翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
オフライン移行プロセス: Apache Cassandra から Amazon Keyspaces への移行
オフライン移行は、移行時にダウンタイムを許容できる場合に適しています。企業では、パッチの適用や大規模リリース、またはハードウェアのアップグレードやメジャーアップグレードによるダウンタイムに備えて、メンテナンスウィンドウを設けることが一般的です。オフライン移行では、このウィンドウを利用してデータをコピーし、アプリケーショントラフィックを Apache Cassandra から Amazon Keyspaces に切り替えることができます。
オフライン移行の場合、Cassandra と Amazon Keyspaces の双方と同時に通信する必要がないため、アプリケーションの変更の手間を省けます。また、データフローを一時停止して、そのままの状態をコピーでき、途中変更の管理も不要です。
ここで紹介する例では、オフライン移行中のデータのステージングエリアとして Amazon Simple Storage Service (Amazon S3) を活用し、ダウンタイムを最小限に抑えます。Spark Cassandra コネクタと AWS Glueを使用して、Amazon S3 に Parquet 形式で保存されているデータを Amazon Keyspaces テーブルに自動的にインポートできます。この後のセクションでは、このプロセスの大筋を説明します。このプロセスのコード例は、Github
Amazon S3 を使用した Apache Cassandra から Amazon Keyspaces へのオフライン移行プロセスには、次の AWS Glue ジョブ AWS Glue が必要です。
CQL データを抽出して変換し、Amazon S3 バケットに保存する ETL ジョブ。
バケットから Amazon Keyspaces にデータをインポートする 2 つ目のジョブ。
増分データをインポートする 3 つ目のジョブ。
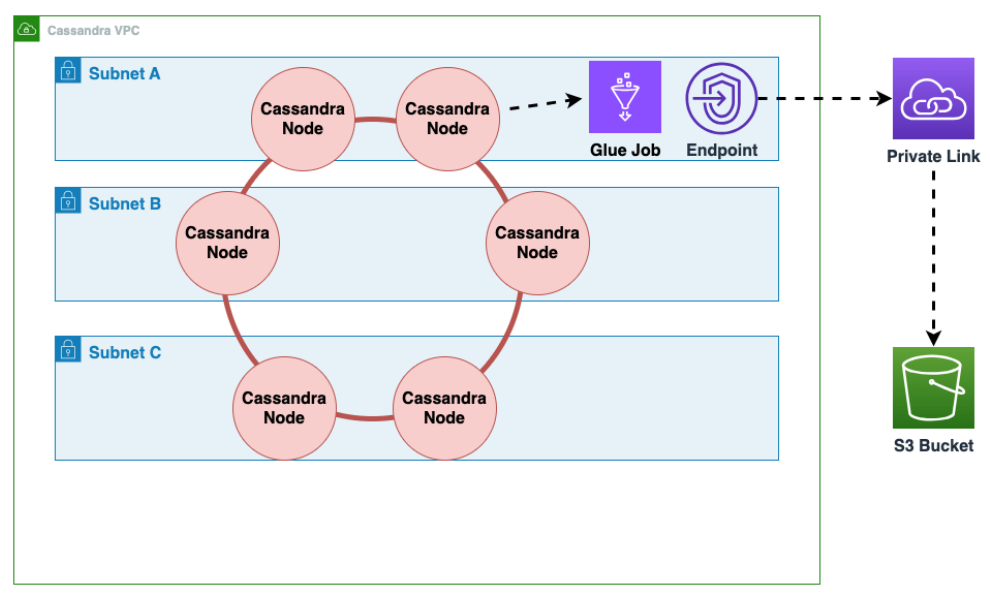
Amazon Virtual Private Cloud の Amazon EC2 で実行されている Cassandra から Amazon Keyspaces へのオフライン移行の実行方法
まず AWS Glue 、 を使用して Cassandra から Parquet 形式でテーブルデータをエクスポートし、Amazon S3 バケットに保存します。Cassandra を実行している Amazon EC2 インスタンスが存在する VPC への AWS Glue コネクタを使用して AWS Glue ジョブを実行する必要があります。その後、Amazon S3 プライベートエンドポイントを使用して、Amazon S3 バケットにデータを保存できます。
次の図は、これらの手順の流れを示しています。
Amazon S3 バケット内のデータをシャッフルして、データのランダム性を高めます。データを均等にインポートすれば、ターゲットテーブルでトラフィックをより分散させることができます。
この手順は、パーティションが大きい (1000 行を超えるパーティション) Cassandra からデータをエクスポートして、Amazon Keyspaces に挿入する場合に、ホットキーのパターンを回避するために必要です。ホットキーの問題が生じると、Amazon Keyspaces で
WriteThrottleEventsが発生し、ロード時間が長引きます。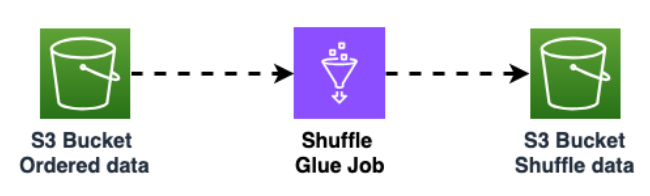
別の AWS Glue ジョブを使用して、Amazon S3 バケットから Amazon Keyspaces にデータをインポートします。シャッフル後のデータは Amazon S3 バケット内に Parquet 形式で保存されます。

オフライン移行プロセスの詳細については、 を使用した Amazon Keyspaces AWS Glue
