翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
explainおよびprofileを使用した Gremlin クエリのチューニング
多くの場合、Amazon Neptune で Gremlin クエリを調整してパフォーマンスを向上させることができますAPIs。 Neptune explainAPIでの Gremlin の使用 Neptune profileAPIの Gremlinそうすることで、Neptune が Gremlin トラバーサルをどのように処理するのかを理解するのに役立ちます。
重要
TinkerPop バージョン 3.4.11 で変更が行われ、クエリの処理方法の正確性が向上しましたが、現時点ではクエリのパフォーマンスに重大な影響を与えることがあります。
たとえば、この種類のクエリの実行速度が大幅に遅くなる可能性があります。
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). out()
制限ステップ後の頂点は、 TinkerPop 3.4.11 変更の最適ではない方法でフェッチされるようになりました。これを回避するには、barrier() ステップを order().by() の次の任意のポイントに追加して、クエリを変更できます。例:
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). barrier(). out()
Neptune エンジンバージョン 1.0.5.0 で TinkerPop 3.4.11 が有効になっていました。
Neptune の Gremlin トラバーサル処理について理解する
Gremlin トラバーサルが Neptune に送信されると、トラバーサルをエンジンが実行するための基礎となる実行計画に変換する 主要なプロセスが 3 つあります。パーシング、変換、最適化です。
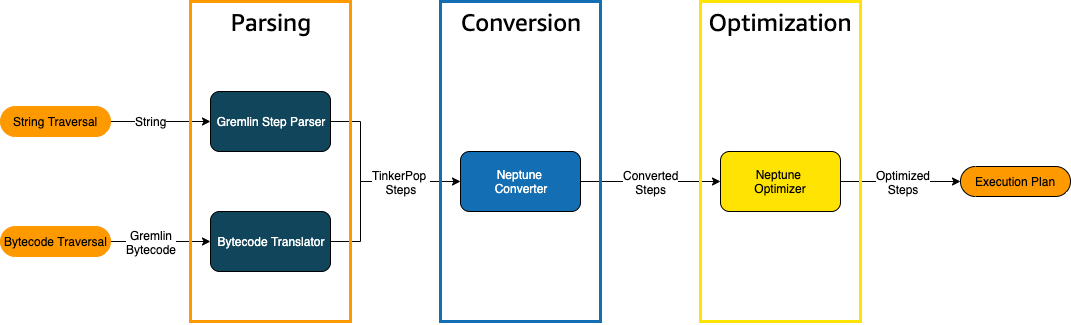
トラバーサル解析プロセス
トラバーサルを処理する最初のステップは、それを共通言語に解析することです。Neptune では、その共通言語は の一部である一連の TinkerPop ステップですTinkerPopAPI
Gremlin トラバーサルを文字列またはバイトコードとしてNeptune に送信できます。REST エンドポイントと Java クライアントドライバーsubmit()メソッドは、次の例のように、トラバーサルを文字列として送信します。
client.submit("g.V()")
Gremlin 言語バリアント (GLV) を使用するアプリケーションと言語
トラバーサル変換プロセス
トラバーサルを処理するための 2 番目のステップは、その TinkerPop ステップを変換された Neptune ステップと変換されていない Neptune ステップのセットに変換することです。Apache TinkerPop Gremlin クエリ言語のほとんどのステップは、基盤となる Neptune エンジンで実行されるように最適化された Neptune 固有のステップに変換されます。Neptune と同等のステップのない TinkerPop ステップがトラバーサルで発生した場合、そのステップとトラバーサル内の後続のすべてのステップは TinkerPop クエリエンジンによって処理されます。
どのような状況でどのようなステップが変換できるかの詳細については、Gremlin ステップサポートを参照してください。
トラバーサル最適化プロセス
トラバーサル処理の最後のステップは、オプティマイザを介して変換されたステップと未変換の一連のステップを実行し、最適な実行プランを決定することです。この最適化の出力は、Neptune エンジンが処理する実行計画です。
Neptune Gremlin explainAPIを使用したクエリの調整
Neptune の説明APIは Gremlin explain() ステップとは異なります。これは、クエリの実行時に Neptune エンジンが処理する最終実行プランを返します。処理を実行しないため、使用されるパラメータに関係なく同じプランが返され、実際の実行に関する統計が出力に含まれません。
アンカレッジのすべての空港の頂点を見つける次の単純なトラバーサルを考えます。
g.V().has('code','ANC')
Neptune を介してこのトラバーサルを実行する方法は 2 explain つありますAPI。最初の方法は、次のように、説明エンドポイントをREST呼び出すことです。
curl -X POST https://your-neptune-endpoint:port/gremlin/explain -d '{"gremlin":"g.V().has('code','ANC')"}'
2 番目は、explain パラメータで Neptune ワークベンチの %%gremlin セルマジックを使う方法です。これにより、セル本文に含まれるトラバーサルが Neptune に渡されexplainAPI、セルの実行時に結果の出力が表示されます。
%%gremlin explain g.V().has('code','ANC')
結果のexplainAPI出力は、トラバーサルに対する Neptune の実行計画を記述します。次の図に示すように、計画には、処理パイプラインに次の 3 つの各ステップが含まれています。
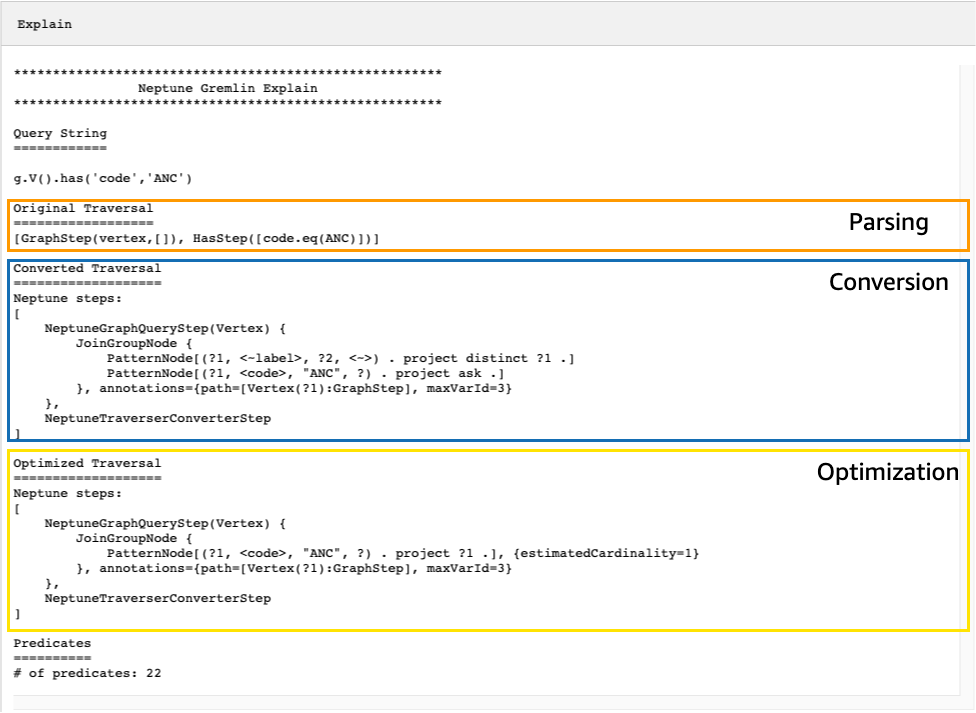
変換されないステップを見てトラバーサルを調整する。
Neptune explainAPI出力で最初に探すべきことの 1 つは、Neptune ネイティブステップに変換されない Gremlin ステップ用です。クエリプランで、Neptune ネイティブステップに変換できないステップが検出されると、そのステップと計画内の後続のすべてのステップが Gremlin サーバーによって処理されます。
上記の例では、トラバーサル内のすべてのステップが変換されました。このトラバーサルのexplainAPI出力を調べてみましょう。
g.V().has('code','ANC').out().choose(hasLabel('airport'), values('code'), constant('Not an airport'))
下の画像でわかるように、Neptune は choose() ステップを変換できませんでした。
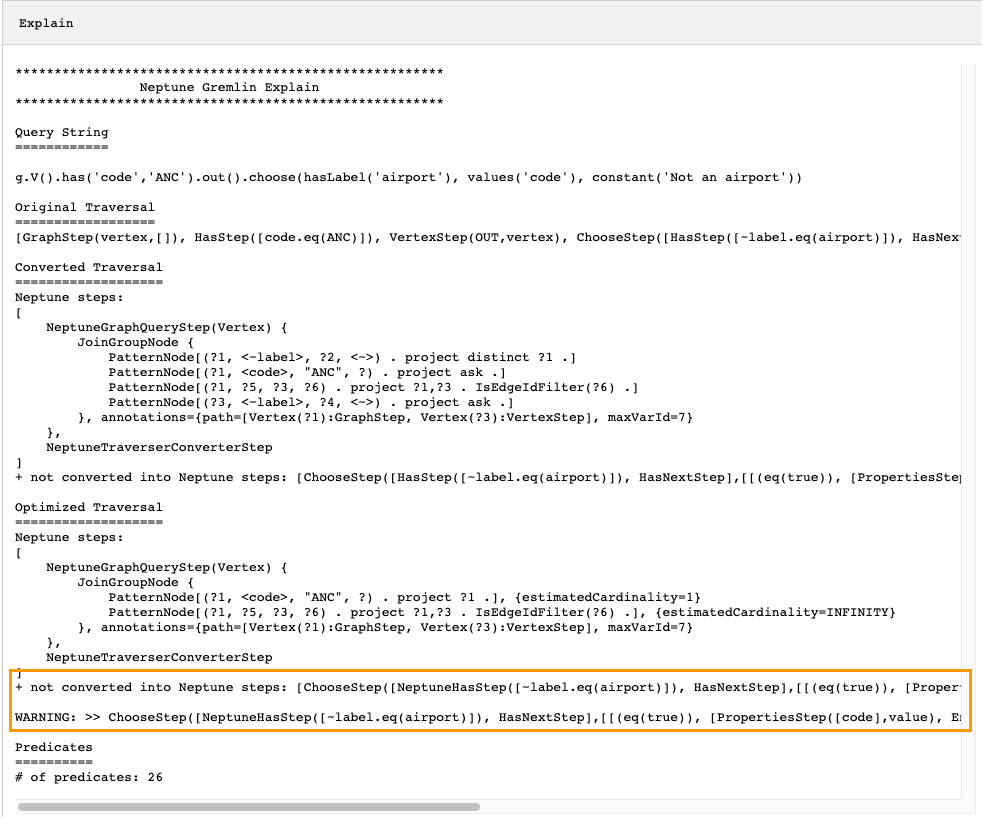
トラバーサルのパフォーマンスを調整するには、いくつかの方法があります。最初の方法では、変換できなかったステップを排除するような方法で書き直します。もう 1 つの方法では、ステップをトラバーサルの最後に移動して、他のすべてのステップをネイティブステップに変換できるようにします。
変換されないステップを含むクエリプランは、常に調整する必要はありません。変換できないステップがトラバーサルの終わりにあり、グラフのトラバース方法ではなく出力のフォーマットに関連している場合、パフォーマンスにはほとんど影響しません。
Neptune からの出力を調べる際に注意すべきもう 1 つのことは、インデックスを使用しないステップexplainAPIです。次のトラバーサルは、アンカレッジに着陸するフライトがあるすべての空港を検索します。
g.V().has('code','ANC').in().values('code')
このトラバーサルAPIの説明からの出力は次のとおりです。
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in().values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=INFINITY} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26 WARNING: reverse traversal with no edge label(s) - .in() / .both() may impact query performance
出力の下部にある WARNING メッセージが発生するのは、トラバーサルの in() ステップは、Neptune が維持する 3 つのインデックスのいずれかを使用して処理することができないからです (Neptune でステートメントのインデックスを作成する方法 および Neptune の Gremlin ステートメント を参照)。in() ステップにはエッジフィルターが含まれていないため、SPOG、POGSまたはGPSO インデックスを使って解決できないのです。代わりに、Neptune は要求された頂点を見つけるためにユニオンスキャンを実行しなければならず、これは非常に非効率です。
この状況において、トラバーサルを調整するには、2 つの方法があります。1 つ目は、インデックス付きルックアップを使用してクエリを解決できるように、1 つ以上のフィルタ条件を in() ステップに追加します。上記の例で、次のようになります。
g.V().has('code','ANC').in('route').values('code')
改訂されたトラバーサルexplainAPIの Neptune からの出力には、次のWARNINGメッセージが含まれなくなりました。
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in('route').values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,[route],vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . ContainsFilter(?5 in (<route>)) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5=<route>, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=32042} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26
この種のトラバーサルを多数実行している場合に取る方法は、有効なオプショナル OSGP インデックスを持つ Neptune DB クラスターでそれらを実行することです (OSGP インデックスの有効化 を参照)。OSGP インデックスの有効化には欠点があります。
データをロードする前に、DB クラスターで有効にする必要があります。
頂点とエッジの挿入速度が最大 23% 遅くなる場合があります。
ストレージ使用量は約 20% 増加します。
すべてのインデックスにリクエストを分散する読み取りクエリでは、レイテンシーが増加する可能性があります。
OSGP インデックスがあることは、制限された一連のクエリパターンに対して非常に意味がありますが、それらを頻繁に実行しない限り、3 つのプライマリインデックスを使用して記述するトラバーサルを確実に解決できるようにすることをお勧めします。
多数の述語を使用する
Neptune は、グラフ内の各エッジラベルと各個別の頂点またはエッジプロパティ名を述語として扱い、デフォルトで異なる述語の数が比較的少なくなるように設計されています。グラフデータに数千を超える述語が含まれていると、パフォーマンスが低下する可能性があります。
次のような場合は、Neptune explain 出力によって警告が表示されます。
Predicates ========== # of predicates: 9549 WARNING: high predicate count (# of distinct property names and edge labels)
ラベルとプロパティの数、これにしたがった述語数を減らすためにデータモデルを再加工するのが容易でない場合、トラバーサルを調整する最良の方法は、上で説明したように、有効化した OSGP インデックスを持つ DB クラスタ内でこれらを実行することです。
Neptune Gremlin profileAPIを使用したトラバーサルの調整
Neptune profileAPIは Gremlin profile() ステップとは大きく異なります。と同様にexplainAPI、その出力には、Neptune エンジンがトラバーサルの実行時に使用するクエリプランが含まれます。また、profile 出力には、パラメーターの設定方法に基づいて、トラバーサルの実際の実行統計が含まれます。
アンカレッジのすべての空港の頂点を見つける次の単純なトラバーサルを考えます。
g.V().has('code','ANC')
と同様にexplainAPI、 REST コールprofileAPIを使用して を呼び出すことができます。
curl -X POST https://your-neptune-endpoint:port/gremlin/profile -d '{"gremlin":"g.V().has('code','ANC')"}'
2番目は、profile パラメータで Neptune ワークベンチの %%gremlin セルマジックを使う方法です。これにより、セル本文に含まれるトラバーサルが Neptune に渡されprofileAPI、セルの実行時に結果の出力が表示されます。
%%gremlin profile g.V().has('code','ANC')
結果のprofileAPI出力には、このイメージでわかるように、トラバーサルに対する Neptune の実行計画と、計画の実行に関する統計の両方が含まれます。
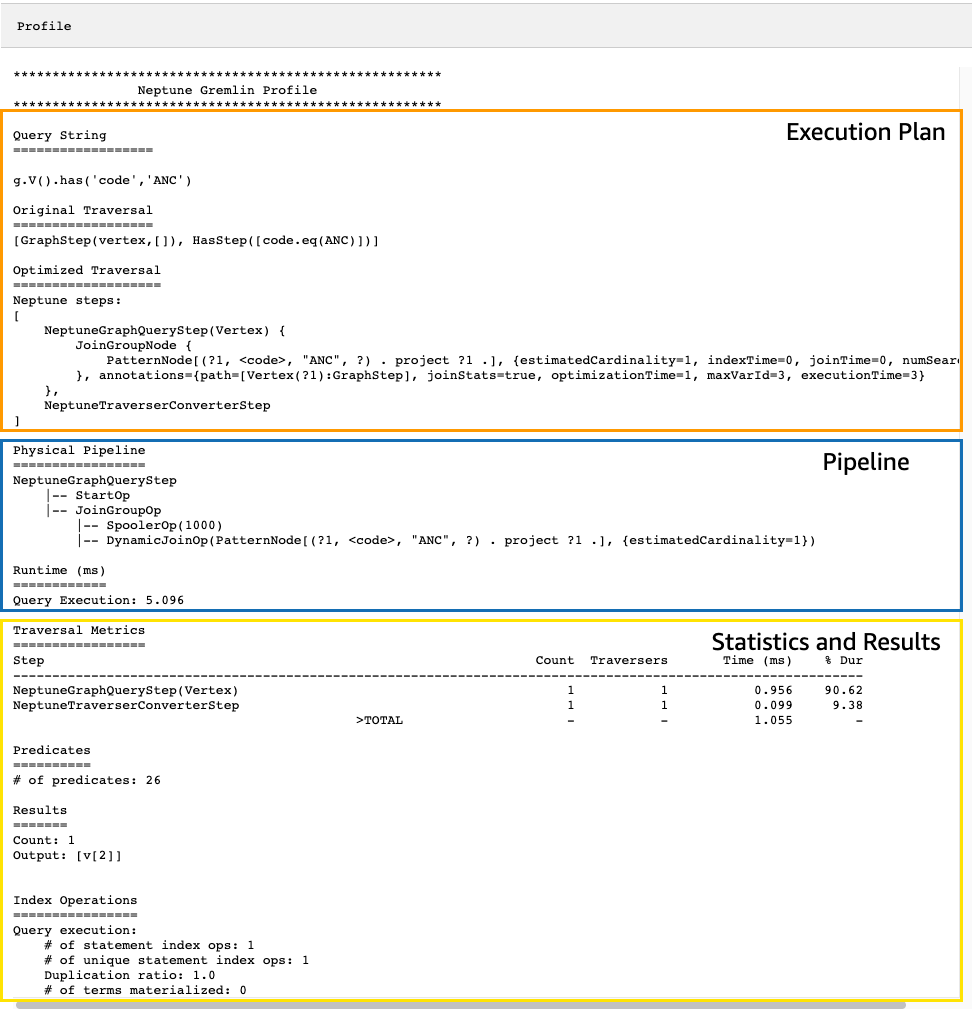
profile 出力の場合、実行計画セクションにはトラバーサルの最終実行計画のみが含まれ、中間ステップは含まれません。パイプラインセクションには、実行された物理パイプライン操作と、トラバーサル実行にかかった実際の時間 (ミリ秒単位) が含まれます。ランタイムメトリクスは、2 つの異なるバージョンのトラバーサルの最適化にかかる時間を比較する際に非常に役立ちます。
注記
トラバーサルの初期ランタイムは、通常、後続のランタイムよりも長くなります。これは、最初のランタイムによって関連するデータがキャッシュされるためです。
profile 出力の第 3 セクションには、実行統計とトラバーサルの結果が含まれます。この情報がトラバーサルのチューニングにどのように役立つかを確認するには、次のトラバーサルを検討してください。このトラバーサルでは、名前が「Anchora」で始まるすべての空港と、それらの空港から 2 回のホップで到達可能なすべての空港、戻り空港コード、飛行ルート、および距離が検索されます。
%%gremlin profile g.withSideEffect("Neptune#fts.endpoint", "{your-OpenSearch-endpoint-URL"). V().has("city", "Neptune#fts Anchora~"). repeat(outE('route').inV().simplePath()).times(2). project('Destination', 'Route'). by('code'). by(path().by('code').by('dist'))
Neptune profileAPI出力のトラバーサルメトリクス
すべての profile 出力で使用できる最初のメトリクスセットは、トラバーサルメトリクスです。これらは Gremlin profile() ステップメトリクスに似ていますが、いくつかの違いがあります。
Traversal Metrics ================= Step Count Traversers Time (ms) % Dur ------------------------------------------------------------------------------------------------------------- NeptuneGraphQueryStep(Vertex) 3856 3856 91.701 9.09 NeptuneTraverserConverterStep 3856 3856 38.787 3.84 ProjectStep([Destination, Route],[value(code), ... 3856 3856 878.786 87.07 PathStep([value(code), value(dist)]) 3856 3856 601.359 >TOTAL - - 1009.274 -
トラバーサルメトリクステーブルの最初の列には、トラバーサルによって実行されるステップがリストされます。最初の 2 つのステップは、一般に Neptune 固有のステップ NeptuneGraphQueryStep および NeptuneTraverserConverterStep です。
NeptuneGraphQueryStep は、Neptune エンジンによってネイティブに変換および実行できるトラバーサルの全体の実行時間を表します。
NeptuneTraverserConverterStep は、変換されたステップの出力を TinkerPop トラバーサーに変換するプロセスを表します。トラバーサーでは、変換できなかったステップがある場合は処理したり、 TinkerPop互換形式で結果を返したりすることができます。
上記の例では、いくつかの非変換ステップがあるため、これらの TinkerPop ステップ (ProjectStep、PathStep) はそれぞれテーブルに行として表示されます。
表の 2 番目の列はCount、ステップを通過したトラバーサーの数を報告し、3 番目の列はTraversers、TinkerPopプロファイルステップのドキュメント
この例では、3,856 個の頂点と 3,856 個のトラバーサーが NeptuneGraphQueryStep で返され、これらの数字は残りの処理を通して同じままです。これは ProjectStep および PathStep 結果をフィルタリングするのではなく、フォーマットしているからです。
注記
とは異なり TinkerPop、Neptune エンジンは、 NeptuneGraphQueryStepおよび NeptuneTraverserConverterStep ステップを一括してパフォーマンスを最適化しません。一括処理は、 TinkerPopトラバーサーを同じ頂点に組み合わせて運用オーバーヘッドを削減するオペレーションであり、これが Countと のTraversers数値の違いの原因です。一括処理は Neptune が に委任するステップでのみ発生するため TinkerPop、Neptune がネイティブに処理するステップでは発生しないため、 列Countと Traverser列はめったに異なります。
時間]列には、ステップが要したミリ秒数が報告され、% Dur 列には、ステップが要した合計処理時間の割合が報告されます。これらは、最も時間がかかったステップを示すことで、チューニング作業を集中させる場所を示すメトリクスです。
Neptune profileAPI出力のインデックスオペレーションメトリクス
Neptune プロファイルの出力内のメトリクスの別のセットAPIは、インデックスオペレーションです。
Index Operations ================ Query execution: # of statement index ops: 23191 # of unique statement index ops: 5960 Duplication ratio: 3.89 # of terms materialized: 0
次のレポート:
インデックスルックアップの合計数。
実行された一意のインデックスルックアップの数。
一意のインデックスルックアップに対する総インデックスルックアップの比率。比が低いほど、冗長性が低くなります。
用語辞書からマテリアライズされた用語の数。
Neptune profileAPI出力でメトリクスを繰り返す
トラバーサルが上記の例のように repeat() ステップを実行すると、リピートメトリックを含むセクションがprofile出力に表示されます。
Repeat Metrics ============== Iteration Visited Output Until Emit Next ------------------------------------------------------ 0 2 0 0 0 2 1 53 0 0 0 53 2 3856 3856 3856 0 0 ------------------------------------------------------ 3911 3856 3856 0 55
次のレポート:
行のループカウント (
Iteration列)。ループが訪問した要素の数 (
Visited列)。ループが出力した要素の数 (
Output列)。ループが出力した最後の要素 (
Until列)。ループが発した要素の数 (
Emit列)。ループから後続のループに渡される要素の数 (
Next列)。
これらのリピートメトリクスは、トラバーサルの分岐係数を理解し、データベースによって処理されている作業量を把握するのに非常に役立ちます。これらの数値を使用して、パフォーマンスの問題を診断できます。特に、同じトラバーサルが異なるパラメータで劇的に異なる場合です。
Neptune profileAPI出力のフルテキスト検索メトリクス
上記の例のように、トラバーサルが全文検索ルックアップを使用する場合、全文検索 (FTS) メトリクスを含むセクションがprofile出力に表示されます。
FTS Metrics ============== SearchNode[(idVar=?1, query=Anchora~, field=city) . project ?1 .], {endpoint=your-OpenSearch-endpoint-URL, incomingSolutionsThreshold=1000, estimatedCardinality=INFINITY, remoteCallTimeSummary=[total=65, avg=32.500000, max=37, min=28], remoteCallTime=65, remoteCalls=2, joinTime=0, indexTime=0, remoteResults=2} 2 result(s) produced from SearchNode above
これは ElasticSearch (ES) クラスターに送信されたクエリを示し、 とのインタラクションに関するいくつかのメトリクスを報告します。 ElasticSearch これにより、全文検索に関連するパフォーマンスの問題を特定できます。
-
ElasticSearch インデックスへの呼び出しに関する概要情報:
クエリを満たす remoteCalls ためにすべての が必要とするミリ秒の合計数 (
total)。() に費やされた平均ミリ秒数 remoteCall
avg。remoteCall () に費やされた最小ミリ秒数
min。remoteCall () で消費されたミリ秒の最大数
max。
が から ElasticSearch () remoteCalls まで消費した合計時間
remoteCallTime。() に対して remoteCalls 行われた の数 ElasticSearch
remoteCalls。ElasticSearch 結果の結合に費やされたミリ秒数 (
joinTime)。インデックスルックアップに費やされたミリ秒数 (
indexTime)。ElasticSearch () によって返された結果の合計数
remoteResults。
