Amazon Machine Learning サービスの更新や、その新しいユーザーの受け入れは行っていません。このドキュメントは既存のユーザー向けに提供されていますが、更新は終了しています。詳細については、「Amazon Machine Learning とは」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ステップ 2: トレーニングデータソースを作成する
banking.csv データセットを Amazon Simple Storage Service (Amazon S3) の場所にアップロードした後で、それを使用してトレーニングデータソースを作成します。データソースは、入力データの場所と入力データに関する重要なメタデータが保存されている Amazon Machine Learning (Amazon ML) オブジェクトです。Amazon ML は、ML モデルのトレーニングや評価などの操作でデータソースを使用します。
データソースを作成するには、以下を指定します。
-
データの Amazon S3 の場所とデータへのアクセス許可
-
データ内の属性の名前および各属性の型 (数値、文字、カテゴリ、またはバイナリ) を含むスキーマ
-
Amazon ML が予測を学習して応答する属性の名前、つまりターゲット属性
注記
データソースは参照のみで、実際にはデータを保存しません。Amazon S3 に保存されているファイルを移動または変更しないようにします。移動または変更した場合、Amazon ML は ML モデルの作成、評価の生成、または予測の生成のためにそれらにアクセスできなくなります。
トレーニングデータソースを作成するには
Amazon Machine Learning コンソール (https://console.aws.amazon.com/machinelearning/
) を開きます。 -
[開始する] を選択します。
注記
このチュートリアルでは、Amazon ML を初めて使用することを前提としています。Amazon ML を使用したことがある場合は、Amazon ML ダッシュボードの [Create new...] (新規作成...) ドロップダウンリストを使用して、データソースを新規に作成します。
-
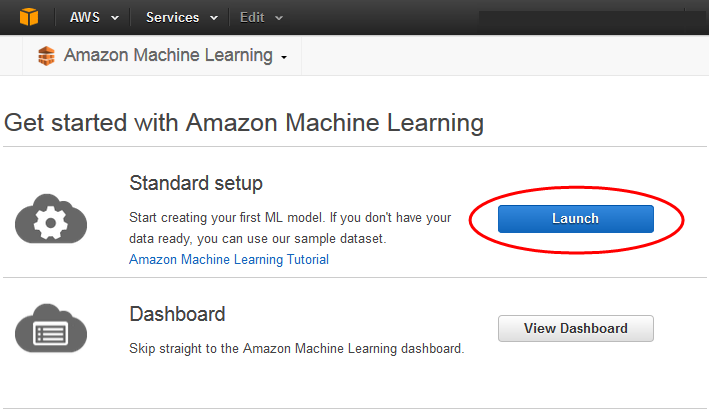
[Get started with Amazon Machine Learning] (Amazon Machine Learning の使用開始) ページで、[Launch] (起動) を選択します。
-
[入力データ] ページの、[データの場所] で [S3] が選択されていることを確認します。

-
[S3 の場所] には、「ステップ 1: データを準備する」で作成した
banking.csvファイルの完全な場所を入力します。例えば、your-bucket/banking.csvなどです。Amazon ML がバケット名に s3:// を付加します。 -
[データソース名] に「
Banking Data 1」を入力します。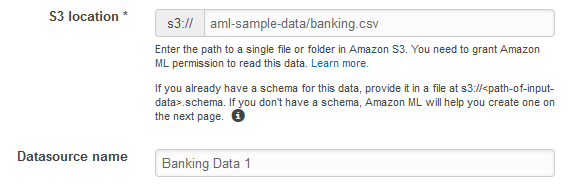
-
確認を選択します。
-
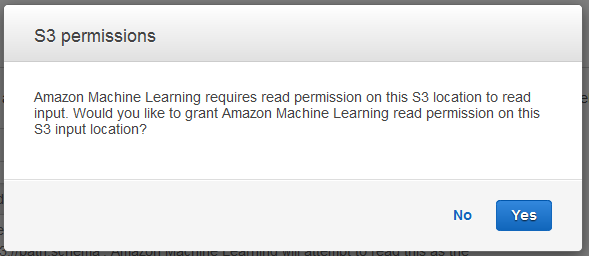
[S3 アクセス権限] ダイアログボックスで、[はい] を選択します。
-
Amazon ML が S3 の場所でデータファイルにアクセスでき読み取れた場合は、次のようなページが表示されます。プロパティを確認し、[続行] を選択します。

次に、スキーマを確立します。スキーマとは、Amazon ML が入力データを ML モデル用に解釈するために必要な情報のことです。それには、属性の名前および割り当てられたデータタイプ、特殊な属性の名前などがあります。Amazon ML にスキーマに渡すには、2 つの方法があります。
-
Amazon S3 データをアップロードするときに、別のスキーマファイルを提供します。
-
Amazon ML に属性タイプの推測とスキーマの作成を許可します。
このチュートリアルでは、Amazon ML にスキーマを推測させます。
別のスキーマファイルの作成の詳細については、「Amazon ML のデータスキーマを作成する」を参照してください。
Amazon ML にスキーマを推測させるには
-
[Schema] (スキーマ) ページに、Amazon ML が推測したスキーマが表示されます。Amazon ML が推測した属性のデータ型を確認します。Amazon ML がデータを正しく取り込み、属性に正しい機能処理が行われるために重要な点は、属性に正しいデータ型が割り当てられていることです。
-
たとえば yes または no など 2 つの状態のみを持つ属性は、[バイナリ] とマークされている必要があります。
-
カテゴリを示すために数値または文字列が使用される属性は、[カテゴリ] とマークされている必要があります。
-
順序に意味を持つ数値が使用される属性は、[数値] としてマークされている必要があります。
-
スペースで区切られた単語からなる文字列が使用される属性は、[テキスト] としてマークされている必要があります。

-
-
このチュートリアルでは、Amazon ML がすべての属性のデータ型を正しく識別しているため、[Continue] (続行) を選択します。
次に、ターゲット属性を選択します。
ターゲットは、ML モデルが予測を学習する必要がある属性であることに注意してください。属性 [y] は、個々の顧客が過去にキャンペーンに加入しているかどうかを、1 (はい) または 0 (いいえ) で示します。
注記
データソースを ML モデルのトレーニングおよび評価に使用する場合にのみ、ターゲット属性を選択してください。
[y] 属性をターゲット属性として選択するには
-
テーブルの右下で、単一の矢印を選択してテーブルの最後のページに進みます。ここで、[
y] 属性が表示されます。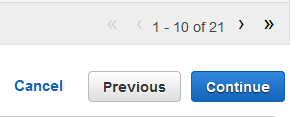
-
[ターゲット] 列で [
y] を選択します。
Amazon ML は、ターゲットとして [y] が選択されていることを確認します。
-
[続行] をクリックしてください。
-
[行 ID] ページの、[データには識別子が含まれていますか?] で、デフォルトの [No] が選択されていることを確認します。
-
[レビュー] を選択し、[続行] を選択します。
トレーニングデータソースを作成したため、モデルの作成 の準備ができました。
