翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
openCypher データのロード形式
openCypher CSV 形式を使用して openCypher データをロードするには、ノードとリレーションシップを別々のファイルで指定する必要があります。ローダーは、単一のロードジョブで、これらのノードファイルとリレーションシップファイルの複数のからロードできます。
各ロードコマンドは、ロードされる一連のファイルと同じAmazon Simple Storage Service バケットのパスプレフィックスを持つ必要があります。そのプレフィックスは始点パラメータで指定します。実際のファイル名と拡張子は重要ではありません。
Amazon Neptune では openCypher CSV 形式は RFC 4180 の CSV の仕様に従います。詳細については、Internet Engineering Task Force (IETF) ウェブサイトの、CSV ファイルの一般形式と MIME タイプ
注記
これらのファイルは、UTF-8 形式でエンコードする必要があります。
各ファイルには、システム列ヘッダーとプロパティ列ヘッダーの両方を含むカンマ区切りのヘッダー行があります。
openCypher データロードファイルのシステム列ヘッダー
特定のシステム列は、各ファイルに 1 回のみ表示できます。すべてのシステム列ヘッダーラベルで、大文字と小文字が区別されます。
openCypher ノードのロードファイルおよびリレーションシップロードファイルでは、必須および許可されるシステム列ヘッダーが異なります。
ノードファイル内のシステム列ヘッダー
-
:ID— (必須) ノードの ID。オプションの ID スペースを
:ID(のように、ノードID Space):ID列ヘッダーに追加できます。例は:ID(movies)です。このファイル内のノードを接続するリレーションシップをロードするときは、リレーションシップファイルの
:START_IDおよび/または:END_ID列で同じ ID スペースを使用します。ノード
:IDはオプションで、フォーム、property name:IDname:IDです。ノード ID は、現在および以前のロードのすべてのノードファイルで一意である必要があります。ID スペースを使用する場合、ノード ID は、現在のロードと以前のロードで同じ ID スペースを使用するすべてのノードファイルで一意である必要があります。
-
:LABEL— ノードのラベル。1 つのノードに複数のラベル値を使用する場合は、各ラベルをセミコロン (
;) で区切る必要があります。
リレーションシップファイル内のシステム列ヘッダー
-
:ID— リレーションシップの ID。これは、userProvidedEdgeIdsが true (デフォルト) である場合に必要ですが、userProvidedEdgeIdsがfalseの場合は無効となります。リレーションシップ ID は、現在および以前のロードのすべてのリレーションシップファイルで一意である必要があります。
-
:START_ID— (必須) このリレーションシップが始まるノードのノード ID。必要に応じて、ID スペースをフォーム
:START_ID(の開始 ID 列に関連付けることができます。開始ノード ID に割り当てられた ID スペースは、ノードファイル内のノードに割り当てられている ID スペースと一致する必要があります。ID Space) -
:END_ID— (必須) このリレーションシップが終了するノードのノード ID。必要に応じて、ID スペースをフォーム
:END_ID(の終了 ID 列に関連付けることができます。終了ノード ID に割り当てられた ID スペースは、ノードファイル内のノードに割り当てられた ID スペースと一致する必要があります。ID Space) -
:TYPE— リレーションシップのタイプ。リレーションシップには、単一タイプのみを含めることができます。
注記
一括ロードプロセスで重複するノードまたはリレーションシップ ID がどのように処理されるかについては、openCypher データをロードする を参照してください。
openCypher データロードファイルのプロパティ列ヘッダー
次の形式のプロパティ列ヘッダーを使用して、列が特定のプロパティの値を保持するように指定できます。
propertyname:type
列ヘッダーでは、スペース、カンマ、キャリッジリターン、改行文字は使用できません。そのため、プロパティ名にこれらの文字を使用することはできません。以下に示しているのは、タイプ Int の age という名前のプロパティの列ヘッダーの例です。
age:Int
列ヘッダーとして age:Int がある列は、すべての行に整数または空の値を含める必要があります。
Neptune openCypher データロードファイルのデータ型
-
BoolまたはBoolean— ブールフィールド。指定できる値はtrueとfalseです。true以外の値はfalseとして扱われます。 -
Byte—-128から127範囲内の整数。 -
Short—-32,768から32,767範囲内の整数。 -
Int—-2^31から2^31 - 1範囲内の整数。 -
Long—-2^63から2^63 - 1範囲内の整数。 -
Float— 32 ビット IEEE 754 浮動小数点数。十進表記と科学記法の両方がサポートされています。Infinity、-InfinityおよびNaNはすべて認識されますが、INFはされません。桁数が多すぎて収まらない値は、最も近い値に丸められます (中間の値は、ビットレベルの最後の残りの桁で 0 に丸められます)。
-
Double— 64 ビット IEEE 754 浮動小数点数。十進表記と科学記法の両方がサポートされています。Infinity、-InfinityおよびNaNはすべて認識されますが、INFはされません。桁数が多すぎて収まらない値は、最も近い値に丸められます (中間の値は、ビットレベルの最後の残りの桁で 0 に丸められます)。
-
String- 引用符はオプションです。カンマ、改行、およびキャリッジリターン文字は、"Hello, World"のような二重引用符 (") で囲まれた文字列に含まれると自動的にエスケープされます。引用符で囲まれた文字列に引用符を含めるには、
"Hello ""World"""のように、行内で 2 つ使用してください。 -
DateTime— 次のいずれかの ISO-8601 形式の Java 日付。yyyy-MM-ddyyyy-MM-ddTHH:mmyyyy-MM-ddTHH:mm:ssyyyy-MM-ddTHH:mm:ssZ
Neptune openCypher データロードファイルのオートキャストデータ型
オートキャストデータ型は、現在 Neptune がネイティブにサポートしていないデータ型をロードするために提供されます。このような列のデータは文字列として保存され、意図した形式に対する検証は行われません。次のオートキャストデータ型を使用できます。
-
Char—Charフィールド。文字列として格納されます。 -
Date、LocalDateおよびLocalDateTime、 —date、localdateおよびlocaldatetimeタイプの説明については、Neo4j 一時的インスタントを参照してください。値は、検証なしで文字列として逐語的にロードされます。 -
Duration— Neo4j デュレーション形式を参照してください。値は、検証なしで文字列として逐語的にロードされます。 -
ポイント — 空間データを格納するためのポイントフィールド。「空間インスタント
」を参照してください。値は、検証なしで文字列として逐語的にロードされます。
openCypher ロードフォーマットの例
次の図では、TinkerPop 最新グラフから取得した 2 つの頂点と、リレーションシップの例を示しています。
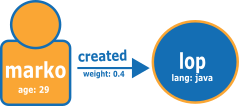
以下に示しているのは、通常の Neptune openCypher ロード形式のグラフです。
ノードファイル:
:ID,name:String,age:Int,lang:String,:LABEL v1,"marko",29,,person v2,"lop",,"java",software
リレーションシップファイル:
:ID,:START_ID,:END_ID,:TYPE,weight:Double e1,v1,v2,created,0.4
または、次のようにプロパティとして ID スペースと ID を使用することもできます。
最初のノードファイル:
name:ID(person),age:Int,lang:String,:LABEL "marko",29,,person
2 番目のノードファイル:
name:ID(software),age:Int,lang:String,:LABEL "lop",,"java",software
リレーションシップファイル:
:ID,:START_ID(person),:END_ID(software),:TYPE,weight:Double e1,"marko","lop",created,0.4
