翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Neptune の開始方法
Amazon Neptune はフルマネージド型のグラフデータベースサービスで、数十億のリレーションシップを処理するように拡張でき、ミリ秒のレイテンシーでクエリを実行でき、容量の規模の割には低コストでクエリを実行できます。
Neptune に関するより詳細な情報については、「Amazon Neptune の機能の概要」を参照してください。
グラフについてすでにわかっている場合は、 CloudShell を使用したクイックスタートまたは に進みますグラフノートブックでの Neptune の使用。または、Neptune データベースをすぐに作成する場合は、「を使用した Amazon Neptune クラスターの作成 AWS CloudFormation」を参照してください。
それ以外の場合は、開始する前にグラフデータベースについてもう少し知りたい場合があります。
グラフデータベースの主要な概念
グラフデータベースは、データ項目間の関係を格納し照会するために最適化されています。
データ項目自体をグラフの頂点として、それらの間の関係はエッジとして格納します。各エッジにはタイプがあり、ある頂点 (始点) から別の頂点 (終点) に向けられます。関係はエッジだけでなく述語とも呼ばれ、頂点はノードと呼ばれることもあります。いわゆるプロパティグラフでは、頂点とエッジの両方がそれらに関連付けられた追加のプロパティを持つことができます。
ソーシャルネットワーク内の友達や趣味を表す小さなグラフを次に示します。
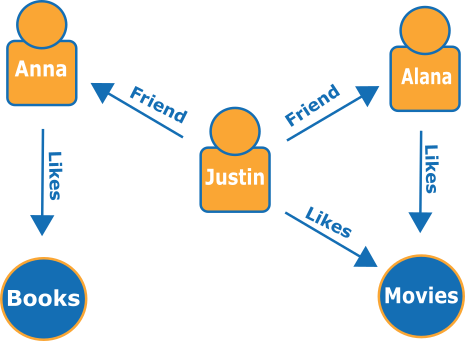
エッジは名前の付いた矢印で表示され、頂点はつながりのある特定の人物や趣味を表します。
このグラフの単純な探索により、Justin の友だちについて知ることができます。
グラフデータベースを使用する理由
モデル化するデータの核となるのがエンティティ同士のつながりまたは関係性である場合は、グラフデータベースが適しています。
1 つは、データ相互接続をグラフとしてモデル化し、グラフから実世界の情報を抽出する複雑なクエリを簡単に作成すできます。
リレーショナルデータベースを使用して同等のアプリケーションを構築するには、複数の外部キーを持つテーブルを多数作成し、ネストされた SQL クエリと複雑な結合を記述する必要があります。このアプローチは、コーディングの観点からすぐに扱いにくくなるだけでなく、データ量が増えるにつれてパフォーマンスが急速に低下します。
対照的に、Neptune のようなグラフデータベースは、非常に多くの頂点間の関係を乱すことなく照会できます。
グラフデータベースでできること
グラフは、アクション、所有権、親子関係、購入の選択、個人的なつながり、家族の関係などの観点から、現実世界のエンティティの相互関係をさまざまな方法で表すことができます。
グラフデータベースが使用される最も一般的な領域を次に示します。
-
ナレッジグラフ - ナレッジグラフを使用すると、接続されているあらゆる種類の情報を整理して照会し、一般的な質問に答えることができます。ナレッジグラフを使用して、トピック情報を製品カタログに追加したり、Wikidata
に含まれるのような多様な情報をモデル化したりできます。 ナレッジグラフがどのように機能し、使用されているかについては、AWSについてのナレッジグラフ
を参照してください。 -
アイデンティティグラフ - グラフデータベースでは、顧客の興味、友人、購入履歴のような情報カテゴリの間の関係をグラフに保存し、データを照会して、パーソナライズされた関連性のある推奨事項を作成できます。
たとえば、高可用性のグラフデータベースを使用して、同じスポーツをフォローしている他のユーザーや、購入履歴が似ている他のユーザーが購入した製品に基づいて、ユーザーに製品の推奨を行うことができます。または、共通の友人がいて、お互いはまだ知り合っていない人物を特定し、友人関係の推奨を行うことができます。
この種のグラフはアイデンティティグラフと呼ばれ、ユーザーとのインタラクションをパーソナライズするために広く使用されています。詳細については、AWSについてのアイデンティティグラフ
を参照してください。独自のアイデンティティグラフの作成を開始するには、まず Amazon Neptune を使用したアイデンティティグラフ サンプルから始められます。 -
不正グラフ — これは、グラフデータベースの一般的な使用法です。これらは、クレジットカードの購入と購入場所を追跡して、特徴的でない使用を検出したり、購入者が既知の不正行為で使用したのと同じメールアドレスとクレジットカードを使用しようとしていることを検出するのに役立ちます。これにより、1 つの個人用 E メールアドレスに関連付けられている複数の人物、同じ IP アドレスを共有する異なる物理的な場所にいる複数の人物を確認することができます。
次のグラフについて考慮します。3 名の人物と ID 関連の情報の関係が示されています。それぞれの人物に、住所、銀行口座、および社会保障番号があります。ただし、Matt および Justin は同じ社会保障番号を共有していることがわかります。これは異常なことで、このうち1 人が不正を行っている可能性を示唆しています。不正グラフへのクエリでは、この種のつながりを明らかにし、レビューできます。
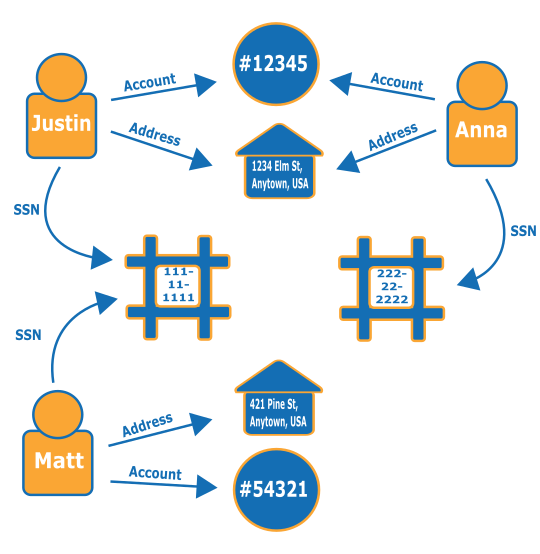
不正グラフがどのように機能し、使用されているかについては、AWSについての不正グラフ
を参照してください。 -
ソーシャルネットワーキング — グラフデータベースが使用される最初の最も一般的な領域の 1 つは、ソーシャルネットワーキングアプリケーションです。
たとえば、ウェブサイトにソーシャルフィードを構築するとします。バックエンドのグラフデータベースを使用して、家族、友人、アップデートに「いいね」した人、近くに住む人々からの最新のアップデートの反映結果をユーザーに提供できます。
ルート案内 — グラフは、現在の道路状況と一般的な混雑パターンを考慮して、始点から目的地までの最適なルートを見つけるのに役立ちます。
ロジスティクス – グラフは、お客様の要件を満たすために利用可能な出荷および配送リソースを使用する最も効率的な方法を特定するのに役立ちます。
診断機能 — グラフは、観測された問題や障害の原因を特定するために照会できる複雑な診断ツリーを表すことができます。
科学研究 – グラフデータベースでは、保存時の暗号化を使用して、科学データと機密医療情報を保存およびナビゲートするアプリケーションを構築できます。たとえば、疾患と遺伝子の相互関係モデルを保存できます。タンパク質の経路内でグラフパターンを検索して、疾患と関連する可能性がある他の遺伝子を見つけることができます。化学物質をグラフとしてモデル化し、分子構造のパターンに対してクエリを実行できます。さまざまなシステムで医療記録の患者データを関連付けることができます。題目別に研究出版物を整理して関連する情報をすばやく見つけることができます。
規制 - 複雑な規制要件をグラフとして保存し、それらを照会して、日常業務に適用される可能性のある状況を検出できます。
-
ネットワークトポロジとイベント – グラフデータベースは、IT ネットワークの管理と保護に役立ちます。ネットワークトポロジをグラフとして保存すると、ネットワーク上でさまざまな種類のイベントを保存して処理することもできます。特定のアプリケーションを実行しているホストの数などの質問に答えることができます。特定のホストが悪意のあるプログラムによって侵害された可能性を示すパターンを照会し、そのホストをダウンロードした元のホストのプログラムのトレースに役立つ接続データを照会できます。
グラフのクエリはどのように行いますか?
Neptune は、さまざまな種類のグラフデータをクエリするために設計された 3 つの特殊用途のクエリ言語をサポートしています。これらの言語を使用して、Neptune グラフデータベース内のデータを追加、変更、削除、およびクエリできます。
-
Gremlin は、プロパティグラフのグラフトラバーサル言語です。Gremlin のクエリは個別のステップで構成されたトラバーサルで、各ステップはエッジからノードに従います。詳細については、Apache TinkerPop
の Gremlin ドキュメントを参照してください。 Gremlin の Neptune 実装は、特に Gremlin-Groovy (シリアル化されたテキストとして送信される Gremlin クエリ) を使用している場合、他の実装とはいくつかの相違点があります。詳細については、「Amazon Neptune の Gremlin 標準への準拠」を参照してください。
-
openCypher – openCypher は、プロパティグラフの宣言型クエリ言語です。当初は Neo4jが 開発し、その後2015年にオープンソース化され、Apache 2 オープンソースライセンスの下で openCypher
プロジェクトで活用されました。言語仕様については、Cypher クエリ言語リファレンス (バージョン 9) を、さらに詳細については、Cypher スタイルガイド をご覧ください。 -
SPARQL は、RDF
データ用の宣言型クエリ言語です。World Wide Web Consortium (W3C) により標準化され、「SPARQL 1.1 概要 」と SPARQL 1.1 クエリ言語 」仕様で記述されているグラフパターンマッチングに基づいています。SPARQL の Neptune 実装に関する具体的な詳細については、「Amazon Neptune の SPARQL 標準準拠」を参照してください。
合致する Gremlin および SPARQL クエリの例
人物 (ノード) とその関係 (エッジ) の以下のグラフが与えられると、特定の人物の「友達の友達」 (Howard の友達の友達など) が誰かを調べることができます。
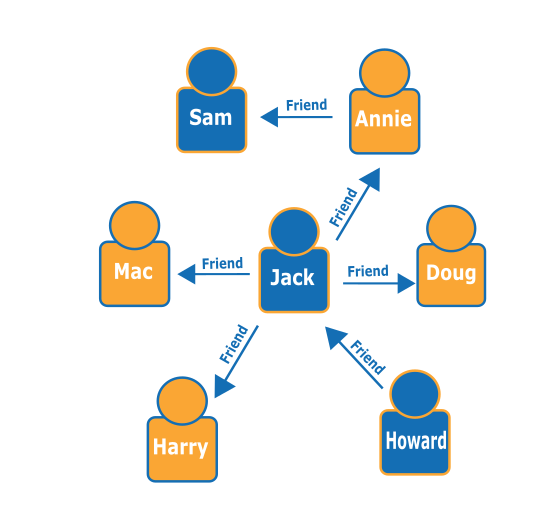
グラフを見ると、Howard には Jack という 1 人の友達がいて、Jack には Annie、Harry、Doug および Mac という 4 人の友達がいることがわかります。これは簡単なグラフを使用した単純な例ですが、これらのタイプのクエリは複雑性、データセット、および結果のサイズにおいてスケーリングできます。
以下は、Howard の友達の友達の名前を返す Gremlin トラバーサルクエリです。
g.V().has('name', 'Howard').out('friend').out('friend').values('name')
以下は、Howard の友達の友達の名前を返す SPARQL クエリです。
prefix : <#> select ?names where { ?howard :name "Howard" . ?howard :friend/:friend/:name ?names . }
注記
リソース記述フレームワーク (RDF) トリプルの各要素には、それに関連付けられた URI があります。↑の例では、URI プレフィックスは意図的に短くしています。
Amazon Neptune の使用に関するオンラインコースを受講する
動画による学習が好きな場合、 AWS はAWS オンラインテックトーク
Amazon Neptune によるグラフデータベースの紹介、詳細説明、デモ
グラフのリファレンスアーキテクチャを深く掘り下げる
グラフデータベースが解決できる問題と、それにどのようにアプローチするかについて考えるとき、まず最初に取り掛かるものの 1 つは、Neptune グラフリファレンスアーキテクチャ GitHub プロジェクト
ここでは、グラフワークロードタイプの詳細な説明と、効果的なグラフデータベースの設計に役立つ 3 つのセクションがあります。
データモデルとクエリ言語
— このセクションでは、Gremlin と SPARQL の違いと、どちらを選ぶかについて説明します。 グラフデータモデリング
— これは、Gremlin を使用したプロパティグラフモデリングや、SPARQL を使用したRDFモデリングの詳細なウォークスルーなど、グラフデータモデリングの決定方法に関して徹底的に説明しています。 他のデータモデルをグラフモデルに変換する
— ここでは、リレーショナルデータモデルをグラフモデルに変換する方法について説明します。
また、Neptune を使用するための具体的な手順を説明する 3 つのセクションがあります。
Neptune VPC 外のクライアントから Amazon Neptune に接続する
— このセクションでは、DB クラスターがある VPC の外部から Neptune に接続するためのいくつかのオプションを示します。 AWS Lambda 関数から Amazon Neptune にアクセスする
– Lambda 関数から Neptune に確実に接続する方法を説明します。 Amazon Kinesis データストリームから Amazon Neptune に書き込む
— このセクションは、Neptune で高い書き込みスループットシナリオを処理するのに役立ちます。
