レイヤーによる Lambda 依存関係の管理
Lambda レイヤーは、補助的なコードやデータを含む .zip ファイルアーカイブです。レイヤーには通常、ライブラリの依存関係、カスタムランタイム、または設定ファイルが含まれています。
レイヤーの使用を検討する理由は複数あります。
-
デプロイパッケージのサイズを小さくするため。関数コードとともにすべての関数依存関係をデプロイパッケージに含める代わりに、レイヤーに配置します。これにより、デプロイパッケージは小さく整理された状態に保たれます。
-
コア関数ロジックを依存関係から分離するため。レイヤーを使用すると、関数コードと独立して関数の依存関係を更新でき、その逆も可能となります。これにより、関心事の分離が促進され、関数ロジックに集中することができます。
-
複数の関数間で依存関係を共有するため。レイヤーを作成したら、それをアカウント内の任意の数の関数に適用できます。レイヤーがない場合、個々のデプロイパッケージに同じ依存関係を含める必要があります。
-
Lambda コンソールのコードエディターを使用するため。コードエディターは、関数コードの軽微な更新をすばやくテストするのに便利なツールです。ただし、デプロイパッケージのサイズが大きすぎる場合は、エディターを使用できません。レイヤーを使用すると、パッケージのサイズが小さくなり、コードエディターの使用制限を解除できます。
-
組み込み SDK バージョンをロックするため。AWS が新しいサービスや機能をリリースすると、組み込み SDK は予告なく変更される場合があります。SDK バージョンは、必要な特定のバージョンで Lambda レイヤーを作成することでロックできます。その後、サービスに組み込まれたバージョンが変更されても、関数は常にレイヤーのバージョンを使用します。
Go や Rust で Lambda 関数を使用している場合は、レイヤーを使用しないことをお勧めします。Go 関数と Rust 関数の場合、関数コードが実行可能ファイルになります。つまり、コンパイル済みの関数コードがそのすべての依存関係と共に含まれています。レイヤーに依存関係を配置した場合、他に必要なアセンブリがあれば、初期化フェーズ中にいちいちロードされるため、コールドスタート時間が長くなる可能性があります。Go 関数と Rust 関数で最適なパフォーマンスが得られるよう、デプロイパッケージと共に依存関係を含めてください。
次の図は、依存関係を共有する 2 つの関数間の大まかなのアーキテクチャの違いを示しています。一方は Lambda レイヤーを使用し、もう一方は使用しません。
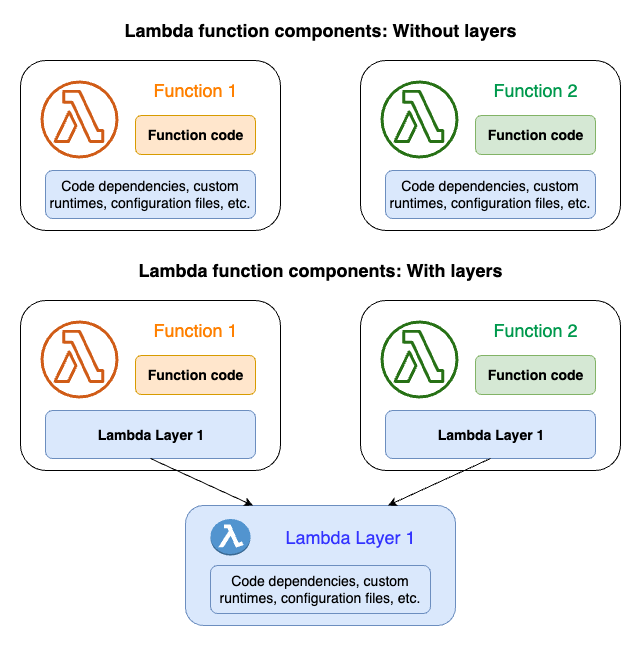
関数にレイヤーを追加すると、Lambda は関数の実行環境の /opt ディレクトリにレイヤーのコンテンツを抽出します。ネイティブにサポートされているすべての Lambda ランタイムには、/opt ディレクトリ内の特定のディレクトリへのパスが含まれています。これにより、関数はレイヤーコンテンツにアクセスできるようになります。これらの特定のパスの詳細とレイヤーを適切にパッケージ化する方法については、レイヤーコンテンツのパッケージング を参照してください。
各関数につき最大 5 つのレイヤーを含めることができます。また、レイヤーは、.zip ファイルアーカイブとしてデプロイされた Lambda 関数でのみ使用できます。コンテナイメージとして定義された関数では、コンテナイメージの作成時に、優先ランタイムとすべてのコード依存関係をパッケージ化します。詳細については、AWS コンピューティングブログの「コンテナイメージの Lambda レイヤーと拡張機能を使用する
トピック
レイヤーの使用方法
レイヤーを作成するには、通常のデプロイパッケージの作成と同様に、依存関係を .zip ファイルにパッケージ化します。具体的には、レイヤーの作成と使用の一般的なプロセスには、次の 3 つのステップが含まれます。
-
まず、レイヤーコンテンツをパッケージ化します。これは .zip ファイルアーカイブを作成することを意味します。詳細については、「レイヤーコンテンツのパッケージング」を参照してください。
-
次に、Lambda でレイヤーを作成します。詳細については、「Lambda でのレイヤーの作成と削除」を参照してください。
-
レイヤーを関数に追加します。詳細については、「関数へのレイヤーの追加」を参照してください。
レイヤーとレイヤーバージョン
レイヤーのバージョンは、レイヤーの特定のバージョンの不変のスナップショットです。新しいレイヤーを作成すると、Lambda はバージョン番号 1 の新しいレイヤーバージョンを作成します。レイヤーの更新を発行するたびに、Lambda はバージョン番号を増やし、新しいレイヤーバージョンを作成します。
すべてのレイヤーバージョンは、一意の Amazon リソースネーム (ARN) により識別されます。レイヤーを関数に追加する際、使用するレイヤーバージョンを正確に指定する必要があります (arn:aws:lambda:us-east-1:123456789012:layer:my-layer: など)。1
