翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon MSK による Studio ノートブックの作成
このチュートリアルでは、Amazon MSK クラスターをソースとして使用する Studio ノートブックを作成する方法について説明します。
このチュートリアルには、次のセクションが含まれています。
Amazon MSK クラスターを設定する
このチュートリアルでは、プレーンテキストでアクセスできる Amazon MSK クラスターが必要です。Amazon MSK クラスターをまだセットアップしていない場合は、「Amazon MSK の使用入門」チュートリアルに従って、Amazon VPC、Amazon MSK クラスター、トピック、および Amazon EC2 クライアントインスタンスを作成してください。
チュートリアルを実行するときは、以下の手順を実行します。
「ステップ 3: Amazon MSK クラスターを作成する」のステップ 4 で、
ClientBroker値をTLSからPLAINTEXTに変更します。
VPC に NAT ゲートウェイを追加する
「Amazon MSK の使用入門」チュートリアルに従って Amazon MSK クラスターを作成した場合、または既存の Amazon VPC にプライベートサブネット用の NAT ゲートウェイがまだない場合は、Amazon VPC に NAT ゲートウェイを追加する必要があります。アーキテクチャを次の図に示します。
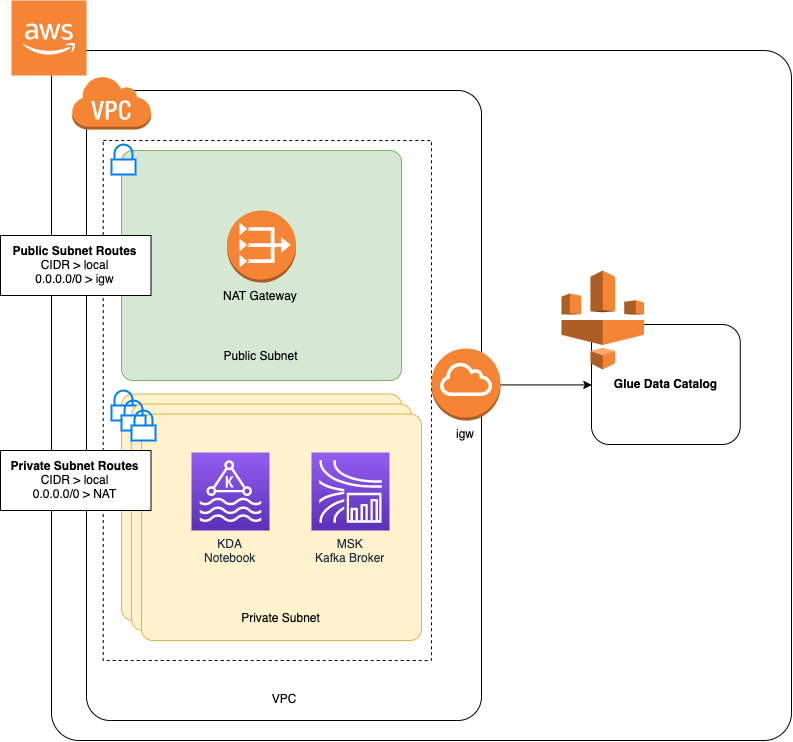
Amazon VPC 用の NAT ゲートウェイを作成するには、次の操作を行います。
Amazon VPC コンソールの https://console.aws.amazon.com/vpc/
を開いてください。 左のナビゲーションバーから、[NAT ゲートウェイ] を選択します。
「NAT ゲートウェイ」ページで「NAT ゲートウェイの作成」を選択します。
[NAT ゲートウェイの作成] ページで、以下の値を入力します。
名前 - オプション ZeppelinGatewayサブネット AWS KafkaTutorialSubnet1 Elastic IP 割り当て ID Choose an available Elastic IP. If there are no Elastic IPs available, choose Elastic IP の割り当て, and then choose the Elasic IP that the console creates. [Create NAT Gateway] (NAT ゲートウェイの作成) を選択します。
左のナビゲーションバーで、[ルートテーブル ] を選択します。
[ルートテーブルの作成] を選択します。
[ルートテーブルの作成] ページで、以下の情報を指定します。
名前タグ:
ZeppelinRouteTable「VPC」: 自分の VPC (例:「AWS KafkaTutorialVPC」)を選択します。
[作成] を選択します。
ルートテーブルのリストから「ZeppelinRouteTable」を選択します。[ルート] タブを選択し、[ルート編集] を選択します。
[ルートの編集] ページで、[ルートの追加] を選択します。
[送信先] に「
0.0.0.0/0」と入力します。「Target」には「NAT ゲートウェイ」、「ZeppelinGateway」。[ルートの保存] を選択します。[閉じる] を選択してください。「ルートテーブル」ページで「ZeppelinRouteTable」を選択した状態で、「サブネット関連付け」タブを選択します。「サブネット関連付けの編集」を選択します。
「サブネット関連付けの編集」ページで、「AWS KafkaTutorialSubnet2」と「AWS KafkaTutorialSubnet3」を選択します。[保存] を選択します。
AWS Glue 接続とテーブルを作成する
Studio ノートブックは、Amazon MSK データソースに関するメタデータ用の「AWS Glue」データベースを使用します。このセクションでは、Amazon MSK クラスターへのアクセス方法を説明する AWS Glue 接続と、データソース内のデータを Studio ノートブックなどのクライアントに提示する方法を説明する AWS Glue テーブルを作成します。
接続を作成する
にサインイン AWS Management Console し、https://console.aws.amazon.com/glue/
で AWS Glue コンソールを開きます。 AWS Glue データベースがまだない場合は、左側のナビゲーションバーからデータベースを選択します。[データベースの追加] を選択します。[データベースの追加] ウィンドウで、[データベース名] に
defaultを入力します。[作成] を選択します。左のナビゲーションバーから、[接続]を選択します。[接続の追加] を選択します。
「接続を追加」ウィンドウで、次の値を入力します。
[接続名] に、
ZeppelinConnectionと入力します。[接続タイプ] で、[Kafka] を選択します。
「Kafka ブートストラップサーバー URL」には、クラスターのブートストラップブローカーの文字列を指定します。ブートストラップブローカーは、MSK コンソールから、または次の CLI コマンドを入力して取得できます。
aws kafka get-bootstrap-brokers --region us-east-1 --cluster-arnClusterArn「SSL 接続が必要」チェックボックスをオフにします。
[次へ] を選択します。
[VPC] ページで、次の値を入力します。
VPC の場合は、VPC の名前 ( AWS KafkaTutorialVPC など) を選択します。
「サブネット」には、「AWS KafkaTutorialSubnet2」を選択します。
「セキュリティグループ」では、使用可能なすべてのグループを選択します。
[次へ] を選択します。
「接続プロパティ」/「接続アクセス」ページで 「完了」を選択します。
テーブルを作成する
注記
次の手順で説明するように手動でテーブルを作成することも、Apache Zeppelin 内のノートブックにある Apache Flink 用 Managed Service のテーブル作成コネクタコードを使用して DDL ステートメントでテーブルを作成することもできます。その後、チェックイン AWS Glue してテーブルが正しく作成されたことを確認できます。
左のナビゲーションバーで、[テーブル] を選択します。「テーブル」ページで、「テーブルを追加」、「テーブルを手動で追加」を選択します。
「テーブルのプロパティの設定」ページで、「テーブル名」に
stockを入力します。以前に作成したデータベースを選択していることを確認してください。[次へ] を選択します。「データストアの追加」ページで「Kafka」を選択します。トピック名には、「トピック名」 (「AWS KafkaTutorialTopic」など) を入力します。「接続」には「ZeppelinConnection」を選択します。
「分類」ページで「JSON」を選択します。[次へ] を選択します。
スキーマを定義するで、[Add column] を編集して列を追加します。以下のプロパティを持つ列を追加します。
[列名] データ型 tickerstring料金double[次へ] を選択します。
次のページで設定を確認し、「終了」を選択します。
-
テーブルの一覧で、新しく作成したテーブルを選択します。
-
[テーブルを編集] を選択し、次のプロパティを追加します。
-
キー:
managed-flink.proctime、値:proctime -
キー:
flink.properties.group.id、値:test-consumer-group -
キー:
flink.properties.auto.offset.reset、値:latest -
キー:
classification、値:json
これらのキーと値のペアがないと、Flink ノートブックにエラーが発生します。
-
-
[Apply] (適用) を選択します。
Amazon MSK による Studio ノートブックの作成
アプリケーションで使用するリソースを作成したので、次は Studio ノートブックを作成します。
または を使用してアプリケーションを作成できます AWS Management Console AWS CLI。
注記
Amazon MSK コンソールから既存のクラスターを選択し、「データをリアルタイムで処理」を選択することで Studio ノートブックを作成することもできます。
を使用して Studio ノートブックを作成する AWS Management Console
「https://console.aws.amazon.com/managed-flink/home?region=us-east-1#/applications/dashboard
」にある Apache Flink コンソール用 Managed Service を開きます。 「Apache Flink アプリケーション用 Managed Service」ページで、「Studio」タブを選択します。「Studio ノートブックの作成」を選択します。
注記
Amazon MSK または Kinesis Data Streams コンソールから Studio ノートブックを作成するには、入力の Amazon MSK クラスターまたは Kinesis データストリームを選択し、「データをリアルタイムで処理」を選択します。
[Studio ノートブックの作成] ページで、次の情報を入力します。
-
「Studio ノートブック名」に
MyNotebookを入力します。 「AWS Glue データベース」の「デフォルト」を選択します。
「Studio ノートブックの作成」を選択します。
-
「MyNotebook」ページで、「構成」タブを選択します。「Networking」セクションで、「編集」を選択します。
「MyNotebook のネットワークの編集」ページで、「Amazon MSK クラスターに基づく VPC 設定」を選択します。「Amazon MSK クラスター」には Amazon MSK クラスターを選択します。[Save changes] (変更の保存) をクリックします。
「MyNotebook」ページで、「実行」を選択します。「ステータス」に「実行中」が表示されるまで待ちます。
を使用して Studio ノートブックを作成する AWS CLI
を使用して Studio ノートブックを作成するには AWS CLI、以下を実行します。
次の情報があることを確認します。アプリケーションを作成するにはこれらの値が必要です。
アカウント ID。
Amazon MSK クラスターを含む Amazon VPC 用のサブネット ID やセキュリティグループ ID。
create.jsonというファイルを次の内容で作成します。プレースホルダー値を、ユーザー自身の情報に置き換えます。{ "ApplicationName": "MyNotebook", "RuntimeEnvironment": "ZEPPELIN-FLINK-3_0", "ApplicationMode": "INTERACTIVE", "ServiceExecutionRole": "arn:aws:iam::AccountID:role/ZeppelinRole", "ApplicationConfiguration": { "ApplicationSnapshotConfiguration": { "SnapshotsEnabled": false }, "VpcConfigurations": [ { "SubnetIds": [ "SubnetID 1", "SubnetID 2", "SubnetID 3" ], "SecurityGroupIds": [ "VPC Security Group ID" ] } ], "ZeppelinApplicationConfiguration": { "CatalogConfiguration": { "GlueDataCatalogConfiguration": { "DatabaseARN": "arn:aws:glue:us-east-1:AccountID:database/default" } } } } }アプリケーションを作成するには、次のコマンドを実行します。
aws kinesisanalyticsv2 create-application --cli-input-json file://create.jsonコマンドが完了すると、次のような出力が表示され、新しい Studio ノートブックの詳細が表示されます。
{ "ApplicationDetail": { "ApplicationARN": "arn:aws:kinesisanalyticsus-east-1:012345678901:application/MyNotebook", "ApplicationName": "MyNotebook", "RuntimeEnvironment": "ZEPPELIN-FLINK-3_0", "ApplicationMode": "INTERACTIVE", "ServiceExecutionRole": "arn:aws:iam::012345678901:role/ZeppelinRole", ...アプリケーションを起動するには、次のコマンドを実行します。サンプル値をアカウント ID に置き換えます。
aws kinesisanalyticsv2 start-application --application-arn arn:aws:kinesisanalyticsus-east-1:012345678901:application/MyNotebook\
Amazon MSK クラスターにデータを送信します。
このセクションでは、Amazon EC2 クライアントで Python スクリプトを実行して Amazon MSK データソースにデータを送信します。
Amazon EC2 クライアントに接続します。
以下のコマンドを実行して Python バージョン 3、Pip、および Kafka for Python パッケージをインストールし、アクションを確認します。
sudo yum install python37 curl -O https://bootstrap.pypa.io/get-pip.py python3 get-pip.py --user pip install kafka-python次のコマンドを入力して、クライアントマシン AWS CLI で を設定します。
aws configureアカウントの認証情報と
us-east-1をregionに入力します。stock.pyというファイルを次の内容で作成します。サンプル値を Amazon MSK クラスターのブートストラップブローカー文字列に置き換え、トピックが「AWS KafkaTutorialTopic」でない場合はトピック名を更新します。from kafka import KafkaProducer import json import random from datetime import datetime BROKERS = "<<Bootstrap Broker List>>" producer = KafkaProducer( bootstrap_servers=BROKERS, value_serializer=lambda v: json.dumps(v).encode('utf-8'), retry_backoff_ms=500, request_timeout_ms=20000, security_protocol='PLAINTEXT') def getStock(): data = {} now = datetime.now() str_now = now.strftime("%Y-%m-%d %H:%M:%S") data['event_time'] = str_now data['ticker'] = random.choice(['AAPL', 'AMZN', 'MSFT', 'INTC', 'TBV']) price = random.random() * 100 data['price'] = round(price, 2) return data while True: data =getStock() # print(data) try: future = producer.send("AWSKafkaTutorialTopic", value=data) producer.flush() record_metadata = future.get(timeout=10) print("sent event to Kafka! topic {} partition {} offset {}".format(record_metadata.topic, record_metadata.partition, record_metadata.offset)) except Exception as e: print(e.with_traceback())次のコマンドを使用してスクリプトを実行します。
$ python3 stock.py以下のセクションを実行している間は、スクリプトを実行したままにしておきます。
Studio ノートブックをテストします。
このセクションでは、Studio ノートブックを使用して Amazon MSK クラスターのデータをクエリします。
「https://console.aws.amazon.com/managed-flink/home?region=us-east-1#/applications/dashboard
」にある Apache Flink 用 Managed Serviceコンソールを開きます。 [Apache Flink アプリケーション用 Managed Service] ページで、[Studio ノートブック] タブを選択します。「MyNotebook」を選択します。
「MyNotebook」ページで、[Apache Zeppelin で開く] を選択します。
新しいタブで Apache Zeppelin インターフェイスが開きます。
「Zeppelinへようこそ!」でページで「Zeppelinの新ノート」を選択します。
「Zeppelin Note」ページで、新しいノートに次のクエリを入力します。
%flink.ssql(type=update) select * from stock実行アイコンを選択します。
アプリケーションは Amazon MSK クラスターのデータを表示します。
アプリケーションの Apache Flink ダッシュボードを開いて運用状況を表示するには、「FLINK JOB」を選択します。Flink Dashboard の詳細については、「Managed Service for Apache Flink デベロッパーガイド」の「Apache Flink ダッシュボード」を参照してください。
Flink ストリーミング SQL クエリの他の例については、「Apache Flink ドキュメント
