Amazon Machine Learning サービスの更新や、その新しいユーザーの受け入れは行っていません。このドキュメントは既存のユーザー向けに提供されていますが、更新は終了しています。詳細については、「Amazon Machine Learning とは」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データ洞察
Amazon ML は、データを理解するために使用できる入力データに関する記述統計を計算します。
記述統計
Amazon ML はさまざまな属性タイプについて、以下の記述統計を計算します。
数値:
-
分布ヒストグラム
-
無効な値の数
-
最小値、中央値、平均値、最大値
バイナリとカテゴリ。
-
カウント (カテゴリごとに異なる値のもの)
-
値分布ヒストグラム
-
最も頻繁な値
-
一意の値の数
-
真の値の割合 (バイナリのみ)
-
最も目立つワード
-
最も頻繁なワード
テキスト:
-
属性の名前
-
ターゲットとの相関 (ターゲットが設定されている場合)
-
合計ワード数
-
一意のワード
-
行内のワード数の範囲
-
ワードの長さの範囲
-
最も目立つワード
Amazon ML コンソールでのデータインサイトへのアクセス
Amazon ML コンソールで、任意のデータソースの名前または ID を選択して、[Data Insights] (データインサイト) ページを表示できます。このページでは、次の情報を含め、データソースに関連付けられた入力データについて学習するためのメトリクスと視覚化を提供します。
-
データの要約
-
目標分布
-
欠落した値
-
Invalid values (無効な値)
-
データ型別の変数のサマリー統計
-
データ型別の変数の分布
以下のセクションでは、メトリクスと可視化について詳しく説明します。
データの要約
データソースのデータ要約レポートには、データソース ID、名前、完了した場所、現在のステータス、ターゲット属性、入力データ情報 (S3 バケットの場所、データフォーマット、処理されたレコードの数および処理中に発生した不良レコードの数) およびデータ型別の変数の数を示します。
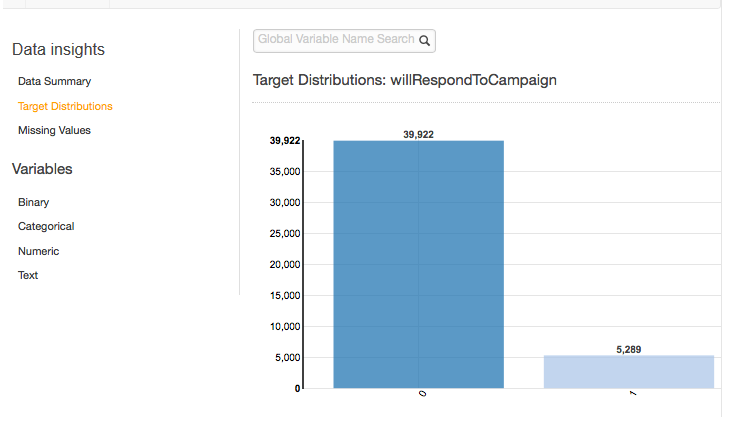
目標分布
ターゲット分布レポートには、データソースのターゲット属性の分布が表示されます。次の例では、willRespondToCampaign ターゲット属性が 0 に等しい 39,922 回の観測があります。これは、E メールキャンペーンに応答しなかった顧客の数です。willRespondToCampaign が 1 に等しい 5,289 回の観測があります。これは、E メールキャンペーンに応答した顧客の数です。
欠落した値
欠落した値のレポートには、値が欠落している入力データの属性がリストされます。数値データ型の属性のみが欠落した値を持つ可能性があります。欠落した値は ML モデルのトレーニングの質に影響する可能性があるため、可能であれば、欠落した値を提示することを推奨します。
ML モデルのトレーニング中に、ターゲット属性が見つからない場合、Amazon ML は対応するレコードを拒否します。ターゲット属性がレコードに存在するが、別の数値属性の値が欠落している場合、Amazon ML は欠落した値を見落とします。この場合、Amazon ML は代替属性を作成し、それを 1 に設定して、この属性が欠落していることを示します。これにより、Amazon ML は欠落した値の発生からパターンを学習できます。
無効な値
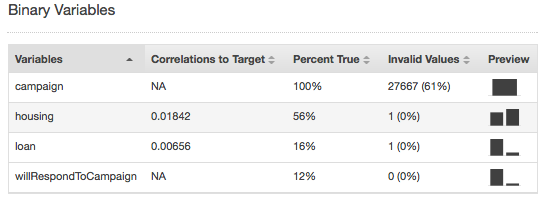
無効な値は、数値データ型とバイナリデータ型でのみ発生します。無効な値は、データ型レポートの変数のサマリー統計を表示して見つけることができます。次の例では、duration 数値属性に 1 つの無効な値とバイナリデータ型 (housing 属性に 1 つと loan 属性に 1 つ) に 2 つの無効な値があります。

変数とターゲットの相関
データソースを作成すると、Amazon ML はデータソースを評価し、変数とターゲットの間の相関や影響を特定できます。たとえば、製品の価格はベストセラーであるかどうかに大きな影響を及ぼす可能性がありますが、製品のディメンションには予測力がほとんどない可能性があります。
できるだけ多くの変数をトレーニングデータに含めることが一般的にはベストプラクティスです。しかし、予測力の少ない多くの変数を含めることによって導入されるノイズは、ML モデルの品質と精度に悪影響を与える可能性があります。
モデルをトレーニングするときに影響の少ない変数を削除することで、モデルの予測パフォーマンスを向上させることができます。レシピで機械学習プロセスで使用できる変数を定義することができます。これは Amazon ML の変換メカニズムです。レシピの詳細については、「機械学習のデータ変換」を参照してください。
データ型別の属性のサマリー統計
データ洞察レポートでは、次のデータ型で属性サマリー統計を表示できます。
-
バイナリ
-
カテゴリ
-
数値
-
テキスト
バイナリデータ型のサマリー統計には、すべてのバイナリ属性が表示されます。[ターゲットとの相関関係] 列には、ターゲット列と属性列の間で共有される情報が表示されます。[true の割合] 列には、値 1 の観測値の割合が表示されます。[Invalid values (無効な値)] 列には、無効な値の数と各属性の無効な値の割合が表示されます。[プレビュー] 列には、各属性のグラフィカルな分布へのリンクがあります。
カテゴリデータ型のサマリー統計は、一意の値の数、最も頻繁な値、および最も低い頻度の値を持つすべてのカテゴリ属性を示します。[プレビュー] 列には、各属性のグラフィカルな分布へのリンクがあります。
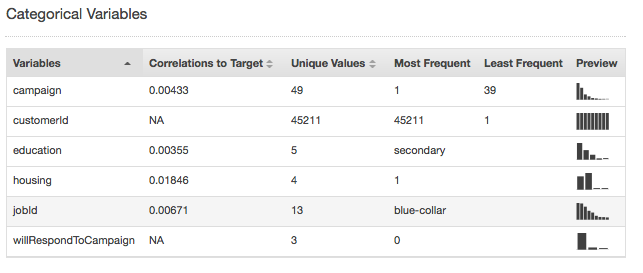
数値データ型のサマリー統計には、欠落した値の数、無効な値、値の範囲、平均値、および中央値を含むすべての数値属性が表示されます。[プレビュー] 列には、各属性のグラフィカルな分布へのリンクがあります。
テキストデータ型のサマリー統計は、すべてのテキスト属性、属性内の単語の総数、属性内の一意のワードの数、属性内の単語の範囲、語長の範囲、および最も目立つワードを表示します。[プレビュー] 列には、各属性のグラフィカルな分布へのリンクがあります。
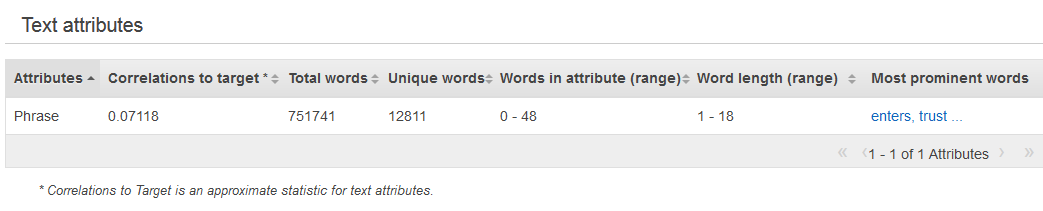
次の例は、4 つのレコードを持つレビューというテキスト変数のテキストデータ型統計を示しています。
1. The fox jumped over the fence. 2. This movie is intriguing. 3. 4. Fascinating movie.
この例の列には、次の情報が表示されます。
-
[属性] 列には、変数の名前が表示されます。この例では、この列には「レビュー」と表示されます。
-
[ターゲットとの相関関係] 列は、ターゲットが指定されている場合にのみ存在します。相関は、この属性がターゲットに関して提供する情報の量を測定します。相関が高いほど、この属性はターゲットについてより多くの情報を示します。相関は、テキスト属性の簡略化された表現とターゲットとの間の相互情報の観点から測定されます。
-
[合計ワード数] 列には、各レコードをトークン化して生成された単語の数が表示され、空白で区切られます。この例では、この列には「12」と表示されます。
-
[一意のワード] 列には、属性の一意の単語の数が表示されます。この例では、この列には「10」と表示されます。
-
[属性内のワード (範囲)] 列には、属性内の 1 行の単語数が表示されます。この例では、この列には「0~6」と表示されます。
-
[ワードの長さ (範囲)] 列には、単語に含まれる文字の数の範囲が示されます。この例では、この列には「2~11」と表示されます。
-
[最も目立つワード] 列には、属性に表示される単語のランク付けされたリストが表示されます。ターゲット属性がある場合、単語はターゲットとの相関によってランク付けされます。つまり、相関が最も高い単語が最初にリストされます。データ内にターゲットが存在しない場合、単語はそのエントロピーによってランク付けされます。
カテゴリ属性とバイナリ属性の分布を理解する
カテゴリまたはバイナリ属性に関連付けられた [プレビュー] リンクをクリックすると、その属性の分布および属性の各カテゴリ値に対する入力ファイルのサンプルデータを表示できます。
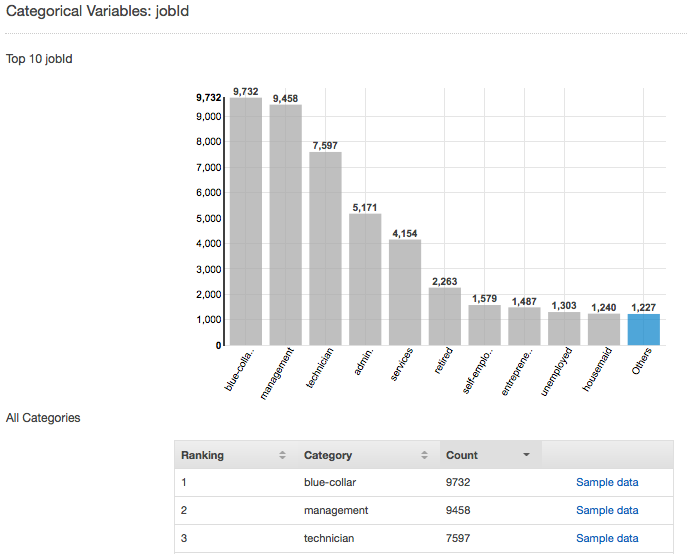
たとえば、次のスクリーンショットは、カテゴリ属性 jobId の分布を示しています。分布には上位 10 個のカテゴリ値が表示され、他のすべての値は「その他」にグループ化されています。その値を含む入力ファイル内の観測数と、入力データファイルからのサンプル観測を表示するためのリンクとの上位 10 個のカテゴリ値をランク付けします。
数値属性の分布について
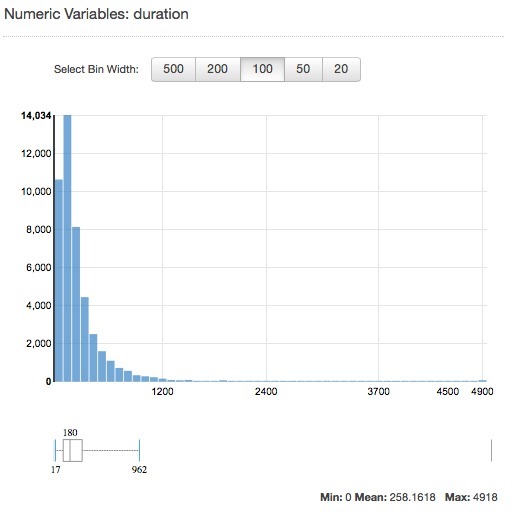
数値属性の分布を表示するには、属性の [プレビュー] リンクをクリックします。数値属性の分布を表示する際には、500、200、100、50、20 のビンサイズを選択できます。ビンサイズが大きいほど、表示される棒グラフの数は少なくなります。さらに、大きなビンサイズの場合、分布の解像度は粗くなります。反対に、バケットサイズを 20 に設定すると、表示される分布の解像度が向上します。
次のスクリーンショットに示すように、最小値、平均値、最大値も表示されます。
テキスト属性の分布について
テキスト属性の分布を表示するには、属性の [プレビュー] リンクをクリックします。テキスト属性の分布を見ると、次の情報が表示されます。
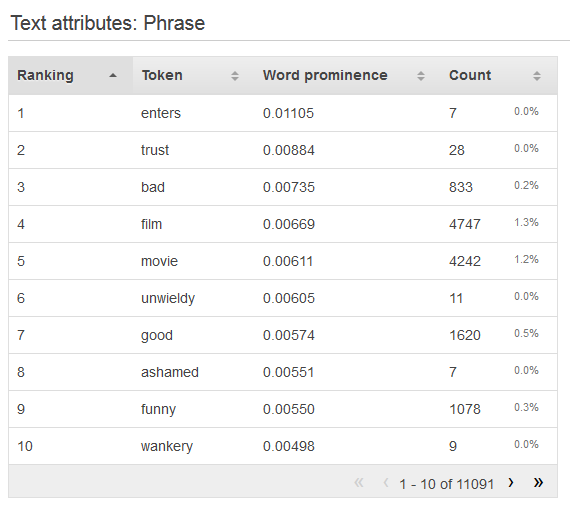
- ランキング
-
テキストトークンは、伝達する情報の量によってランク付けされ、最も有益なものから最も有益なものに分類されます。
- Token
-
トークンは、入力テキストから統計行が表示されている単語を表示します。
- ワードプロミネンス
-
ターゲット属性がある場合、単語はターゲットとの相関によってランク付けされ、相関が最も高いワードが最初にリストされます。データにターゲットが存在しない場合、単語はエントロピー、すなわち通信可能な情報の量によってランク付けされます。
- カウント数
-
カウント数は、トークンが表示した入力レコードの数を示します。
- カウント割合
-
カウント割合は、トークンが表示された入力データ行の割合を示します。
