiteWiseConfig
-
Java SDK の IoTSiteWiseConfig
-
Node.js SDK の IoTSiteWiseConfig
注記
AWS はIoT SiteWise コネクタ、OPC-UA ソースで使用できる構築済みのソリューションである も提供します。
要件
このエクスポート先には以下の要件があります。
-
のターゲットアセットプロパティは、Greengrass グループ AWS リージョン と同じ AWS アカウント および にある AWS IoT SiteWise 必要があります。
注記
が AWS IoT SiteWise サポートするリージョンのリストについては、 AWS 全般のリファレンスのAWS IoT SiteWise 「エンドポイントとクォータ」を参照してください。
-
Greengrass グループのロール は、ターゲットのアセットプロパティに
iotsitewise:BatchPutAssetPropertyValue権限を許可する必要があります。次の例では、ポリシーでiotsitewise:assetHierarchyPath条件キーを使用して、ターゲットルートアセットとその子へのアクセスを許可しています。ポリシーからConditionを削除して、すべての AWS IoT SiteWise アセットへのアクセスを許可したり、個々のアセットの ARN を指定したりできます。リソースにきめ細かいアクセス権限または条件付きアクセス権限を付与できます (例えば、ワイルドカード
*命名スキームを使用)。詳細については、「IAM ユーザーガイド」の「IAM ID のアクセス許可の追加および削除」を参照してください。重要なセキュリティ情報については、AWS IoT SiteWise ユーザーガイドの「BatchPutAssetPropertyValue 認証」を参照してください。
へのエクスポート AWS IoT SiteWise
にエクスポートするストリームを作成するには AWS IoT SiteWise、Lambda 関数は 1 つ以上のオブジェクトを含むエクスポート定義を使用してストリームを作成します。 IoTSiteWiseConfigこのオブジェクトによって、バッチサイズ、バッチ間隔、優先度などのエクスポート設定を定義します。
Lambda 関数は、デバイスからアセットプロパティデータを受信した際に、そのデータを含むメッセージをターゲットストリームに追加します。メッセージは、JSON シリアル化された PutAssetPropertyValueEntry オブジェクトであり、これには、1 つ以上のアセットプロパティに対するプロパティ値が含まれています。詳細については、 AWS IoT SiteWise のエクスポート先に関する「メッセージの追加」を参照してください。
注記
にデータを送信する場合 AWS IoT SiteWise、データは BatchPutAssetPropertyValueアクションの要件を満たしている必要があります。詳細については、「AWS IoT SiteWise API リファレンス」の「BatchPutAssetPropertyValue」を参照してください。
その後、ストリームマネージャーは、ストリームのエクスポート設定で定義されたバッチ設定と優先度に基づいてデータをエクスポートします。
ストリームマネージャーの設定と Lambda 関数ロジックを調整して、エクスポート対策を設計できます。例:
-
ほぼリアルタイムのエクスポートでは、少ないバッチサイズと短い間隔を設定して、受信したデータをストリームに追加します。
-
バッチの最適化、帯域幅の制約軽減、コスト最小化を行うには、Lambda 関数を使用して、受信した、単一アセットプロパティのタイムスタンプ品質値 (TQV) データポイントをプールし、その後、データをストリームに追加します。対策を 1 つ挙げるとすれば、それは、同じプロパティのエントリを複数送信するのではなく、最大 10 の異なるプロパティとアセットの組み合わせ、またはプロパティエイリアスのエントリを 1 つのメッセージでバッチ処理することです。これにより、ストリームマネージャーは AWS IoT SiteWise クォータ内にとどまることができます。
Amazon S3 オブジェクト
ストリームマネージャーは、Amazon S3 への自動エクスポートをサポートしています。Amazon S3 を使用すると、膨大なデータの保存と取得を行えます。詳細については、「Amazon Simple Storage Service デベロッパーガイド」の「Amazon S3 とは」参照してください。
AWS IoT Greengrass Core SDK では、Lambda 関数は S3ExportTaskExecutorConfig を使用して、この送信先タイプのエクスポート設定を定義します。詳細については、ターゲット言語の SDK リファレンスを参照してください。
-
Python SDK の S3ExportTaskExecutorConfig
-
Java SDK の S3ExportTaskExecutorConfig
-
Node.js SDK の S3ExportTaskExecutorConfig
要件
このエクスポート先には以下の要件があります。
-
ターゲット Amazon S3 バケットは Greengrass グループ AWS アカウント と同じ にある必要があります。
-
Greengrass グループのデフォルトのコンテナ化が Greengrass コンテナの場合に、
/tmp下にある入力ファイルディレクトリ、またはルートファイルシステム上にない入力ファイルディレクトリを使用するには、STREAM_MANAGER_READ_ONLY_DIRS パラメータを設定する必要があります。 -
Greengrass コンテナモードで実行している Lambda 関数によって入力ファイルを入力ファイルディレクトリに書き込む場合は、そのディレクトリ用にローカルボリュームリソースを作成し、書き込み権限でディレクトリをコンテナにマウントする必要があります。これにより、ファイルがルートファイルシステムに書き込まれ、コンテナ外に表示されるようになります。詳細については、「Lambda 関数とコネクタを使用してローカルリソースにアクセスする」を参照してください。
-
Greengrass グループのロール で、ターゲットのバケットに次の権限を許可する必要があります。例:
リソースにきめ細かいアクセス権限または条件付きアクセス権限を付与できます (例えば、ワイルドカード
*命名スキームを使用)。詳細については、「IAM ユーザーガイド」の「IAM ID のアクセス許可の追加および削除」を参照してください。
Amazon S3 へのエクスポート
Amazon S3 にエクスポートするストリームを作成するには、Lambda 関数で S3ExportTaskExecutorConfig オブジェクトを使用してエクスポートポリシーを設定します。このポリシーによって、マルチパートアップロードのしきい値や優先度といったエクスポート設定を定義します。Amazon S3 エクスポートでは、ストリームマネージャーが、コアデバイス上のローカルファイルから読み取るデータをアップロードします。アップロードを開始するには、Lambda 関数でエクスポートタスクをターゲットストリームに追加します。エクスポートタスクには、入力ファイルとターゲット Amazon S3 オブジェクトの情報が含まれます。ストリームマネージャーは、ストリームに追加された順にタスクを実行します。
注記
ターゲットバケットは に既に存在している必要があります AWS アカウント。指定したキーのオブジェクトが存在しない場合は、ストリームマネージャーによってオブジェクトが作成されます。
以下の図に、この高レベルのワークフローを示します。
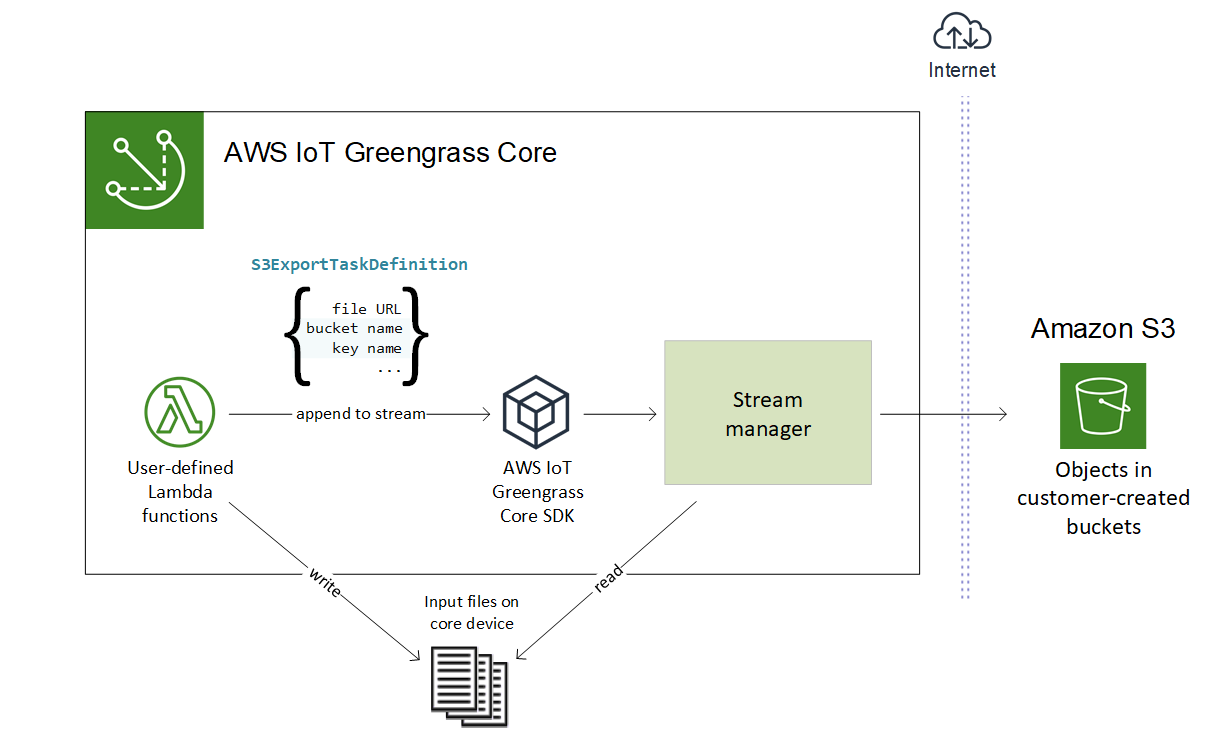
ストリームマネージャーは、マルチパートアップロードしきい値プロパティ、最小パーツサイズ設定、入力ファイルサイズを使用して、データのアップロード方法を決定します。マルチパートアップロードのしきい値は、最小パートサイズ以上でなければなりません。データを並行してアップロードする場合は、複数のストリームを作成できます。
ターゲット Amazon S3 オブジェクトを指定するキーには、有効な Java DateTimeFormatter!{timestamp: プレースホルダーに含めることができます。これらのタイムスタンププレースホルダーを使用すると、入力ファイルデータがアップロードされた時刻に基づいて Amazon S3 のデータを分割できます。例えば、次のキー名は、value}my-key/2020/12/31/data.txt などの値に解決されます。
my-key/!{timestamp:YYYY}/!{timestamp:MM}/!{timestamp:dd}/data.txt
注記
ストリームのエクスポートステータスを監視する場合は、まずステータスストリームを作成して、そのストリームを使用するようにエクスポートストリームを設定します。詳細については、「エクスポートタスクの監視」を参照してください。
入力データの管理
IoT アプリケーションが入力データのライフサイクル管理に使用するコードを作成できます。次のワークフロー例は、Lambda 関数を使用してこのデータを管理する方法を示しています。
-
ローカルプロセスは、デバイスまたは周辺機器からデータを受信し、コアデバイスのディレクトリ内にあるファイルにデータを書き込みます。これらが、ストリームマネージャーの入力ファイルとなります。
注記
入力ファイルディレクトリへのアクセスを設定する必要があるかどうかを判断するには、STREAM_MANAGER_READ_ONLY_DIRS パラメータを参照してください。
ストリームマネージャーが実行されるプロセスは、グループのデフォルトアクセス ID のファイルシステム権限をすべて継承します。ストリームマネージャーには、入力ファイルへのアクセス許可が必要です。必要に応じて、
chmod(1)コマンドを使用して、ファイルへのアクセス許可を変更できます。 -
Lambda 関数はディレクトリをスキャンし、新しいファイルが作成されると、ターゲットストリームにエクスポートタスクを追加します。このタスクは、JSON シリアル化された
S3ExportTaskDefinitionオブジェクトであり、これによって、入力ファイルの URL、ターゲットの Amazon S3 バケットとキー、オプションのユーザーメタデータが指定されます。 -
ストリームマネージャーは、入力ファイルを読み取り、追加されたタスクの順に Amazon S3 にデータをエクスポートします。ターゲットバケットは に既に存在している必要があります AWS アカウント。指定したキーのオブジェクトが存在しない場合は、ストリームマネージャーによってオブジェクトが作成されます。
-
Lambda 関数は、ステータスストリームからメッセージを読み取り、エクスポートステータスを監視します。エクスポートタスクが完了すると、Lambda 関数は対応する入力ファイルを削除します。詳細については、「エクスポートタスクの監視」を参照してください。
エクスポートタスクの監視
IoT アプリケーションが Amazon S3 エクスポートのステータス監視に使用するコードを作成できます。Lambda 関数は、ステータスストリームを作成して、そのストリームにステータス更新を書き込むようにエクスポートストリームを設定する必要があります。1 つのステータスストリームは、Amazon S3 にエクスポートする複数のストリームからステータスの更新を受け取ることができます。
まず、ステータスストリームとして使用するストリームを作成します。ストリームのサイズとリテンションポリシーを設定して、ステータスメッセージのライフスパンを制御できます。例:
-
ステータスメッセージを保存しない場合は、
PersistenceをMemoryに設定します。 -
新しいステータスメッセージが失われないようにするには、
StrategyOnFullをOverwriteOldestDataに設定します。
次に、ステータスストリームを使用するようにエクスポートストリームを作成または更新します。具体的には、ストリームの S3ExportTaskExecutorConfig エクスポート設定のステータス構成プロパティを設定します。これにより、エクスポートタスクに関するステータスメッセージをステータスストリームに書き込むようにストリームマネージャーに指示します。StatusConfig オブジェクトで、ステータスストリームの名前と冗長性のレベルを指定します。サポート対象の値を次に示します。最も冗長でないもの (ERROR) から最も冗長なもの (TRACE) を表しています。デフォルトは INFO です。
-
ERROR -
WARN -
INFO -
DEBUG -
TRACE
次のワークフロー例は、Lambda 関数がステータスストリームを使用してエクスポートステータスを監視する方法を示しています。
-
前のワークフローで説明したように、Lambda 関数は、エクスポートタスクに関するステータスメッセージをステータスストリームに書き込むように設定されたストリームにエクスポートタスクを追加します。この追加の操作によって、タスク ID を表すシーケンス番号が返ります。
-
Lambda 関数は、ステータスストリームからメッセージを順番に読み取ります。その後、ストリーム名とタスク ID に基づいて、またはメッセージコンテキストからのエクスポートタスクプロパティに基づいてメッセージをフィルタリングします。例えば、Lambda 関数は、エクスポートタスクの入力ファイル URL でフィルタリングできます。このタスクは、メッセージコンテキストの
S3ExportTaskDefinitionオブジェクトで表されます。次のステータスコードは、エクスポートタスクが完了の状態になったことを示します。
-
Success。アップロードは正常に完了しました。 -
Failure。ストリームマネージャーでエラー (例: 指定したバケットが存在しないなど) が発生しました。問題の解決後に、エクスポートタスクをストリームに再度追加できます。 -
Canceled。ストリームまたはエクスポートの定義が削除された、もしくはタスクの存続期間 (TTL) の有効期限が切れたため、タスクは中止されました。
注記
タスクのステータスは
InProgressまたはWarningの場合もあります。ストリームマネージャーは、タスクの実行に影響しないエラーがイベントから返ったときに警告を発行します。例えば、中断された部分的アップロードのクリーンアップが失敗すると、警告を返します。 -
-
エクスポートタスクが完了すると、Lambda 関数は対応する入力ファイルを削除します。
次の例は、Lambda 関数がステータスメッセージを読み取り、処理する方法を示しています。
