慎重に検討した結果、Amazon Kinesis Data Analytics for SQL アプリケーションを中止することにしました。
1. 2025 年 9 月 1 日以降、Amazon Kinesis Data Analytics for SQL アプリケーションのバグ修正は提供されません。これは、今後の廃止によりサポートが制限されるためです。
2. 2025 年 10 月 15 日以降、新しい Kinesis Data Analytics for SQL アプリケーションを作成することはできません。
3. 2026 年 1 月 27 日以降、アプリケーションは削除されます。Amazon Kinesis Data Analytics for SQL アプリケーションを起動することも操作することもできなくなります。これ以降、Amazon Kinesis Data Analytics for SQL のサポートは終了します。詳細については、「Amazon Kinesis Data Analytics for SQL アプリケーションのサポート終了」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
例: ROWTIME を使用したタンブリングウィンドウ
ウィンドウクエリが各ウィンドウを重複しない方式で処理する場合、ウィンドウはタンブリングウィンドウと呼ばれます。詳細については、「タンブリングウィンドウ (GROUP BY を使用した集計)」を参照してください。この Amazon Kinesis Data Analytics の例では、ROWTIME 列を使用してタンブリングウィンドウを作成します。ROWTIME 列は、アプリケーションによってレコードが読み取られた時間を表します。
この例では、次のレコードを Kinesis データストリームに書き込みます。
{"TICKER": "TBV", "PRICE": 33.11} {"TICKER": "INTC", "PRICE": 62.04} {"TICKER": "MSFT", "PRICE": 40.97} {"TICKER": "AMZN", "PRICE": 27.9} ...
次に、Kinesis データストリームをストリーミングソースとして AWS Management Console、 で Kinesis Data Analytics アプリケーションを作成します。検出プロセスでストリーミングソースのサンプルレコードが読み込まれます。次のように、アプリケーション内スキーマに 2 つの列 (TICKER および PRICE) があると推察します。
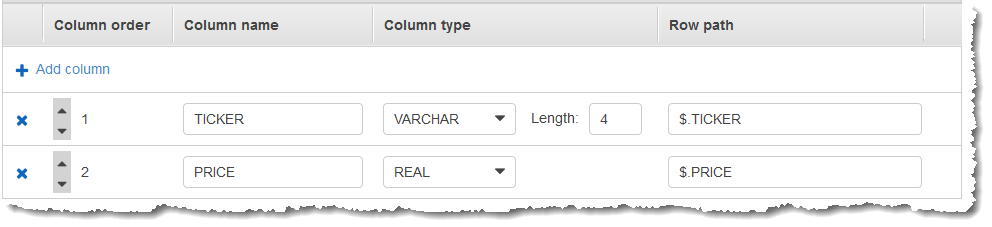
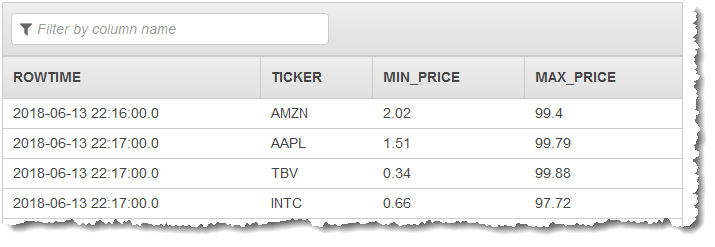
データのウィンドウ集約を作成するには、アプリケーションコードで MIN 関数および MAX 関数を使用します。続いて、次のスクリーンショットに示すように、生成されたデータを別のアプリケーション内ストリームに挿入します。
次の手順では、ROWTIME に基づき、タンブリングウィンドウの入力ストリームに値を集約する Kinesis Data Analytics アプリケーションを作成します。
ステップ 1: Kinesis データストリームを作成する
次のように、Amazon Kinesis データストリームを作成して、レコードを追加します。
にサインイン AWS Management Console し、https://console.aws.amazon.com/kinesis
で Kinesis コンソールを開きます。 -
ナビゲーションペインで、[データストリーム] を選択します。
-
[Kinesis ストリームの作成] を選択後、1 つのシャードがあるストリームを作成します。詳細については、「Amazon Kinesis Data Streams デベロッパーガイド」の「Create a Stream」を参照してください。
-
本稼働環境の Kinesis データストリームにレコードを書き込むには、Kinesis Client Library または Kinesis Data Streams API を使用することをお勧めします。わかりやすいように、この例では、以下の Python スクリプトを使用してレコードを生成します。サンプルのティッカーレコードを入力するには、このコードを実行します。このシンプルなコードによって、ランダムなティッカーレコードが連続してストリームに書き込まれます。後のステップでアプリケーションスキーマを生成できるように、スクリプトを実行したままにしておきます。
import datetime import json import random import boto3 STREAM_NAME = "ExampleInputStream" def get_data(): return { "EVENT_TIME": datetime.datetime.now().isoformat(), "TICKER": random.choice(["AAPL", "AMZN", "MSFT", "INTC", "TBV"]), "PRICE": round(random.random() * 100, 2), } def generate(stream_name, kinesis_client): while True: data = get_data() print(data) kinesis_client.put_record( StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey" ) if __name__ == "__main__": generate(STREAM_NAME, boto3.client("kinesis"))
ステップ 2: Kinesis Data Analytics アプリケーションを作成する
次のように Kinesis Data Analytics アプリケーションを作成します。
https://console.aws.amazon.com/kinesisanalytics
にある Managed Service for Apache Flink コンソールを開きます。 -
[アプリケーションの作成] を選択し、アプリケーション名を入力して、[アプリケーションの作成] を選択します。
-
アプリケーション詳細ページで、[ストリーミングデータの接続] を選択してソースに接続します。
-
[ソースに接続] ページで、以下の操作を実行します。
-
前のセクションで作成したストリームを選択します。
-
[スキーマの検出] を選択します。作成されたアプリケーション内ストリーム用の推測スキーマと、推測に使用されたサンプルレコードがコンソールに表示されるまで待ちます。推測されたスキーマには 2 つの列があります。
-
[Save schema and update stream samples] を選択します。コンソールでスキーマが保存されたら、[終了] を選択します。
-
[保存して続行] を選択します。
-
-
アプリケーション詳細ページで、[SQL エディタに移動] を選択します。アプリケーションを起動するには、表示されたダイアログボックスで [はい、アプリケーションを起動します] を選択します。
-
SQL エディタで、次のように、アプリケーションコードを作成してその結果を確認します。
-
次のアプリケーションコードをコピーしてエディタに貼り付けます。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (TICKER VARCHAR(4), MIN_PRICE REAL, MAX_PRICE REAL); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM TICKER, MIN(PRICE), MAX(PRICE) FROM "SOURCE_SQL_STREAM_001" GROUP BY TICKER, STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND); -
[Save and run SQL] を選択します。
[リアルタイム分析] タブに、アプリケーションで作成されたすべてのアプリケーション内ストリームが表示され、データを検証できます。
-
